













本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面 & 笔者的个人理解
闭环仿真对于推进端到端自动驾驶系统至关重要。当代的传感器仿真方法,如NeRF和3DGS,主要依赖于与训练数据分布紧密一致的条件,这些条件在很大程度上局限于前向驾驶场景。因此,这些方法在渲染复杂的机动动作(如变道、加速、减速)时面临局限性。自动驾驶世界模型的最新进展已经证明了生成多样化驾驶视频的潜力。然而,这些方法仍然局限于2D视频生成,固有地缺乏捕捉动态驾驶环境复杂性所需的时空连贯性。本文介绍了DriveDreamer4D,它利用世界模型先验增强了4D驾驶场景表示。具体来说,我们利用世界模型作为数据机器,基于现实世界的驾驶数据合成新的轨迹视频。值得注意的是,我们明确地利用结构化条件来控制前景和背景元素的时空一致性,因此生成的数据与流量约束密切相关。据我们所知,DriveDreamer4D是第一个利用视频生成模型来改善驾驶场景中4D重建的工作。实验结果表明,DriveDreamer4D显著提高了新轨迹视图下的生成质量,与PVG、S3高斯和可变形GS相比,FID相对提高了24.5%、39.0%和10.5%。此外,DriveDreamer 4D显著增强了驱动代理的时空一致性,这得到了综合用户研究的验证,NTA-IoU度量的相对增加了20.3%、42.0%和13.7%。

总结来说,本文的主要贡献如下:
- 提出了DriveDreamer4D,这是第一个利用世界模型先验来推进自动驾驶4D场景重建的框架;
- NTGM旨在自动生成各种结构化条件,使DriveDreamer4D能够生成具有复杂机动的新颖轨迹视频。通过明确地结合结构化条件,DriveDreamer4D确保了前景和背景元素的时空一致性;
- 进行了全面的实验,以验证DriveDreamer4D显著提高了新轨迹视点的生成质量,以及驾驶场景元素的时空连贯性。
相关工作回顾
驾驶场景表示
NeRF和3DGS已成为3D场景表示的主要方法。NeRF模型使用多层感知器(MLP)网络构建连续的体积场景,实现了具有卓越渲染质量的高度详细的场景重建。最近,3DGS引入了一种创新方法,通过在3D空间中定义一组各向异性高斯分布,利用自适应密度控制从稀疏点云输入中实现高质量的渲染。有几项工作将NeRF或3DGS扩展到了自动驾驶场景。鉴于驾驶环境的动态特性,在建模4D驾驶场景表示方面也做出了重大努力。一些方法将时间编码为参数化4D场景的额外输入,而另一些方法将场景表示为运动对象模型与静态背景模型的组合。尽管取得了这些进步,但基于NeRF和3DGS的方法仍面临着与输入数据密度相关的局限性。只有当传感器数据与训练数据分布非常匹配时,这些技术才能有效地渲染场景,而训练数据分布通常仅限于前方驾驶场景。
世界模型
世界模型模块根据参与者提出的想象动作序列预测未来可能的世界状态。通过自由文本动作控制的视频生成来仿真环境等方法。处于这一进化最前沿的是Sora,它利用先进的生成技术来生成尊重物理基本定律的复杂视觉序列。这种深入理解和仿真环境的能力不仅提高了视频生成质量,而且对现实世界的驾驶场景也有重大影响。自动驾驶世界模型采用预测方法来解释驾驶环境,从而生成现实的驾驶场景,并从视频数据中学习关键的驾驶要素和政策。尽管这些模型成功地生成了基于复杂驾驶动作的多样化驾驶视频数据,但它们仍然局限于2D输出,缺乏准确捕捉动态驾驶环境复杂性所需的时空一致性。
3D表示的扩散先验
从有限的观测中构建全面的3D场景需要生成先验,特别是对于看不见的区域。早期的研究将文本到图像扩散模型中的知识提炼成3D表示模型。具体而言,采用分数蒸馏采样(SDS)从文本提示合成3D对象。此外,为了增强3D一致性,有几种方法将多视图扩散模型和视频扩散模型扩展到3D场景生成。为了在复杂、动态、大规模的驾驶场景之前扩展扩散以进行3D重建,SGD、GGS和MagicDrive3D等方法采用生成模型来拓宽训练视角的范围。尽管如此,这些方法主要针对稀疏的图像数据或静态背景元素,缺乏充分捕捉4D驾驶环境中固有复杂性的能力。
DriveDreamer4D方法详解
整体架构
DriveDreamer4D的整体流程如图2所示。在上半部,提出了一种新的轨迹生成模块(NTGM),用于调整转向角和速度等原始轨迹动作,以生成新的轨迹。这些新颖的轨迹为提取3D盒子和HDMap细节等结构化信息提供了新的视角。随后,可控视频扩散模型从这些更新的视点合成视频,并结合与修改后的轨迹相关的特定先验。在下半部分,整合了原始和新颖的轨迹视频,以优化4DGS模型。在接下来的部分中,我们将深入研究新轨迹视频生成的细节,然后介绍使用视频扩散先验的4D重建。

新轨迹视频生成
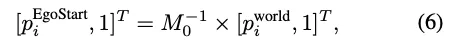

在自车辆坐标系中,车辆的航向与正x轴对齐,y轴指向车辆的左侧,z轴垂直向上,垂直于车辆平面。因此通过沿x轴和y轴调整值,可以分别表示车辆速度和方向的变化。对新生成的轨迹点进行最终安全评估,包括验证车辆轨迹p是否保持在可驾驶区域Broad内,并确保不会与行人或其他车辆发生碰撞。

