本文来自南京大学计算机学院软件研究所,聚焦于开放环境下的智能软件新技术研究,定位国际学术前沿,面向国家关键需求,承担了一系列国家科技部和基金委重大/重点科研项目。团队拥有包括中科院院士等多名国家级人才,重点关注软件和智能方向,研究成果发表于NeurIPS/ICLR/SOSP/ATC/EuroSys/OOPSLA/PLDI/ICSE/FSE等国际顶级会议,其中多篇文章获得相应会议的最佳论文奖。
大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。当遇到算术问题时,LLM 通常依赖记住特定的表达式及其对应结果的方式输出算术问题的结果。通过简单的实验发现,LLM 只在语言层面表达了对算术运算的逻辑理解,但并没有运用计算逻辑解决算术问题,这对 LLM 在相关领域中的应用造成了重大障碍,同时影响了其推广到新场景的能力。
为了解决这个问题,来自南京大学的研究者提出了一种面向 LLM 的可组装算术执行框架 (CAEF),使 LLM 能够通过模仿图灵机的方式来执行算术,从而理解计算逻辑。此外,CAEF 具有高度的可扩展性,允许组合已经学习到的运算符,以降低复杂运算符的学习难度。评估表明,LlaMA 3.1-8B 模型配合 CAEF 可在 7 种经典数学算术运算的测试中实现了近乎 100% 的准确率,且能够支撑 100 位操作数的计算,而同等难度下, GPT-4o 在一些算术问题测试中无法正确给出计算结果。

- 论文标题:Executing Arithmetic: Fine-Tuning Large Language Models as Turing Machines
- 论文地址:https://arxiv.org/abs/2410.07896
- 项目主页:https://github.com/NJUDeepEngine/CAEF
该工作的贡献主要有以下部分:
- 可组装的算术执行框架:提出了一种面向 LLM 的算术执行框架,使 LLM 能够通过模仿图灵机的方式解决算术问题、掌握运算符的计算逻辑。此外,CAEF 还支持组合多个已学习的运算符来实现更复杂的运算符。
- Executor 和 Aligners:基于框架 CAEF,实现了七个常见运算符,分别构造了对应的 executor 和 aligner。其中,executor 负责以迭代方式分步执行计算,而 aligner 充当接口,完成 executor 的图灵机风格表示和原始文本表示之间的双向转换。
- 计算准确率:实验结果表明,基于 CAEF 的 LLaMA 3.1-8B 在这七个运算符上的表现优于现有的 LLM,且能够在操作数高达 100 位时实现几乎 100% 的准确率。
相关工作
LLM 面对数学问题:当前研究主要集中如何在提高 LLM 面对数学任务的解题性能,通常引入外部工具来辅助 LLM 解决计算部分的内容。一类常见的外部工具为计算器,如 Schick et al. (2024) [1] ,该工作引入了一种自监督学习方法,模型在该方法中学习何时通过 API 访问调用外部工具,类似的策略可以在 Gou et al. (2023) [2] 和 He-Yueya et al. (2023) [3] 中也能找到。另一类工具是编程语言解释器,例如 Python,LLM 生成用于解决数学问题的代码,再交由外部解释器执行代码以获得最终的结果。一个典型的例子是 Lu et al. (2024) [4] ,它将 LLM 视为生成代码并将其提交给外部 Python 执行程序以处理表格上下文中的数学问题。Wang et al. (2023) [5] 采用监督学习的方式让 LLM 学习如何通过构建用于解决数学问题的程序,而 Zhou et al. (2023) [6] 提出了一种零样本提示方法,以实现代码驱动的自我验证,从而提高数学解题性能。
LLM 面对算术问题:当前也有一些专注于 LLM 算术方面的研究。这些研究的共同目标是尝试教会 LLM 计算逻辑,并通过分步计算的方法拆解计算过程,以提高计算准确性。在这些研究中,Nye et al. (2021) [7] 是一项早期且影响深远的 方法。它在算术领域引入了类似思维链 (CoT) 的思想拆分计算过程,让语言模型把计算的中间步骤输出到一个被称为 “scratchpad” 的缓冲区,显著提高了 LLM 整数加法的性能。Hu et al. (2024) [8] 观察到 transformers 倾向于使用 “基于记忆样例的推理” 来处理算术问题,并提出了一种遵循规则的微调技术,指导模型逐步执行计算。Zhou et al. (2024) [9] 结合了四种技术(FIRE 位置编码、随机位置编码、反向格式(R2L 格式)和索引提示)开发了一种新模型,该模型在两个整数加法问题上实现了 2.5× 的长度泛化能力。
方法描述
该工作设计了一种可以使 LLM 学习模拟图灵机执行的框架 CAEF。图灵机中的转移函数(transition function)描述了基于当前计算状态和纸带信息应该执行什么操作,其中天然蕴含了分步计算的逻辑。此外,组装多个现有的图灵机能够实现更加复杂的计算逻辑,因此图灵机为计算提供了一个很好的思路。然而,LLM 是基于文本的生成式模型,因此如何将图灵机的工作模式有效地转移到 LLM 上成为了一个难点。
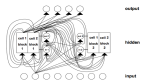
框架设计:针对这个问题,CAEF 设计了一种 LLM 友好的基于文本的表示系统,其工作示意如图 1 所示,左侧是一个自动机状态图示例,右侧是 CAEF 的工作示意图。CAEF 设计了一套基于文本的表示,包括两组必需的元素:状态 (state) 和命令 (command),分别对应于图中的蓝色和粉色部分。state 部分记录了当前的计算状态 (status)、操作数 (operands)、计算中间变量和结果等信息。Command 部分由一组操作组成,例如写入 ([OUTPUT]) 和调用 ([CALL])。输入当前状态和命令后,LLM 会以类似自动机的方式,生成下一个状态和相应的命令,对应于状态图中的一次状态转换。这个过程中,形式化来说,LLM 的学习目标即一个转移函数 ,对于给定
,对于给定 的计算中间结果 <
的计算中间结果 < >,LLM 需要生成下一个中间结果 <
>,LLM 需要生成下一个中间结果 < >,即
>,即 。LLM 通过学习计算的单步执行,就能以迭代的方式完成计算任务。
。LLM 通过学习计算的单步执行,就能以迭代的方式完成计算任务。

