今天我们介绍 YOLOv11,这个系列中的最新成员。YOLO 是一个在目标检测领域几乎无与伦比的算法,它产生了非常成功的结果。这个算法系列在 YOLOv5 之后由 Ultralytics 继续开发,并且每个新模型都带来了更好的性能。
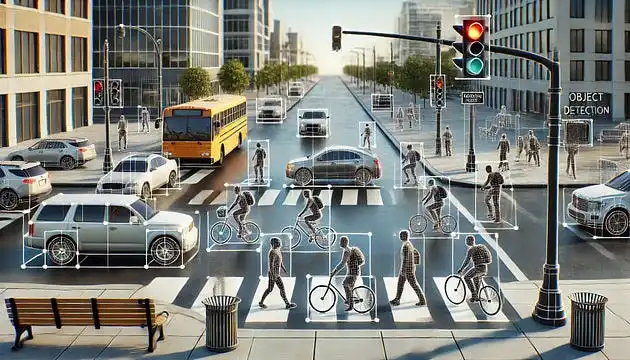
YOLOv11 是 Ultralytics 开发的最新 YOLO 模型。这个模型在执行实时目标检测时,继续平衡准确性和效率。在之前的 YOLO 版本基础上,YOLO11 在架构和训练上提供了显著的改进。在保持速度的同时提高性能的最重要的架构变化是增加了 C3K2 块、SPFF 模块和 C2PSA 块。
- C3K2 块:这是在以前版本中引入的 CSP(Cross Stage Partial)块的增强。该模块使用不同的核大小(例如 3x3 或 5x5)和通道分离策略来优化更复杂特征的提取。
- SPFF(Spatial Pyramid Pooling Fusion)模块:它是 YOLO 版本中使用的 SPP(Spatial Pyramid Pooling)模块的优化版本。该模块允许模型通过捕获不同尺度的物体属性来更好地执行。
- C2PSA 块:这个块通过结合通道和空间信息提供更有效的特征提取。它还与多头注意力机制一起工作,从而实现对物体更准确的感知。它优化了前一层的特征图,并用注意力机制丰富它们,以提高模型的性能。这种结构使得在复杂场景中更精确的检测成为可能,并提高了 YOLOv11 的准确性。
除了这些架构变化,YOLOv11 像 YOLOv8 一样具有多模型能力。得益于其多模型特性,YOLOv11 可以执行以下任务:
- 目标检测:在图像中识别和定位物体。
- 实例分割:检测物体并确定它们的边界。
- 分类:将图像分类到预定义的类别中。
- 姿态估计:检测和跟踪人体上的标志点。
- 定向目标检测(OBB):检测旋转物体以提高灵敏度。
在我们开始使用之前,让我们谈谈新 YOLO 版本带来的特性。
- 现有的主干结构已经被 C3K2 块替换,以提高特征提取能力。
- 颈部结构已经用 SPFF 模块改进,以捕获不同大小的物体并更好地检测小物体。
- 增加了 C2PSA 块,专注于更小或部分遮挡物体中的重要区域。
- 通过多模型能力增加了任务数量。
- 更容易适应各种环境,包括边缘设备。
- 得益于其优化的架构和高效的处理能力,它可以部署在边缘设备、云平台和支持 NVIDIA GPU 的系统上。
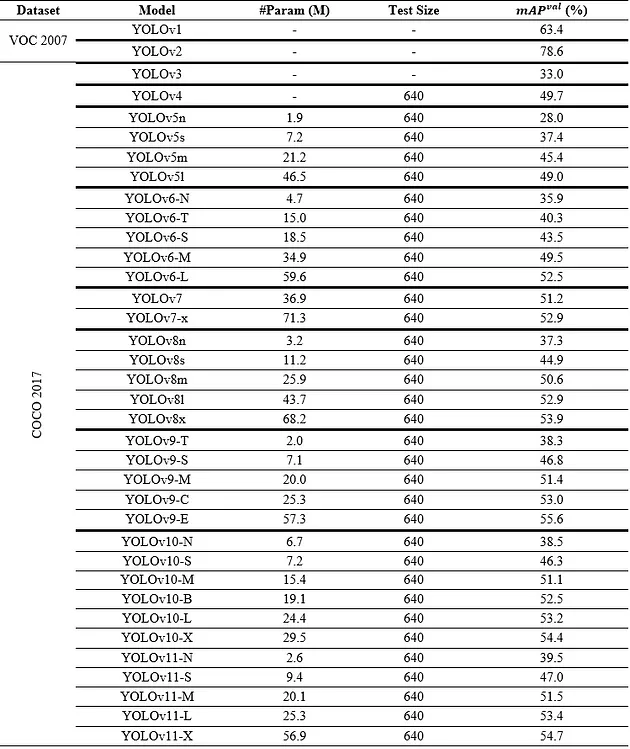
由于这些优化和创新,YOLOv11 在实时应用中提供了性能提升。模型运行更快、更准确,提高了目标检测、样本分割和姿态估计等任务的效率。此外,兼容性得到了改善,使模型可以轻松地在不同的平台和硬件上运行(例如云或边缘设备)。在 Ultralytics (详见官网:https://docs.ultralytics.com/models/yolo11/)页面上,当他们评估 YOLOv11 与以前版本相比的性能时,他们发表了以下评论。
随着模型设计的改进,YOLO11m 在使用比 YOLOv8m 少 22% 参数的情况下,在 COCO 数据集上实现了更高的平均精度均值(mAP),使其在不牺牲准确性的情况下具有计算效率。
