













本文经自动驾驶之心公众号授权转载,转载请联系出处。
引言
MambaBEV是一个专为自动驾驶系统设计的基于Mamba2的高效3D检测模型。该模型利用了鸟瞰图(BEV)范式,并整合了时序信息,同时提高了检测的稳定性和准确性。在nuScences数据集上,该模型具有出色的表现。

对于自动驾驶系统而言,更安全、准确地进行3D目标检测至关重要。历史上,这些感知系统主要依赖霍夫变换和关键点提取等技术构建基础框架。然而,深度学习的兴起使得感知精度的重大飞跃。
然而,单目相机的感知方法仍面临诸多挑战,尤其是距离感知误差大和盲区范围广,这些问题对驾驶安全构成了显著威胁。为了解决距离误差问题,研究人员提出了双目立体匹配技术,通过利用一对相机捕获图像之间的视差,在一定程度上改善了距离估计的准确性。然而,这些系统仍然存在关键的局限性:它们无法感知车辆侧面和后部的物体及车道标记,从而在自动驾驶系统的安全范围内留下空白。
为了应对这些局限性,最新的研究探索了使用环视相机系统进行感知,该系统通常包括六个相机。这种方法为每个相机输入部署独立的深度学习模型,并依赖后处理技术将各个输出整合为对环境的一致感知。尽管这种方法克服了单目和双目系统的局限性,但也引入了一系列新挑战,包括大量的GPU内存消耗、感知冗余、跨相机视图的目标重新识别,以及缺乏跨相机的信息交互。这些因素共同影响了感知系统的效率和有效性。

图1 MambaBEV的框架。

为了解决这些障碍,基于鸟瞰图(BEV)的范式作为一种有前景的解决方案应运而生。这种方法将多个相机的输入整合到一个统一的BEV表示中,从而使车辆周围环境的全面理解成为可能。通过直接将图像数据映射到环境的俯视图,BEV方法促进了更准确的距离估计和障碍物检测,同时有效解决了盲区问题。此外,这种方法还促进了不同相机视图之间的信息高效共享,从而增强了感知系统的整体鲁棒性和可靠性。
另一个关键方面是处理时序数据。单帧检测虽然简单,但常常因为帧间目标遮挡和特征不明显而错过检测。为了解决这些问题,整合时序融合技术,利用历史特征来增强当前特征,已被证明可以显著提高模型性能。然而,传统的时序融合范式主要依赖自注意力机制,导致高内存消耗、有限的全局感受野,以及较慢的训练和推理速度。因此,开发一种新的时序融合方法以克服这些缺点具有重要的工程意义。
最近,一个专门处理序列的新模型mamba在多个下游任务中展现出巨大的潜力。Mamba2是mamba的改进版本,在多个任务上显示了更优的性能。这种新方法采用基于块分解的矩阵乘法,并利用GPU的存储层次结构,从而提高了训练速度。将mamba2引入3D自动驾驶感知是一个值得探索的方向。为了解决时序融合模块面临的问题,作者提出了MambaBEV,这是一个基于BEV的3D感知模型,使用了mamba2。据作者所知,这是首次将Mamba2整合到基于相机的3D目标检测网络中。

作者提出了一种基于mamba2的3D目标检测范式,命名为MambaBEV。该方法采用了一个基于mamba-CNN的模块,名为TemporalMamba,用于融合不同帧中的BEV特征。此外,作者在解码器层设计了一种mamba-detr头部,以进一步优化检测效果。
A.预备知识
结构化状态空间模型(SSMs)是一类深度学习模型,特别适用于序列建模任务。通过利用这些结构化公式,SSMs在表达性与计算效率之间提供了一种权衡,成为与基于注意力的模型(如Transformer)的一种有效替代。SSMs的公式代表了推进深度学习中序列建模的一个有前景的方向。作者使用的基模型称为Mamba2,它基于结构化状态空间(S4)序列模型,这些模型根植于连续系统。这些模型通过采取1-D输入序列或函数和一个中间隐藏状态, ,如下所示:

它结合了一个可学习的步长,并采用零阶保持将连续系统转换为离散系统。注意,如果设置D为0,则可以忽略Du(t)。因此,方程(1)可以重写为:
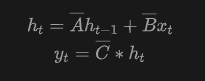
通过应用数学归纳法,的最终输出可以表示为:
其中M定义为:
表示从到的矩阵乘积,索引j和i分别表示第j个和第i个A,B,C矩阵。Mamba2中的变换矩阵M也符合N-序半可分离(SSS)表示的定义。因此,在Mamba2框架内,SSM和SSS的表示是等价的。这种等价性允许在涉及SSM的计算中高效利用结构化矩阵乘法进行SSS。为了实现这种方法,参数矩阵M被分解为对角块和低秩块,分别使用结构化掩码注意力(SMA)二次模式算法和SMA线性模式算法。此外,多头注意力(MHA)被集成以增强模型的性能。

