在数据处理领域,AWK 是一个强大而灵活的工具,尽管很多人对它感到陌生或畏惧。本文将通过实际案例,帮助你逐步掌握 AWK 的基本用法,让你在数据处理方面游刃有余。

案例1:使用awk提取文本
1.问题
本案例旨在通过运用awk工具实现以下目标:
- 熟练掌握awk工具的基础操作与语法。
- 从系统中提取关键信息,包括但不限于网络接口的流量数据、根文件系统的剩余空间容量,以及记录尝试通过SSH协议进行远程连接但未成功的IP地址列表。
- 对/etc/passwd文件中的内容进行处理,以结构化格式展示用户的登录名(用户名)、用户标识号(UID)及其主目录路径等信息。
2.解答
AWK是一种文本处理工具,能够读取输入行并根据指定模式进行操作。它的基本语法如下:
awk 'pattern { action }' filename在编辑指令中,print 是最常用的一个。当需要执行多条编辑指令时,可以使用分号进行分隔。此外,Awk 在过滤数据时支持仅输出特定列的数据,例如第二列或第五列等。在处理文本的过程中,如果没有明确指定字段分隔符,则默认情况下 awk 会将空格和制表符视为字段之间的分隔标志。
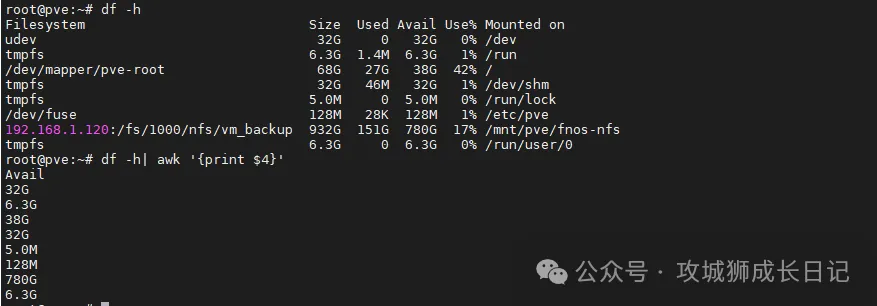
(1) 结合管道过滤获取每个分区的剩余容量信息
(2) 选项-F指定分隔符
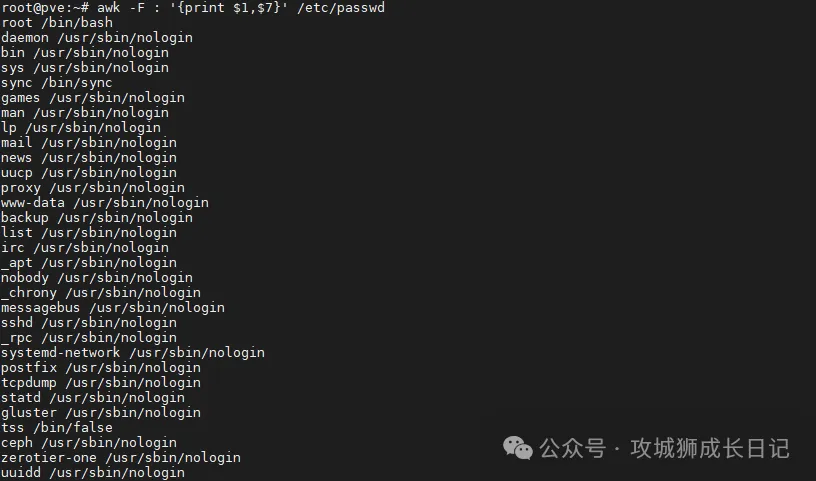
输出passwd文件中以分号分隔的第1、7个字段,显示的不同字段之间以逗号隔开,操作如下:
为了提取passwd文件中以分号分隔的第一和第七个字段,可以执行以下命令:
awk -F : '{print $1,$7}' /etc/passwd执行上述命令后,输出如下图的结果
awk常用内置变量:
- $1文本的第1列
- $2文件的第2列
- $3文件的第3列,依此类推
- NR 文件当前行的行号
- NF文件当前行的列数(有几列)
利用awk提取本机的网络流量、根分区剩余容量、获取远程失败的IP地址。
通过ifconfig eth0查看网卡信息,其中包括网卡流量:
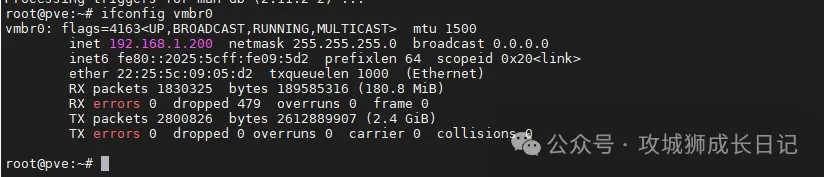
RX为接收的数据量,TX为发送的数据量。packets以数据包的数量为单位,bytes以字节为单位,为了直观把字节转成兆。
root@pve:~# ifconfig vmbr0 | awk '/RX packets/{print $5/1024/1024 " MB"}'
180.912 MB
root@pve:~# ifconfig vmbr0 | awk '/TX packets/{print $5/1024/1024 " MB"}'