然而,尽管 YOLOv11 模型的性能很好并且提供了广泛的范围,但在目标检测方面,它并不像 YOLOv10 那样成功。尽管 YOLOv10 有更多的参数,YOLOv11 只实现了微小的差异(+0.1-0.5)的更好性能。在这种情况下,YOLOv10 可能仍然是我们的偏好,因为参数的过剩导致速度损失和成本。
使用 YOLOv11
使用 PyTorch 构建 YOLOv11 模型及其与其他模式的使用简要如下。
步骤 1:首先,我们需要下载 Ultralytics 库。有了这个库,我们可以运行从 YOLOv3 到 YOLOv11 的所有模型。
pip install ultralytics步骤 2:如果你只想在一个训练好的模型中进行预测。以下代码就足够了。否则你可以跳过它。
yolo predict model=yolo11n.pt source='https://ultralytics.com/images/bus.jpg'py步骤 3:如果你说不,我想训练我的模型,你可以选择你想要的模型并下载 .pt 文件。
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")步骤 4:然后你需要选择训练数据、训练epoch、图像大小和你的设备。
train_results = model.train(
data="coco8.yaml", # path to dataset YAML
epochs=100, # number of training epochs
imgsz=640, # training image size
device="cpu", # device to run on, i.e. device=0 or device=0,1,2,3 or device=cpu
)步骤 5:你需要用验证数据评估和测试模型。它将验证数据从训练数据本身中分离出来,对于测试,你只需要提供你想要测试的图像的路径。
metrics = model.val()
results = model("path/to/image.jpg")
results[0].show()步骤 6:在最后一步,我们可以导出你的模型,以便以后再次使用。如果你想用你自己的模型进行预测,只需使用步骤-2。
path = model.export(format="onnx")YOLOv11 常用操作指令
用你自己的数据训练你的目标检测模型,具有特定的学习率和epoch:
yolo train data=coco8.yaml model=yolo11n.pt epochs=10 lr0=0.01对于模型验证:
yolo val model=yolo11n.pt data=coco8.yaml batch=1 imgsz=640在 YouTube 视频上测试模型的结果,图像大小为 320:
yolo predict model=yolo11n.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320使用预训练的分割模型在 YouTube 视频上预测,图像大小为 320:
yolo segment predict model=yolo11n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320将你特别训练的模型导出为 .pt 扩展名:
yolo export model=path/to/best.pt format=onnx