图 1. CAEF 框架图示

图 2. 45+67 执行过程
此外,由于计算的初始状态和命令 < > 本身并不存在,CAEF 针对每个操作符需要设计两个组件,一个是用于充当自然语言表示和图灵机风格表示之间 “翻译” 的 aligner,另一个是依照上述流程、负责实际执行计算的 executor,两者以独立的 LoRA adapter 的形式存在。其中 executor 可进一步细分为 basic executor 和 executor composer。针对像加法这样相对容易的基础运算符,可由单一的 LoRA adapter 实现功能,被称为 basic executor;而像乘法这样可以做进一步分解的复杂运算符,其 executor 本身不负责实际运算,它通过组织计算步骤、调用其他运算符的 executor 来实现功能,被称为 executor composer。
> 本身并不存在,CAEF 针对每个操作符需要设计两个组件,一个是用于充当自然语言表示和图灵机风格表示之间 “翻译” 的 aligner,另一个是依照上述流程、负责实际执行计算的 executor,两者以独立的 LoRA adapter 的形式存在。其中 executor 可进一步细分为 basic executor 和 executor composer。针对像加法这样相对容易的基础运算符,可由单一的 LoRA adapter 实现功能,被称为 basic executor;而像乘法这样可以做进一步分解的复杂运算符,其 executor 本身不负责实际运算,它通过组织计算步骤、调用其他运算符的 executor 来实现功能,被称为 executor composer。
Basic executor:以加法为例,文章介绍 basic executor 的设计过程。加法可以通过模拟累加器的执行过程实现,即每次从两个操作数中取相同位置的数字,与存储在进位寄存器中的值三者相加,在计算后写入当前位计算结果,同时更新进位寄存器。因此,加法状态和命令的表示 <  > 可构造如下:
> 可构造如下: 应包含:1) 两个操作数、2) 两个指针,用于指示当前参与计算的位置、3) 进位寄存器、 4) 到目前为止的计算结果。
应包含:1) 两个操作数、2) 两个指针,用于指示当前参与计算的位置、3) 进位寄存器、 4) 到目前为止的计算结果。 应包含:1) 进位和输出的写入,2) 移动指针的操作、 3) 计算状态的转换。基于该思路,可以构建加法的抽象执行流程,如图 2 左侧的自动机图所示。以 “45+67=” 这个问题为例,图 2 的右侧展示了 executor 的完整执行流程。完整的文本形式转换过程如下:
应包含:1) 进位和输出的写入,2) 移动指针的操作、 3) 计算状态的转换。基于该思路,可以构建加法的抽象执行流程,如图 2 左侧的自动机图所示。以 “45+67=” 这个问题为例,图 2 的右侧展示了 executor 的完整执行流程。完整的文本形式转换过程如下:
Step 1 (aligner):
45+67=
Step 2 (executor):
state0: ADD, q0, [HEAD1] |5|4 [HEAD2] |7|6 [C] [OUTPUT]
command0: CMD: [C] 0, [HEAD1] RIGHT, [HEAD2] RIGHT, q1
Step 3 (executor):
state1: ADD, q1, [HEAD1]|5|4 [HEAD2]|7|6 [C] 0 [OUTPUT]
command1: CMD: [C] 1, [OUTPUT] 2, [OUTPUT] RIGHT, [HEAD1] RIGHT, [HEAD2] RIGHT, q1
Step 4 (executor):
state2: ADD, q1, |5 [HEAD1]|4 |7 [HEAD2]|6 [C] 1 |2 [OUTPUT]
command2: CMD: [C] 1, [OUTPUT] 1, [OUTPUT] RIGHT, [HEAD1] RIGHT, [HEAD2] RIGHT, q1
Step 5 (executor):
state3: ADD, q1, |5|4 [HEAD1] |7|6 [HEAD2] [C] 1 |2|1 [OUTPUT]
command3: CMD: [OUTPUT] 1, [OUTPUT], [C], qH
Step 6 (executor):
state4: ADD, qH, |5|4 [HEAD1] |7|6 [HEAD2] [C] 1 |2|1|1
command4: No command to execute. Halt state.
Step 7 (aligner):
45+67=112
Executor composer:以乘法为例,文章介绍 executor composer 的设计过程。乘法可以可以通过加法和小于两个操作符实现。以形式 a×b=c 为例,一种简单的乘法实现可以大致视为循环结构。在循环中使用两个累加器:在每次循环中,一个累加器自增 1,另一个累加器在每次循环中累加 a。当第一个累加器达到 b 时,循环结束,第二个累加器的值即为结果 c。在该过程中,累加器通过现有的加法操作符实现,循环终止条件由小于操作符实现,而乘法自身不参与实际运算,仅驱动该流程的执行。基于该思路,可以构建乘法的抽象执行流程,如图 3 左侧的自动机图所示。以 “89×2=” 这个问题为例,图 3 的右侧展示了 executor 的完整执行流程。