图2 TemporalMamba的总体框架。
B.总体架构
MambaBEV的主要结构在图1中展示。该模型可以总结为四个主要模块:图像特征编码器、后向投影(SCA)、TemporalMamba和Mamba-DETR头部。MambaBEV以六个相机图像为输入,并通过图像特征编码器生成六个多尺度特征图。这些特征图随后被送入名为空间交叉注意力(SCA)的后向投影模块,以生成BEV特征图。
接下来,历史BEV特征与当前BEV特征进行融合,用于指导生成新的当前BEV特征。此过程由作者提出的TemporalMamba块执行。经过多层处理后,最终使用mamba-DETR头部作为3D目标检测的输出模块。
C. 图像特征编码器
图像特征编码器由两部分组成:高效的主干和经典的颈部。针对场景中不同视图的六张图片,作者使用在ImageNet上预训练的经典ResNet-50、从FCOS3D检查点初始化的ResNet-101-DCN,以及非常有效的VoV-99(同样来自FCOS3D检查点)作为主干,以提取每张图片的高级特征。Vmamba也可以作为主干。为了更好地提取特征并提升性能,作者采用经典的特征金字塔网络(FPN)生成多尺度特征。

图3 Query重组。
D. TemporalMamba块
对于传统的基于注意力的时序融合块,作者采用了可变形自注意力。Temporal Self-Attention(TSA)主要遵循以下流程:首先,给定历史BEV特征图和当前特征图,TSA将它们连接,并通过线性层生成注意力权重和偏移量。然后,每个查询(代表BEV特征)根据权重进行并行计算。然而,作者认为这种方法存在一些副作用。尽管可变形注意力可以降低计算成本,但由于每个参考查询仅允许与三个查询交互,导致大尺寸物体特征在跨帧交互中受到限制。
模型使用了mamba以增强全局交互能力。首先,两种模态的特征通过自我旋转角度进行变换,并通过一个卷积块将维度从512压缩到256,如图2所示。
在处理历史BEV特征图和当前特征图(每个维度为256)时,首先在第三维度将它们连接,连接后的特征分别经过两次带有批归一化的3x3卷积层和一次带有批归一化的1x1卷积层,然后将它们相加。
然后,作者对特征图Z进行离散重排,并通过mamba2块处理。典型的mamba2块是为自然语言处理设计的,旨在处理序列,但在应用于视觉数据时面临重大挑战。因此,设计合适的离散重排方法至关重要。基于实验并受到Vmamba的启发,作者设计了四种不同方向的重排方法,并讨论了这些方法在消融研究中的影响。
作者创新性地提出了一种多方向特征序列扫描机制,其中特征图Z被离散序列化,并以四个方向:向前左、向前上、向后左和向后上重新组合,如图3所示,形成新的序列作为Mamba2模型的输入。值得注意的是,作者没有采用蛇形螺旋重组合方法,因为他们认为这种方法会导致相邻特征之间的交互不平衡,一些相邻特征可能过于接近,而其他特征则相距甚远。mamba输出增强的序列特征,然后重新组合并恢复图4中显示的原始顺序。接着,作者计算四个张量的平均值,并将以0.9的dropout率生成的增强融合BEV特征图作为跳跃连接添加到当前BEV特征图中。

图4 Query融合。
E. Mamba-DETR头部
如图1所示,作者重新设计了一个结合mamba和传统DETR编码器的mamba-DETR头部。在此结构中,900个目标查询首先在mamba2块中进行预处理,并相互之间进行交互,承担与自注意力相同的职责。随后,mamba块的输出将像传统的CustomMSDeformableAttention那样,通过可变形注意力进行处理。

在实验中,MambaBEV在nuScenes数据集上表现出色,其基础版本实现了51.7%的NDS(nuScenes Detection Score)。此外,MambaBEV还在端到端自动驾驶范式中进行了测试,展现了良好的性能。在3D对象检测任务中,MambaBEV-base相较于仅使用单帧的BEVFormer-S,在mAP和NDS上分别提高了3.51%和5.97%,充分显示了TemporalMamba块的有效性。当添加TemporalMamba块时,平均速度误差降低了37%,表明历史信息,特别是经过TemporalMamba块处理的信息,可以显著改善速度估计,因为它提供了宝贵的历史位置信息。

表1 在nuScenes验证集上的3D目标检测结果。

表2 开环规划性能。

表3 动态预测。

表4 拼接方法与卷积方法的消融对比。

表5 不同窗口大小造成的影响。

表6 不同重排方法的比较

表7 BEV特征不同分辨率的影响

MambaBEV是一种基于BEV范式和mamba2结构的创新3D目标检测模型,充分利用时序信息以处理动态场景。在nuScenes数据集上实现51.7%的NDS,突出了其有效性和准确性。通过引入TemporalMamba块,MambaBEV有效整合历史信息,改善速度估计和目标检测性能。与传统卷积层和可变形自注意力相比,该模型在全局信息交换上更具优势,并且优化了计算成本。为适应端到端的自动驾驶范式,MambaBEV结合了mamba和传统DETR编码器的特性,展现出良好的潜力,尤其在自动驾驶应用中具有可观的发展前景。





















