












该研究成果由来自北京大学的蔡少斐、王子豪、连可为、牟湛存、来自北京通用人工智能研究院的马晓健研究员、来自加州大学洛杉矶分校的刘安吉共同完成。通讯作者为北京大学助理教授梁一韬。所有作者均隶属 CraftJarvis 研究团队。
在游戏和机器人研究领域,让智能体在开放世界环境中实现有效的交互,一直是令人兴奋却困难重重的挑战。想象一下,智能体在《我的世界(Minecraft)》这样的环境中,不仅要识别和理解复杂的视觉信息,还需要利用鼠标和键盘精细地控制游戏画面,快速做出反应,完成像导航、采矿、建造、与生物互动等任务。面对如此庞大且复杂的交互空间,如何能让智能体能理解并执行人类的意图呢?

针对这个问题,CraftJarvis 团队提出利用 VLMs (视觉语言模型)强大的视觉语言推理能力来指导任务的完成,并创新地提出了一种基于视觉 - 时间上下文提示(Visual-Temporal Context Prompting)的任务表示方法。该方法允许人类或 VLMs 在当前和历史游戏画面中将希望进行交互的物体分割出来,来传达具体的交互意图。为了将交互意图映射为具体的鼠标键盘操作,该团队进一步训练了一个以物体分割为条件的底层策略 ROCKET-1。这种融合了视觉 - 时间上下文提示的智能体架构为开放世界的交互奠定了基础,预示了未来游戏 AI 和机器人互动的新可能性。

- 论文链接: https://arxiv.org/pdf/2410.17856
- 项目主页: https://craftjarvis.github.io/ROCKET-1
研究创新点
视觉 - 时间上下文提示方法

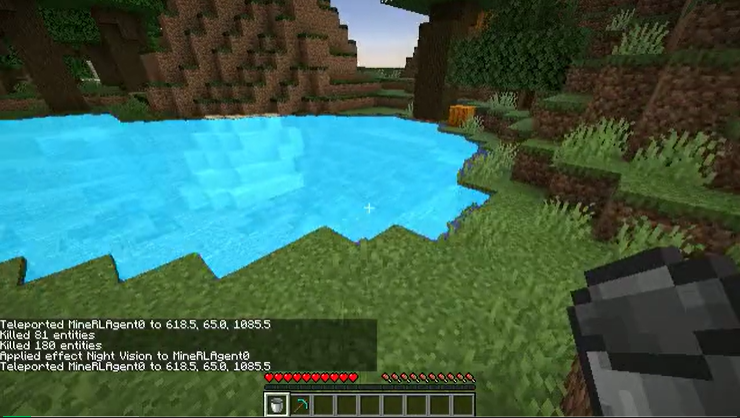
架构对比图;(e) 为基于视觉 - 时间上下文提示的新型架构
视觉 - 时间上下文提示是一种全新的任务表达方式。通过整合智能体过去和当前的观察信息,该方法利用物体分割信息,为智能体提供空间和交互类型的线索,从而让低级策略能够准确识别和理解环境中的关键对象。这一创新使得智能体能够在执行任务时始终保持对目标对象的关注。
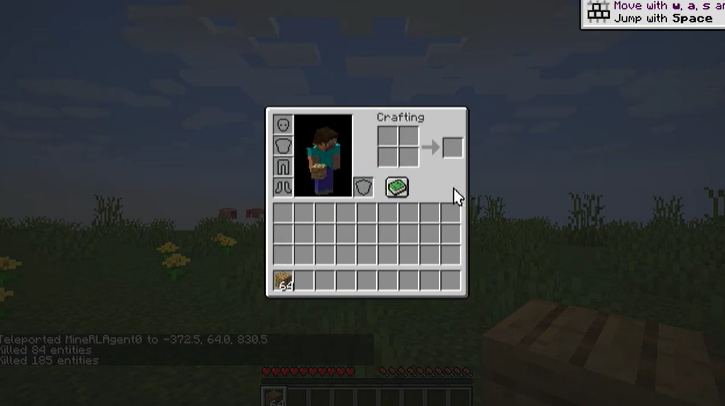
基于物体分割的条件策略 ROCKET-1