图 3. 89×2 执行过程
通过上述设计,CAEF 赋予了 LLM 执行计算的能力,executor composer 的存在还使得该方法具有很高的扩展性,能够有效处理复杂计算。
实验结果
该工作评估了不同运算符、不同位数情况下的算术准确率。实验使用 LLaMA 3.1-8B 预训练模型作为基础模型,在 +、−、×、÷、==、> 和 < 这 7 个运算符上和三个基准进行了比较:1)LLaMA 3.1-8B 预训练模型基于 LoRA、在仅给出计算结果的数据集上直接微调得到的模型、2)LLaMA 3.1-8B-Instruct、3)GPT-4o。

表 1. 七种运算符的总体评估结果,“LLaMA 3.1 (L)” 代表 LoRA 微调后的 LLaMA 3.1-8B,“LLaMA 3.1 (I)” 代表 LLaMA 3.1-8B-Instruct 模型
表 1 展示了 7 个运算符的 CAEF 方法和基准的评估结果。与基准相比,CAEF 在不同运算符、不同长度的操作数的设置下表现相对稳定,准确率高。特别是对于长数字的任务,例如 100 位加法,通过 CAEF 指导的 LLM 可以有效地学习到计算逻辑。
为了进一步探索 executor 和 aligner 在计算过程中的实际性能,该工作在同一数据集上分别进行了评估。如表 2 所示,可以观察到,即使 executor 必须以迭代方式反复生成中间计算步骤,而 aligner 只执行两个转换步骤,但 executor 的整体性能仍然优于 aligner。executor 在所有实验设置中都达到了 99% 以上的准确率,说明当提供正确的初始状态和命令时,它在绝大多数情况下都能有效工作。另一方面,在大多数情况下,与转换 executor 的输出相比,aligner 在转换原始输入时表现出较低的精度,这表明整个计算过程的瓶颈在于操作数的翻转,而不是计算本身。

表 2. 七种运算符的 executor 和 aligner 准确率,executor 的准确率统计的是从初始状态到最后一步中,每一步都正确、最终计算正确的情况。aligner 的精度分为两部分:从原始输入到 executor 表示的转换,记为 aligner (I),以及从 executor 表示到输出的转换,记为 aligner (O)。