一旦生成了符合交通规则的新轨迹,道路结构和3D边界框就可以从新轨迹的角度投影到相机视图上,从而生成与更新轨迹相关的结构化信息。这种结构化信息,连同初始帧和文本,被输入到世界模型中,以生成遵循新轨迹的视频。
基于视频扩散先验的4D重建
基于视频扩散先验,我们可以生成具有不同轨迹的新颖视频,增强跨不同基线的4D重建能力。具体来说,为了使用视频扩散先验训练4DGS,必须构建一个混合数据集Dhybrid,该数据集将原始轨迹数据集Dori与新的轨迹数据集Dnovel相结合。这些数据集之间的平衡可以通过超参数β进行调整,使我们能够控制原始和新轨迹的4DGS场景重建性能。这种关系被表述为Dhybrid。
使用生成的数据优化4DGS的损失函数Lnovel,定义如下:

值得注意的是,在使用生成的数据集Dnovel时,深度图不作为4DGS优化的约束。限制源于LiDAR点云数据仅针对原始轨迹收集。当这些激光雷达点投影到新的轨迹上时,它无法为新的视角生成完整的深度图,因为新轨迹中可见的东西可能在原始视图中被遮挡了。因此,合并这样的深度图不利于4DGS模型的优化。混合训练的总体损失函数定义如下:

实验
实验设置
数据集。我们使用Waymo数据集进行实验,该数据集以其全面的真实世界驾驶日志而闻名。然而,大多数日志捕捉的场景具有相对直接的动态,缺乏对密集、复杂的车辆交互场景的关注。为了解决这一差距,我们特别选择了八个以高度动态交互为特征的场景,其中包括许多具有不同相对位置和复杂驾驶轨迹的车辆。每个选定的片段包含大约40帧,片段ID在补充中有详细说明。
实施细节。为了证明DriveDreamer4D的多功能性和鲁棒性,我们将各种4DGS基线纳入我们的管道,包括可变形GS、S3Gaussian和PVG。为了进行公平的比较,LiDAR监控被引入到Deformable GS中。在训练过程中,场景被分割成多个片段,每个片段包含40帧,与生成模型的输出长度对齐。我们只使用前置摄像头数据,并将不同方法的分辨率标准化为640×960。我们的模型使用Adam优化器进行了50000次迭代训练,遵循用于3D高斯散斑的学习率计划。训练策略和超参数与每个基线的原始设置保持一致,每个模型训练了50000次迭代。
指标。传统的3D重建任务通常采用PSNR和SSIM指标进行评估,验证集与训练数据分布非常匹配(即,从视频序列中均匀采样帧进行验证,其余用于训练)。然而,在闭环驾驶仿真中,重点转移到评估新轨迹下的模型渲染性能,在这种轨迹下,相应的传感器数据不可用,使得PSNR和SSIM等指标不适用于评估。因此,我们提出了新的轨迹代理IoU(NTA-IoU)和新的轨迹车道IoU(NTL-IoU),它们评估了新轨迹视点中前景和背景交通分量的时空一致性。
对于NTA IoU,我们使用YOLO11在从新的轨迹视图渲染的图像中识别车辆,从而产生2D边界框。同时,对原始的3D边界框应用几何变换,将其投影到新的视点上以生成相应的2D边界框。对于每个投影的2D框,我们然后识别最接近的探测器生成的2D框并计算它们的交点(IoU)。为了确保精确匹配,引入了距离阈值dthresh:当最近检测到的框Bdet和正确投影的框Bproj之间的中心到中心距离超过此阈值时,它们的NTA IoU被分配为零值:

对于NTL IoU,我们使用TwinLiteNet从渲染图像中提取2D车道。地面真实车道也被投影到2D图像平面上。然后,我们计算渲染车道Ldet和GT车道Lproj之间的平均交点(mIoU):

此外在变道场景中,我们观察到相对定位的不准确,以及飞行点和重影等伪影的频繁出现,这些伪影会显著降低图像质量。为了评估这一点,我们采用了FID度量,该度量量化了渲染的新轨迹图像和原始轨迹图像之间的特征分布差异。该指标有效地反映了视觉质量,对飞行点和重影等伪影特别敏感,为这些复杂场景中的图像保真度提供了强有力的衡量标准。最后,我们进行了一项用户研究来评估发电质量。具体来说,我们比较了每种基线方法及其DriveDreamer4D增强版本在三种不同的新轨迹上的视觉结果。评估标准侧重于整体视频质量,特别关注车辆等前景物体。对于每次比较,参与者被要求选择他们认为最有利的选项。





讨论和结论
在这篇论文中,我们提出了DriveDreamer4D,这是一个新的框架,旨在通过利用世界模型中的先验来推进4D驾驶场景表示。DriveDreamer4D利用世界模型生成新的轨迹视频,以补充现实世界的驾驶数据,解决了当前传感器仿真方法的关键局限性,即它们对前向驾驶训练数据分布的依赖性以及无法对复杂机动进行建模。通过明确采用结构化条件,我们的框架保持了前景和背景元素的时空一致性,确保生成的数据与现实世界交通场景的动态密切相关。我们的实验表明,DriveDreamer4D在生成各种仿真视角方面实现了卓越的质量,在场景组件的渲染保真度和时空一致性方面都有显著提高。值得注意的是,这些结果突出了DriveDreamer4D作为闭环仿真基础的潜力,闭环仿真需要动态驾驶场景的高保真重建。




























