译者 | 朱先忠
审校 | 重楼
本文将通过探讨微软开源Florence-2模型的零样本功能来全面了解其在字幕识别、目标检测、分割和OCR等领域的应用。

简介
近年来,计算机视觉领域见证了基础模型的兴起,这些模型可以在不需要训练自定义模型的情况下进行图像注释。我们已经看到了用于分类的CLIP模型(参考文献2)、用于对象检测的Grounding DINO(参考文献3)和用于分割的SAM(参考文献4)等模型,每种模型在其各自领域都表现出色。但是,我们是否能够开发一个能够同时处理所有这些任务的单一模型呢?
在本教程中,我们将要介绍Florence-2模型(参考文献1)——一种新颖的开源视觉语言模型(VLM),旨在处理各种视觉和多模型任务,包括字幕识别、对象检测、分割和OCR等内容。
通过Colab笔记本文件形式,我们将开始探索Florence-2的零样本功能,用来注释一部旧相机的图像。
Florence-2模型
背景
Florence-2模型于2024年6月由微软发布。它被设计为在单个模型中执行多个视觉任务。这是一个开源模型,可以在麻省理工学院许可的Hugging Face网站上使用。
尽管Florence-2模型的尺寸相对较小,仅具有0.23B和0.77B个参数的版本,但它实现了最先进的性能。其紧凑的尺寸使其能够在计算资源有限的设备上高效部署,同时确保快速的推理速度。
该模型在一个名为FLD-5B的庞大、高质量的数据集上进行了预训练,该数据集由1.26亿张图像上的5.4B个注释组成。这使得Florence-2模型在许多任务中都能在零样本情况下表现出色,而无需额外训练。
Florence-2模型的原始开源权重支持以下任务:
任务类型 | 任务提示文本 | 任务描述 | 输入信息形式 | 输出 |
图像字幕 | <CAPTION> | 为图像生成基本标题 | 图像 | 文本 |
<DETAILED_CAPTION> | 为图像生成详细的标题 | 图像 | 文本 | |
<MORE_DETAILED_CAPTION> | 为图像生成非常详细的标题 | 图像 | 文本 | |
<REGION_TO_CATEGORY> | 为指定的边界框生成类别标签 | 图像,边界盒 | 文本 | |
<REGION_TO_DESCRIPTION> | 为指定的边界框生成描述 | 图像,边界盒 | 文本 | |
对象检测 | <OD> | 检测对象并生成带有标签的边界框 | 图像 | 边界盒,文本 |
<DENSE_REGION_CAPTION> | 检测对象并生成带有标题的边界框 | 图像 | 边界盒,文本 | |
<CAPTION_TO_PHRASE_GROUNDING> | 用边界框检测并固定字幕中的短语 | 图像,文本 | 边界盒,文本 | |
<OPEN_VOCABULARY_DETECTION> | 根据提供的文本(开放词汇表)检测对象 | 图像,文本 | 边界盒,文本 | |
<REGION_PROPOSAL> | 用边界框提出感兴趣的区域 | 图像 | 边界盒 | |
分割 | <REFERRING_EXPRESSION_SEGMENTATION> | 基于文本描述生成分割多边形 | 图像,文本 | 多边形 |
<REGION_TO_SEGMENTATION> | 为给定的边界框生成分割多边形 | 图像,边界盒 | 多边形 | |
OCR | <OCR> | 从整个图像中提取文本 | 图像 | 文本 |
<OCR_WITH_REGION> | 提取带有位置的文本(边界框或四边形框) | 图像 | 文本,边界盒 |
通过微调模型可以添加其他不受支持的任务。
任务格式
受大型语言模型的启发,Florence-2被设计为一种序列到序列的模型。它将图像和文本指令作为输入,并输出文本结果。输入或输出文本可以表示纯文本或图像中的区域。区域格式因任务而异:
- 边界框:“<X1><Y1><X2><Y2>”用于对象检测任务。这些标记表示长方体左上角和右下角的坐标。
- 四边框:“<X1><Y1><X2><Y2><X3><Y3><X4><Y4>”用于文本检测,使用包围文本的四个角的坐标。
- 多边形:“<X1><Y1><Xn><Yn>'用于分割任务,其中坐标按顺时针顺序表示多边形的顶点。
架构
Florence-2模型是使用标准“编码器-解码器”转换器架构构建的。以下是该过程的工作原理:
- 输入图像由DaViT视觉编码器嵌入(参考文献5)。
- 文本提示使用BART(参考文献6)嵌入,利用扩展的标记器和单词嵌入层。
- 视觉和文本嵌入都是连接在一起的。
- 这些级联的嵌入由基于转换器的多模型编码器-解码器处理,以生成响应。
- 在训练过程中,该模型最小化交叉熵损失,类似于标准语言模型。
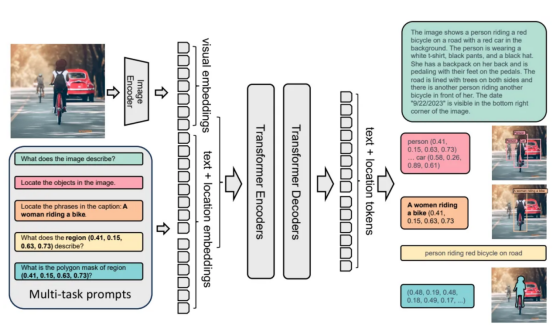
Florence-2模型架构图(来源链接:https://arxiv.org/abs/2311.06242)
代码实现
加载Florence-2模型和一个样本图像
安装并导入必要的库后,我们首先加载Florence-2模型、处理器和相机的输入图像:
辅助函数
在本教程中,我们将使用几个辅助函数。最重要的是run_example核心函数,它从Florence-2模型生成响应。
run_example函数将任务提示与任何其他文本输入(如果提供的话)组合成一个提示。借助处理器,它生成文本和图像嵌入,作为模型的输入。最神奇的事情发生在model.generate步骤中,在该步骤中生成模型的响应。以下是一些关键参数的详细解释:
- max_new_tokens=1024:设置输出的最大长度,允许输出详细的响应。
- do_sample=False:确保产生确定性的响应。
- num_beams=3:在每个步骤中使用前3个最可能的标记进行波束搜索,探索多个潜在序列以找到最佳的整体输出。
- early_stoping=False:确保波束搜索继续进行,直到所有波束达到最大长度或生成序列结束标记。
最后,使用processor.batch_decode和processor.post_process_generation对模型的输出进行解码和后处理,以便产生最终的文本响应。该响应由run_example函数返回。
此外,我们利用辅助函数来可视化结果(draw_box、draw_ocr_bboxes和draw_polygon),并处理边界框格式(convert_box_to_florence-2和convert_florence-2_to_bbox)之间的转换。所有这些内容,有兴趣的读者可以在随附的Colab笔记本文件中进一步探索。
其他方面的任务
Florence-2模型可以执行各种视觉任务。让我们从图像字幕识别开始探索它的一些功能。
1.为生成相关任务添加字幕
(1)生成字幕
Florence-2模型可以使用“<CAPTION>”、“<DETAILED_CAPTION>”或“<MORE_DETAILED_CACTION>”任务提示生成各种细节级别的图像字幕。
该模型准确地描述了图像及其周围环境。它甚至可以识别相机的品牌和模型,展示其OCR功能。然而,在“<MORE_DETALED_CAPTION>”任务中,存在轻微的不一致性,这是零样本模型所预期的。
(2)为给定的边界框生成字幕
Florence-2模型可以为图像中由边界框定义的特定区域生成字幕。为此,它将边界框位置作为输入。你可以使用“<REGION_TO_category>”提取类别,或使用“<REGION_TO_DESCRIPTI>”提取描述。
为了你的使用方便,我在Colab笔记本中添加了一个小部件,使你能够在图像上绘制一个边界框,并编写代码将其转换为Florence-2格式。
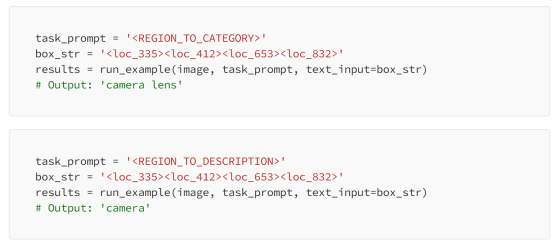
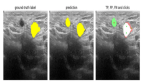
在这种情况下,“<REGION_TO_CATEGORY>”标识了镜片,而“<REGION _TO_DESCRIPTI>”则不太具体。但是,此性能可能因不同的图像而有所不同。
2.目标检测相关任务
(1)为对象生成边界框和文本
Florence-2模型可以识别图像中密集的区域,并提供它们的边界框坐标和相关的标签或字幕。要提取带有标签的边界框,请使用“<OD>”任务提示:
要提取带有文本内容的边界框,请使用“<DENSE_REGION_CAPTION>”任务提示:

左侧的图像显示了“<OD>”任务提示的结果,而右侧的图像显示的是“<DENSE_REGION_CAPTION>”。
(2)基于文本的对象检测
Florence-2模型还可以执行基于文本的对象检测。通过提供特定的对象名称或描述作为输入,Florence-2模型可以检测指定对象周围的边界框。

CAPION_TO_PHRASE_ROUNDING任务,文本输入:“镜头、相机、桌子、徽标、闪光灯。”
3.分割相关任务
Florence-2还可以生成基于文本(“<REFERRING_EXPRESSION_segmentation>”)或边界框(“<REGION_TO_segmentation>”)的分割多边形:

左侧的图像显示了以“camera”文本作为输入的REFERRING_EXPRESSION_SEGMENTATION任务的结果。右侧的图像演示了REGION_TO_SEGMENTION任务,镜头周围有一个边界框作为输入。
4.OCR相关任务
Florence-2模型还展示出强大的OCR功能。它可以使用“<OCR>”任务提示从图像中提取文本,并使用“<OCR_with_REGON>”提取文本及其位置。

结束语
总之,Florence-2模型是一个通用的视觉语言模型(VLM),它能够在单个模型中处理多个视觉任务。其零样本功能在图像字幕、对象检测、分割和OCR等各种任务中都给人留下深刻印象。虽然Florence-2模型表现良好,但是额外的微调可以进一步使模型适应新任务,或提高其在独特的自定义数据集上的性能。
参考文献
本文在Colab Notebook中的源代码链接地址:https://gist.github.com/Lihi-Gur-Arie/427ecce6a5c7f279d06f3910941e0145
《Florence-2:推进各种视觉任务的统一表示》。原文地址:https://arxiv.org/pdf/2311.06242
《CLIP:从自然语言监督中学习可转移的视觉模型》。原文地址:https://arxiv.org/pdf/2103.00020v1
《Grounding DINO:将DINO与开放式目标检测的预训练相结合》。https://arxiv.org/abs/2303.05499
《SAM2:分割图像和视频中的任何内容》。原文地址:https://arxiv.org/pdf/2408.00714
《DaViT:双注意力视觉转换器》。地址:https://arxiv.org/abs/2204.03645
《BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练》。地址:https://arxiv.org/pdf/1910.13461
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Florence-2: Advancing Multiple Vision Tasks with a Single VLM Model,作者:Lihi Gur Arie