2491.94 MB提取根分区剩余容量,通过df命令查看根分区的使用情况,其中包括剩余容量:
root@pve:~# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/pve-root 68G 27G 38G 42% /输出上述结果中最后一行的第4列:
root@pve:~# df -h / | tail -1 | awk '{print $4}'
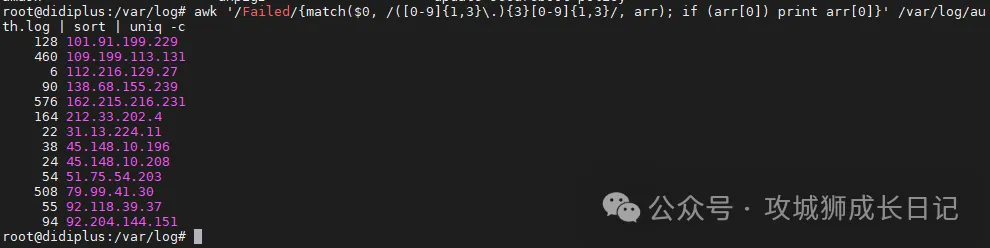
38G根据/var/log/auth.log日志文件,通过正则方式进行过滤远程连接密码失败的IP地址,并统计,执行如下命令:
awk '/Failed/{match($0, /([0-9]{1,3}\.){3}[0-9]{1,3}/, arr); if (arr[0]) print arr[0]}' \
/var/log/auth.log | sort | uniq -c执行上述命令后,输出如下结果:
案例2:awk处理条件
1.问题
在本案例中,需运用awk工具执行以下过滤任务。请特别注意awk处理条件的设定:
- 提取并展示用户ID(UID)位于1至1000范围内的所有用户的详细信息。
- 从/etc/hosts文件中筛选出以127或192开头的所有记录行。
- 构建一个列表,包含100以内所有是7的倍数或者数字本身含有7的所有整数。
2.解答
(1) 使用正则设置条件
输出其中以bash结尾的完整记录:
root@didiplus:~# awk -F: '/bash$/{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash请筛选出那些登录Shell字段(即第七个字段)不以"nologin"结尾的用户记录,并展示这些用户的用户名及其对应的登录Shell信息。具体来说,可以采用对第七个字段进行反向匹配(!~)的方式来实现这一需求。
root@didiplus:~# awk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd
root /bin/bash
sync /bin/sync
pollinate /bin/false
tss /bin/false
lxd /bin/false
1panel /bin/sh(2) 使用数值/字符串比较设置条件
在Shell脚本中,常用的比较运算符包括:
整数比较:
- -lt:小于
- -le:小于或等于
- -eq:等于
- -ne:不等于
- -gt:大于
- -ge:大于或等于
字符串比较:
- ==:等于
- !=:不等于
- >:大于
- <:小于
- >=:大于或等于
- <=:小于或等于
