













信息检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种强大的技术,能够显著提升大型语言模型的性能。RAG框架巧妙地结合了基于检索的系统和生成模型的优势,可以生成更加准确、符合上下文、实时更新的响应。随着对先进人工智能解决方案需求的不断增长,GitHub上涌现出众多开源RAG框架,每一个都提供了独特的功能和特性。
RAG框架的工作原理
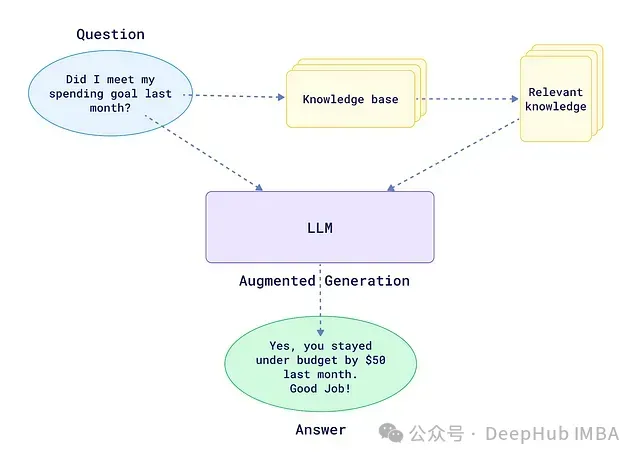
信息检索增强生成 (RAG)是一种创新的人工智能框架,它通过整合外部知识源来增强大型语言模型(LLM)的性能。RAG的核心理念是从知识库中检索与任务相关的信息,并将其用于扩充LLM的输入,从而使模型能够生成更加准确、与时俱进、符合上下文的响应。
这种方法有效地克服了LLM的一些固有局限性,如知识截止日期问题,同时也大大降低了模型输出产生幻觉(hallucination)的风险。通过将模型响应建立在已检索到的确切信息之上,RAG显著提高了LLM生成内容的可靠性和可解释性。
RAG与LangChain的区别
LangChain是一个功能强大的工具,用于构建LLM应用,但它并不能直接取代RAG。事实上,LangChain可以作为实现RAG系统的基础框架。以下是除了LangChain之外,你可能还需要RAG的几个主要原因:
融合外部知识:RAG允许你将特定领域或最新的信息无缝集成到LLM中,而这些信息可能并未包含在模型的原始训练数据内。
提高响应准确性:通过将模型响应建立在检索到的相关信息之上,RAG可以显著降低LLM输出中的错误率和幻觉现象。
支持定制化需求:RAG使你能够针对特定数据集或知识库对LLM进行微调,生成更符合具体应用场景的响应,这对许多商业应用至关重要。
提高过程透明度:RAG使我们能够更清晰地追踪LLM生成响应时所依赖的信息来源,大幅提升了模型行为的可审计性和可解释性。
总的来说,LangChain提供了构建LLM应用所需的各种工具和抽象,而RAG则是一种具体的技术,可以基于LangChain实现,用于进一步提升LLM输出的质量和可靠性。二者在构建先进的语言模型应用时可以形成优势互补,携手打造更加智能、稳健的对话交互系统。
GitHub上的十大RAG框架
本文重点介绍了目前在GitHub上可用的十大RAG框架。这些框架代表了RAG技术的最新发展成果,值得开发人员、研究人员和希望构建或优化人工智能驱动应用的组织深入探索,由于链接太多所以我们这里只包含名字,大家可以自行上Github搜索。
1、Haystack
GitHub Star数量: 14.6k
Haystack是一个功能丰富、灵活多变的框架,用于构建端到端的问答和搜索系统。它提供了一个模块化的架构,使开发人员能够轻松创建适用于各种NLP任务的工作流,包括文档检索、问答和文本摘要。Haystack的主要特性包括:
- 支持多种文档存储方案(如Elasticsearch、FAISS、SQL等)
- 与广泛使用的语言模型无缝集成(如BERT、RoBERTa、DPR等)
- 可扩展的架构,能够高效处理海量文档
- 简洁易用的API,便于构建自定义的NLP工作流
Haystack强大的功能和丰富的文档资源,使其成为初学者和有经验的开发人员构建RAG系统的绝佳选择。
2、RAGFlow
GitHub Star数量: 11.6k
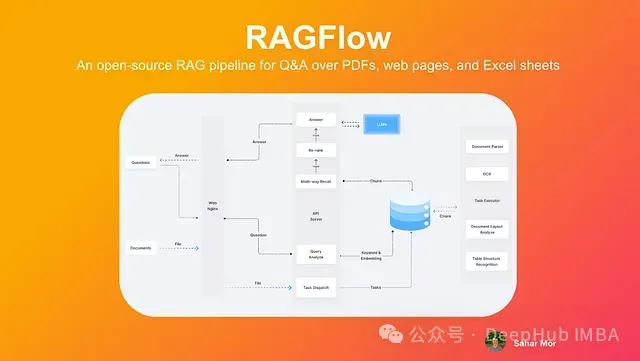
RAGFlow是RAG框架领域的一个后起之秀,凭借其简洁高效的设计理念迅速获得了广泛关注。该框架旨在通过提供一组预构建的组件和工作流,简化基于RAG的应用程序的开发过程。RAGFlow的主要特性包括:
- 直观的工作流设计界面
- 针对常见应用场景的预配置RAG工作流
- 与主流向量数据库的无缝集成
- 支持自定义嵌入模型
RAGFlow以用户友好的方式抽象了RAG系统的复杂性,使开发人员无需深入了解底层原理,即可快速构建和部署RAG应用,极大地提高了开发效率。
3、txtai
GitHub Star数量: 7.5k
txtai是一个功能丰富的人工智能数据处理平台,不仅仅局限于传统的RAG框架。它提供了一整套工具,用于构建语义搜索、语言模型工作流和文档处理流水线。txtai的核心功能包括:
- 用于高效相似性搜索的嵌入式数据库
- 方便集成语言模型和其他人工智能服务的API
- 支持自定义工作流的可扩展架构
- 多语言和多数据格式支持
txtai采用一体化设计,为需要在单一框架内实现多种人工智能功能的组织提供了极具吸引力的解决方案。
4、STORM
GitHub Star数量: 5k
