












Kafka作为一款优秀的分布式消息中间件,内部也存在一些选举机制,这篇文章,我们将详细地分析 Kafka如何实现选择 Leader?

一、Kafka集群整体架构
Kafka集群是由多个 Kafka Broker通过连同一个 Zookeeper组成,整个架构可以抽象成下图:
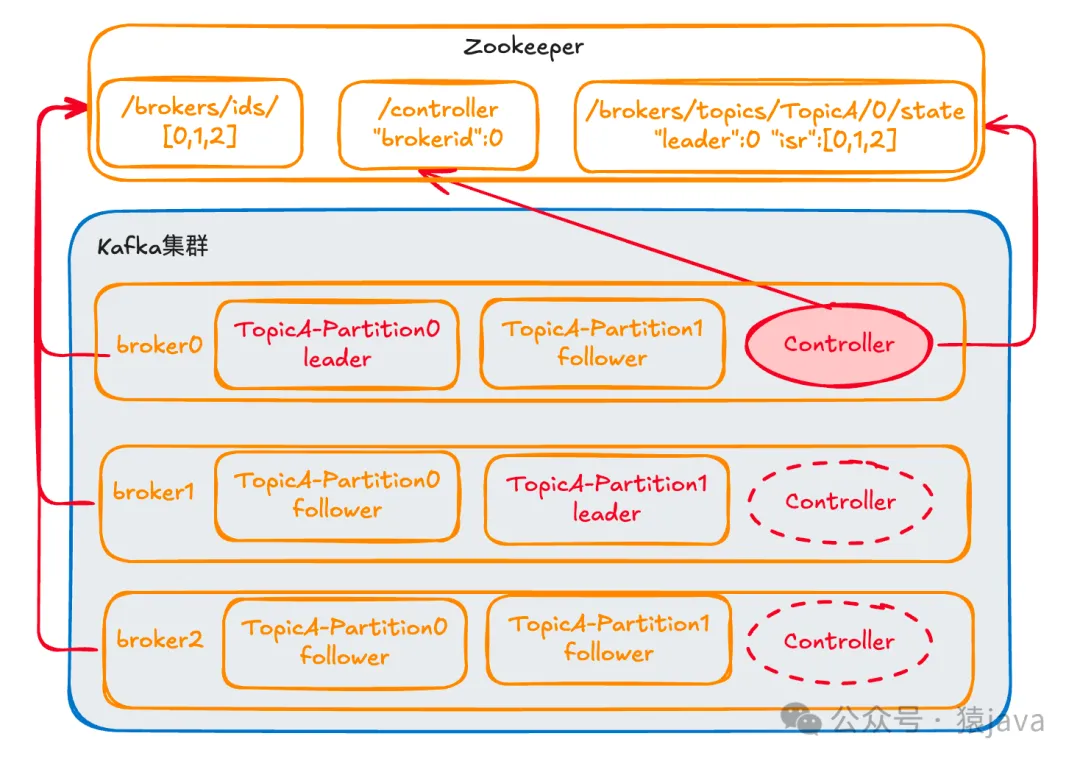
在 Kafka中,数据以 Topic的形式组织,每个主题又被划分为多个分区(Partition),每个分区的数据在 Broker之间有多个副本(Replica),保证数据的高可用和持久性。
二、Controller的作用
Kafka Controller是一个特殊的 Broker实例,它负责 Kafka集群中的领导者选举、分区的分配、以及在 Broker上下线期间重新分配 Leader和副本。Controller通过与 Zookeeper交互来感知集群状态的变化,从而进行必要的领导者重新选举。
三、选主的原理分析
1.Leader的概念
在 Kafka中,每个分区会有多个副本,其中只有一个副本是Leader,其他副本为Follower。Producer和 Consumer会向分区的Leader写入或读取数据,Follower从 Leader复制数据。这样设计实现了高吞吐量的同时保证了数据的冗余。
2.选主过程
选主过程主要包括两个方面:Controller选举和分区Leader选举。
(1) Controller选举
在 Kafka启动时,会注册到 Zookeeper的/brokers/ids的路径下,其中会有一个 Broker节点通过与 Zookeeper的交互被选举为 Controller。具体而言,Brokers通过在 Zookeeper的/controller路径尝试创建一个临时节点(ephemeral node)来竞争成为 Controller,选举规则也很简单,谁先注册到 Zookeeper中的/controller节点,谁就是 Controller。
当当前Controller失效(如宕机或网络问题)时,Zookeeper会删除/controller节点,其他Broker会再次竞争,该过程保证了Controller的高可用。
(2) 分区Leader选举
一旦一个 Broker成为 Controller,它会获取所有分区的最新信息,并基于持久化在 Zookeeper的数据进行当前各分区 Leader的选举。Controller使用 ISR(In-Sync Replica)列表,即当前与 Leader保持同步的所有Follower副本进行选主。默认情况下,ISR中第一个副本被选为新的 Leader。
比如上图中 TopicA中的 Partition0号分区,选择 broker0作为 Leader, 然后会将选择的节点信息注册到 Zookeeper的/brokers/topics路径下,记录谁是 Leader,有哪些服务器可用。
Kafka 在实现 Controller选举方面采用了一种基于 Zookeeper的机制,这种机制充分利用了 Zookeeper的特性来确保集群的高可用性和一致性,接下来,我将深入解析这两种选主的机制。
四、Controller选举机制详解
1. Zookeeper的Role
Zookeeper在Kafka中作为一个分布式协调服务,其负责维护集群的元数据信息,包括Kafka节点的活动状态和每个分区的Replica信息。在Controller选举过程中,Zookeeper充当着协调者的角色,利用其特有的临时节点机制来实现一个分布式的锁。
2. 临时节点
在Zookeeper中,临时节点(Ephemeral Znode)是一个重要的特性,这种节点在客户端会话结束时自动被删除。Kafka利用这一特性实现Controller的自动化选举。
3. Controller选举过程
Kafka的Controller选举过程主要分为以下几个步骤:
- 初始化: 当Kafka Broker启动时,所有Broker都试图成为Controller。每个Broker会进行一次自检,初始化必要的Controller管理器和相关结构。
- 创建Zookeeper路径: 每个Broker尝试在Zookeeper的特定路径(通常是/controller)下创建一个临时节点。该节点的路径即为Zookeeper中控制选举的关键路径。
- 竞争锁: 因为临时节点的特性,只有第一个成功创建的节点会存在于Zookeeper。因此,能创建成功的Broker就会成为当前集群的Controller。这相当于分布式锁机制,谁获取到锁谁成为Controller。
- 故障处理与重新选举: 如果当前的Controller(持有Zookeeper节点的Broker)崩溃或因网络问题与Zookeeper断开连接,Zookeeper会自动删除该Broker创建的临时节点。剩余的Broker会监听这个节点的变化(通过Zookeeper的Watcher机制),当节点被删除时,会重新发起竞争,确保能够快速选出一个新的Controller。
4. 实现细节
从实现的角度来看,我们可以看看 Kafka的相关主要类和方法涉及的过程:
- Zookeeper客户端初始化: 初始化时,Kafka的KafkaController类通过Zookeeper客户端来与ZooKeeper服务建立连接,这是基础。
- Controller路径定义: 在Kafka源码中,通常由ControllerZNodePaths.CONTROLLER_PATH常量定义Controller路径。
在ControllerEventManager类中,核心的方法参与Zookeeper节点的创建与监听:
public void onControllerFailover() {
try {
// 尝试在Zookeeper创建临时节点
zkClient.createEphemeralPathExpectConflictHandleZnode(
ControllerZNodePaths.CONTROLLER_PATH,
controllerString(),
onControllerFailover);
// 设置Controller监听器
zkClient.subscribeDataChanges(ControllerZNodePaths.CONTROLLER_PATH, new ControllerChangeListener());
} catch (Exception e) {
// 异常处理
}
}在上述代码段中,展示了当一个 Broker准备竞选为Controller时,他会在Zookeeper的/controller路径创建一个临时节点,并设置对该节点变化的监听器。
5. 监听机制
每个Broker通过设置Watcher来监听/controller节点的删除事件。一旦现有Controller的连接丢失,所有的Broker都会收到这个事件通知。这个机制确保了在现有Controller失效时,能够迅速选出新的Controller。
6. Leader和集群的稳定性
一旦新的Controller被选出,它就会获取集群的元数据,并开始执行其职责,包括领导者重新选举和分区管理等操作。为了确保集群状态的一致性和稳定性,Controller必须在全面获取并更新当前集群状态后才能完全上线。
五、分区Leader选举详解
当然,Kafka中的分区Leader选举是确保数据高可用性和一致性的关键机制之一。让我们更详细地探讨一下这一过程,包括其触发条件、具体步骤和相关代码实现细节。
1.分区Leader选举的触发条件
分区Leader选举主要在以下几种情况下被触发:
- Broker新增或宕机:当一个Broker加入集群或者从集群中失联(掉线)时,需要重新分配分区的Leader。