基于因果 Transformer 实现的 ROCKET-1 架构
ROCKET-1 是一种基于视觉 - 时间上下文的低级策略,能够在视觉观察和分割掩码的支持下预测行动。通过使用 Transformer 模块,ROCKET-1 可以在部分可观测(Partially Observable)环境中推理过去和当前观测的依赖关系,实现精准的动作预测。与传统方法不同,ROCKET-1 能够处理细微的空间和时序变化,并始终关注要进行交互的物体,显著提升了与环境交互的成功率。
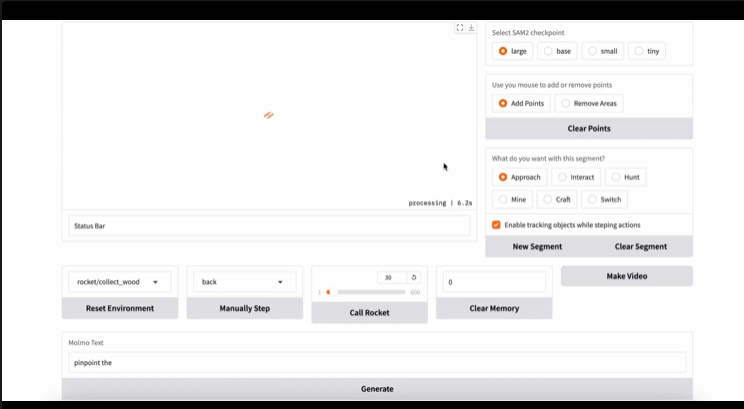
反向轨迹重标注策略

反向轨迹重标记流程示意
训练 ROCKET-1 需要收集大量带有物体分割的轨迹数据。传统的数据标注方法成本高、效率低,CraftJarvis 团队提出了一种逆向轨迹重标注方法,利用 SAM-2 的物体分割能力在倒放的视频中连续地对发生交互的物体生成分割注释。这种方法能够根据现有的交互事件重建数据集,使得 ROCKET-1 在离线条件下即可完成高效训练,减少了对人工标注的依赖,并为大规模数据处理提供了切实可行的解决方案。
充分释放预训练基础模型的能力

CraftJarvis 团队将具身决策所依赖的能力分解为视觉语言推理、视觉空间定位、物体追踪和实时动作预测,并巧妙地组合 GPT-4o、Molmo、SAM-2、ROCKET-1 加以解决。
为了应对复杂任务规划的挑战,该团队引入了 GPT-4o,目前最先进的视觉语言模型之一。可以进行强大的视觉语言推理,将复杂的任务分解为一系列具体的物体交互指令。此外,该团队采用了 Molmo 模型来将 GPT-4o 的交互意图翻译为观察图像中的坐标点,用以精确定位交互物体。
为了应对对象跟踪的挑战,该团队引入了 SAM-2,一个先进的视频分割模型。SAM-2 不仅能够通过点提示对物体进行分割,还可以在时间上连续追踪目标,即便物体在视野中消失或重新出现时也能有效保持跟踪。这为 ROCKET-1 提供了稳定的对象信息流,确保了在高频变化的环境中智能体的交互精度。
实验成果
为了验证 ROCKET-1 的交互能力,CraftJarvis 团队在《我的世界》中设计了一系列任务,包括采矿、放置物品、导航和与生物互动等。

《我的世界》交互任务评测集

ROCKET-1 评测结果
实验结果显示,ROCKET-1 在这些任务上,尤其在一些具有高空间敏感性的任务中,获得的成功率远高于现有方法(在多数任务上实现了高达 90% 的成功率提升),ROCKET-1 表现出了出色的泛化能力。即便在训练集中从未出现的任务(如将木门放到钻石块上),ROCKET-1 依然能够借助 SAM-2 的物体追踪能力完成指定目标,体现了其在未知场景中的适应性。
此外,该团队也设计了一些需要较为复杂的推理能力的长期任务,同样展示了这套方法的杰出性能。

ROCKET-1 在解决任务时的截图

需要依赖规划能力的长期任务性能结果
视觉 - 时间上下文方法的提出和 ROCKET-1 策略的开发不仅为 Minecraft 中的复杂任务带来了全新解决方案,也在通用机器人控制、通用视觉导航等领域展示了广泛的应用前景。




