这些运算符用于条件判断,以实现逻辑控制和流程管理。
输出第3行(行号NR等于3)的用户记录:
root@didiplus:~# awk -F: 'NR==3{print}' /etc/passwd
bin:x:2:2:bin:/bin:/usr/sbin/nologin输出账户UID大于等于1000的账户名称和UID信息:
root@didiplus:~# awk -F: '$3>=1000{print $1,$3}' /etc/passwd
nobody 65534
1panel 1000(3) 逻辑测试条件
输出账户UID大于10并且小于20的账户信息:
root@didiplus:~# awk -F: '$3>10 && $3<20' /etc/passwd
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin(4) 数学运算
统计3的倍数的数量
root@didiplus:~# seq 200 | awk '$1%3==0{i++} END{print i}'
66(5) 完成任务要求的awk过滤操
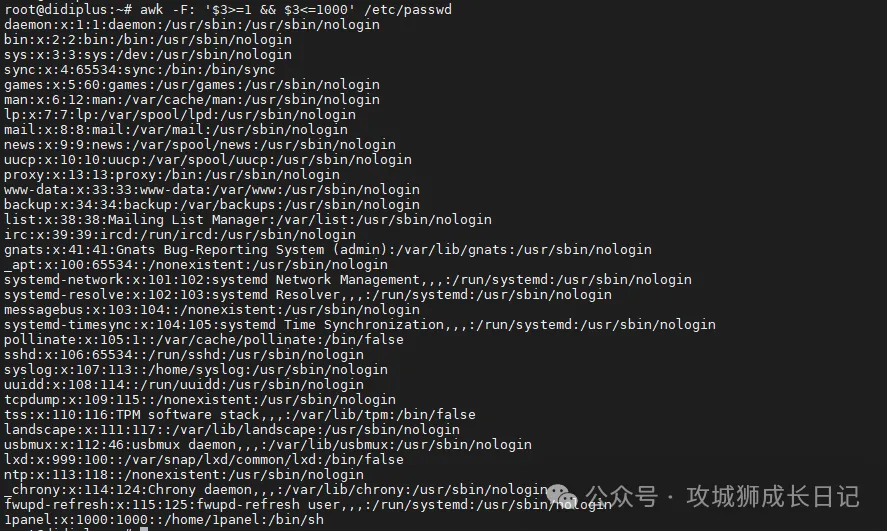
列出UID间于1~1000的用户详细信息:
awk -F: '$3>=1 && $3<=1000' /etc/passwd执行上述命令后,输出如下结果:
输出 /etc/hosts 映射文件内以127或者192开头的记录:
root@didiplus:~# awk -F: '/^(127|192)/' /etc/hosts
127.0.0.1 localhost
127.0.1.1 Aliyun列出100以内整数中7的倍数或是含7的数:
seq 100 | awk '$1%7==0||$1~/7/{print}'$1~/7/:这个条件使用正则表达式检查数字中是否包含字符“7”。如果是,条件为真。

案例3:awk综合脚本应用
1.问题
本案例要求开发一个名为 getupwd-awk.sh 的脚本,以满足以下功能需求:
- 识别并筛选出使用 bash 作为登录 Shell 的本地用户。
- 对于这些选定的用户,提取他们在 /etc/shadow 文件中的密码记录。
- 将结果格式化为“用户名 --> 密码记录”的形式,并按行保存至 getupwd.log 文件中。最终输出格式应如下图所示。

2.解答
根据需求编写getupwd-awk.sh,内容如下:
#!/bin/bash
# 定义输出文件
output_file="getupwd.log"
# 清空输出文件
> "$output_file"