STORM(Stanford Open-source RAG Model)是由斯坦福大学开发的面向学术研究的RAG框架。尽管其Star数量可能不及某些其他框架,但STORM依托顶尖高校的科研实力,专注于RAG技术的前沿探索,使其成为研究人员和开发者寻求创新灵感的宝贵资源。STORM的亮点包括:
- 实现了多项创新的RAG算法和技术
- 重点优化检索机制的准确性和效率
- 与最先进的语言模型深度集成
- 配套详尽的文档和研究论文
对于立志探索RAG技术前沿的学者和从业者而言,STORM以扎实的学术积淀为后盾,提供了一个可靠的研究基础和实践平台。
5、LLM-App
GitHub Stars: 3.4K
LLM-App是一个用于构建动态RAG应用程序的模板和工具集合。它以专注于实时数据同步和容器化部署而脱颖而出。LLM-App的主要特点包括:
- 可快速部署的即用型Docker容器
- 支持动态数据源和实时更新
- 与流行的LLM和向量数据库集成
- 各种RAG用例的可定制模板
LLM-App强调操作方面和实时能力,使其成为希望部署生产就绪RAG系统的组织的有吸引力的选择。
6、Cognita
GitHub Stars: 3k stars
Cognita是RAG框架领域中的新进入者,专注于提供一个统一的人工智能应用开发和部署平台。虽然它的星标数量比其他一些框架少,但其全面的方法和对MLOps原则的强调使其值得考虑。Cognita值得注意的特点包括:
- 端到端的RAG应用开发平台
- 与流行的ML框架和工具集成
- 内置的监控和可观察性功能
- 支持模型版本控制和实验跟踪
Cognita对人工智能应用开发采取整体方法,对希望简化其整个ML生命周期的组织来说是一个令人信服的选择。
7、R2R
GitHub Stars: 2.5k stars
R2R(Retrieval-to-Retrieval)是一个专门的RAG框架,专注于通过迭代细化来改进检索过程。虽然它可能有更少的星标,但其创新的检索方法使其成为一个值得关注的框架。R2R的主要特点包括:
- 实现新颖的检索算法
- 支持多步检索过程
- 与各种嵌入模型和向量存储集成
- 用于分析和可视化检索性能的工具
对于有兴趣突破检索技术界限的开发人员和研究人员来说,R2R提供了一套独特而强大的工具。
8、Neurite
GitHub Stars: 909 stars
Neurite是一个新兴的RAG框架,旨在简化构建人工智能驱动应用程序的过程。虽然与其他一些框架相比,它的用户基础较小,但其对开发者体验和快速原型构建的关注使其值得探索。Neurite值得注意的特点包括:
- 用于构建RAG管道的直观API
- 支持多种数据源和嵌入模型
- 内置缓存和优化机制
- 可扩展的自定义组件架构
Neurite强调简单性和灵活性,使其成为希望在其应用程序中快速实现RAG功能的开发人员的有吸引力的选择。
9、FlashRAG
GitHub Stars: 905 Stars

FlashRAG是一个由中国人民大学自然语言处理与信息检索实验室开发的轻量级高效RAG框架。尽管它Stars很少,但其对性能和效率的关注使其成为一个值得关注的竞争者。FlashRAG值得注意的方面包括:
- 经过优化的检索算法,提高速度
- 支持分布式处理和扩展
- 与流行的语言模型和向量存储集成
- 用于基准测试和性能分析的工具
对于速度和效率至关重要的应用程序,FlashRAG提供了一套专门的工具和优化。
10、Canopy
GitHub Stars: 923
Canopy是Pinecone开发的RAG框架,Pinecone是以其向量数据库技术而闻名的公司。它利用Pinecone在高效向量搜索方面的专业知识,提供强大且可扩展的RAG解决方案。Canopy值得注意的特点包括:
- 与Pinecone的向量数据库紧密集成
- 支持流式处理和实时更新
- 高级查询处理和重新排序功能
- 用于管理和版本控制知识库的工具
Canopy专注于可伸缩性和与Pinecone生态系统的集成,使其成为已经在使用或考虑使用Pinecone进行向量搜索需求的组织的绝佳选择。
总结
RAG框架正在快速发展,呈现出百花齐放的盛况。从功能全面、久经考验的Haystack,到专注领域创新的FlashRAG和R2R,各具特色的框架为不同需求和应用场景提供了优质的选择。在评估和选型RAG框架时,我们需要综合考虑以下因素:
- 项目的具体需求和约束
- 所需的定制化和灵活性
- 框架的可扩展性和性能表现
- 框架背后社区的活跃度和贡献度
- 文档和技术支持的完备性
通过系统评估并实际尝试不同的框架,我们可以找到最契合自身需求的RAG解决方案,用于构建更加智能、全面、有洞察力的人工智能应用。随着人工智能技术的不断进步,这些框架也必将持续演进,新的开源项目也将不断涌现。对于致力于将人工智能的力量应用于现实世界问题的开发者和研究人员而言,持续关注RAG领域的最新动向,将是保持技术领先的关键所在。






