- ISR(In-Sync Replica)变化:ISR列表中的Replica发生变化,比如某个Replica落后过多或恢复同步。
- Controller切换:如果当前的Controller失效,新Controller上线后需要重新确认并分配分区的Leader。
2.选举的具体步骤
分区Leader选举过程主要涉及以下几步:
(1) 获取分区信息
一旦选举触发,Controller需获取每个分区的元数据信息,包括:
- 当前Leader。
- ISR列表(保持与Leader同步的副本集合)。
- 所有分区的Replica列表。
(2) 确定新Leader
Controller根据ISR列表来选择新的Leader,通常选择第一个Replica作为新的Leader,这样保证选择的是同步的且相对最新的副本。此外,Kafka允许通过配置参数自定义选举策略,确保更灵活地处理特殊场景。
(3) 更新Zookeeper
选出新的Leader后,需将这个新的Leader信息更新到Zookeeper,这包括更新分区的Leader和ISR信息。此步骤确保其他Broker即使在Controller切换的情况下,也能从Zookeeper获取到正确的分区Leader信息。
(4) 通知各Broker
更新完Zookeeper后,Controller通过向集群中其他Broker发送Leader和ISR更新信息,通知它们该分区的Leader已发生改变。这涉及使用Kafka的内部API向其他Broker推送集群状态变更。
3.核心代码分析
以下是分区Leader选举过程中的一些核心代码实现示例:
(1) 获取ISR列表
public List<Integer> getIsrForPartition(Partition partition) {
// 获取分区的ISR列表
return partition.getIsr();
}ISR列表的获取是选举过程中的基础步骤,确保后续的Leader选举从一致的数据集合中挑选。
(2) 选举新Leader
下面的代码展示了如何选择 Leader,通过从 ISR中挑选第一个节点作为新 Leader,确保选择的 Leader始终是最新同步过的一个。
public int selectNewLeader(/* some parameters */) {
List<Integer> isr = currentIsr(partition);
if (isr.isEmpty()) {
throw new IllegalStateException("ISR should not be empty");
}
// 默认选择ISR列表中的第一个
int newLeader = isr.get(0);
// 更新新Leader信息到Zookeeper
zkClient.updateLeaderAndIsr(newLeader, isr);
return newLeader;
}(3) 更新到Zookeeper
public void updateLeaderAndISR(int newLeader, List<Integer> newIsrList, Partition partition) {
zkClient.setData(ControllerZNodePaths.getTopicPartitionStatePath(partition),
new LeaderAndIsrZNodeData(newLeader, newIsrList));
}这段代码表示将新的 Leader和 ISR信息更新到Zookeeper,确保全局一致性。
总结
本文,我们分析了 Kafka的 Leader选举机制原理,它通过巧妙利用 Zookeeper和 ISR列表,提升了 Kafka的可靠性和可用性,但是,因为重度依赖 Zookeeper,因此使得 Kafka也存在很多风险。作为程序员,了解 Kafka的机制,可以帮助我们更好地使用和运维 Kafka。
