# 获取使用 bash 作为登录 Shell 的本地用户
awk -F: '$7 == "/bin/bash" {print $1}' /etc/passwd | while read -r user; do
# 获取该用户的密码记录
passwd_record=$(sudo grep "^$user:" /etc/shadow)
# 如果找到了密码记录,格式化并输出
if [ -n "$passwd_record" ]; then
echo "$user --> $passwd_record" >> "$output_file"
fi
done
echo "密码记录已保存到 $output_file"案例4:awk扩展应用
1.问题
在解析Web日志文件时,首列显示了客户端的IP地址。由于存在大量重复的IP地址,仅用awk提取这些信息还不够,还需要统计每个IP地址出现的次数并对结果排序。
为此,可以使用awk创建一个关联数组,以IP地址为键值。每当遇到相同的IP地址时,对应的计数器加一,从而计算出每个IP地址的总出现次数。
对于排序结果,建议使用sort命令配合不同的参数来满足需求。例如,使用-n选项按数值升序排列,-r选项实现降序排列,而-k则允许根据特定字段排序。这一系列步骤有助于从原始日志中有效提取并展示有用的信息。
2.解答
统计Web访问量排名:
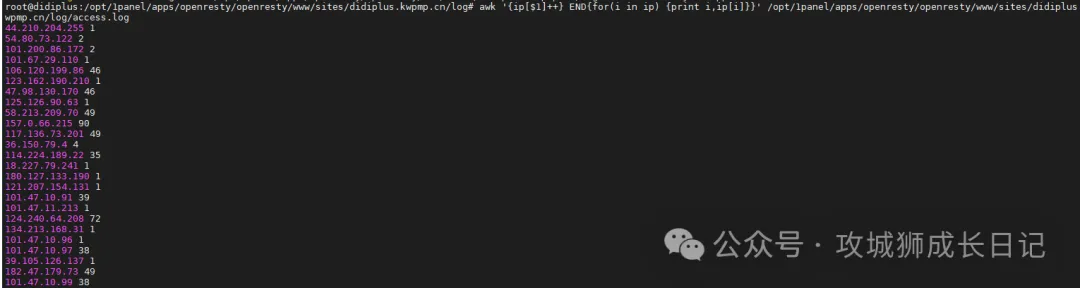
(1) 提取IP地址及访问量:
awk '{ip[$1]++} END{for(i in ip) {print i,ip[i]}}' \
/opt/1panel/apps/openresty/openresty/www/sites/didiplus.kwpmp.cn/log/access.log执行上述命令后,输出如下结果:
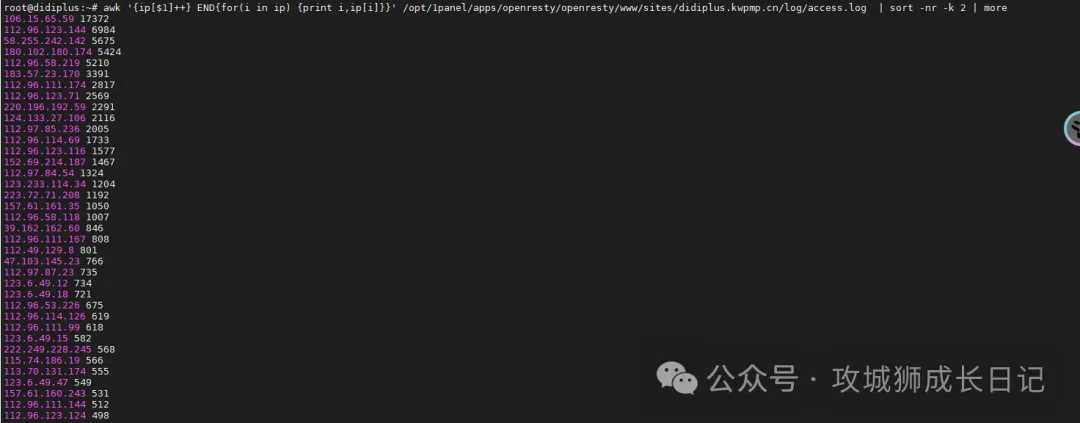
(2) 对上一步的结果根据访问量排名:
awk '{ip[$1]++} END{for(i in ip) {print i,ip[i]}}' \
/opt/1panel/apps/openresty/openresty/www/sites/didiplus.kwpmp.cn/log/access.log \
sort -nr -k 2命令 sort -nr -k 2 的含义如下:
- **-n**:按照数值大小进行排序,而不是字典顺序。
- **-r**:进行逆序排序,从大到小。
- **-k 2**:指定根据第二列进行排序
总结
AWK 是一个灵活且强大的工具,通过以上案例,你可以看到它在实际数据处理中所带来的便利。无论是提取信息、计算统计,还是格式化输出,AWK 都能轻松应对。通过案例驱动的学习方法,你会发现 AWK 不再难,反而是提升数据处理能力的得力助手。