由于秒杀场景是库存争抢非常经典的一个应用场景,接下来我会结合秒杀需求,带你看看如何实现高并发下的库存争抢,相信在这一过程中你会对锁有更深入的认识。
锁争抢的错误做法
在开始介绍库存争抢的具体方案之前,我们先来了解一个小知识——并发库存锁。还记得在我学计算机的时候,老师曾演示过一段代码:
public class ThreadCounter {
private static int count = 0;
public static void main(String[] args) throws Exception {
Runnable task = new Runnable() {
public void run() {
for (int i = 0; i < 1000; ++i) {
count += 1;
}
}
};
Thread t1 = new Thread(task);
t1.start();
Thread t2 = new Thread(task);
t2.start();
t1.join();
t2.join();
cout << "count = " << count << endl;
}
}从代码来看,我们运行后结果预期是 2000,但是实际运行后并不是。为什么会这样呢?当多线程并行对同一个公共变量读写时,由于没有互斥,多线程的 set 会相互覆盖或读取时容易读到其他线程刚写一半的数据,这就导致变量数据被损坏。反过来说,我们要想保证一个变量在多线程并发情况下的准确性,就需要这个变量在修改期间不会被其他线程更改或读取。对于这个情况,我们一般都会用到锁或原子操作来保护库存变量:如果是简单 int 类型数据,可以使用原子操作保证数据准确;如果是复杂的数据结构或多步操作,可以加锁来保证数据完整性。
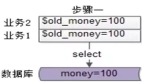
考虑到我们之前的习惯会有一定惯性,为了让你更好地理解争抢,这里我再举一个我们常会犯错的例子。因为扣库存的操作需要注意原子性,我们实践的时候常常碰到后面这种方式:
redis> get prod_1475_stock_1
15
redis> set prod_1475_stock_1 14
OK也就是先将变量从缓存中取出,对其做 -1 操作,再放回到缓存当中,这是个错误做法。
 图片
图片
如上图,原因是多个线程一起读取的时候,多个线程同时读到的是 5,set 回去时都是 6,实际每个线程都拿到了库存,但是库存的实际数值并没有累计改变,这会导致库存超卖。如果你需要用这种方式去做,一般建议加一个自旋互斥锁,互斥其他线程做类似的操作。
原子操作
当大量用户并发修改某个变量时,使用互斥锁虽然能保证数据修改的正确性,但性能非常低。假设有一万个用户争抢一个锁,排队等待修改服务器中的变量,这样的设计效率极差。锁在获取过程中需要自旋,反复尝试才能抢到锁,用户越多,争抢越激烈,系统资源的消耗就越大,可能导致系统不稳定。
为了解决这个问题,我会选择将库存数据存放在高性能的内存缓存服务(比如 Redis)中集中管理。这样可以避免用户争抢锁时影响到其他服务,同时也能提高响应速度。Redis 本身支持原子操作,并且通过它可以更好地应对高并发场景。这也是目前互联网行业普遍采用的库存保护方案。
相比之下,不建议通过数据库行锁来保证库存的修改。数据库资源非常宝贵,如果使用行锁管理库存,不仅性能会很差,系统也容易变得不稳定。
为了减少锁争抢和提升系统效率,我们可以采取降低锁粒度的方式,或者引入其他优化方案。
 图片
图片
实际上,我们可以通过将热门商品的库存进行拆分,存储到多个 key 中,从而显著减少锁的竞争。比如,假设当前商品的库存为 100 个,可以把库存分成 10 个 key,每个 key 保存 10 个库存,并将这些 key 分布在不同的 Redis 实例中。当用户下单时,可以随机选择一个 key 扣减库存。如果某个 key 中的库存不足,再记录该 key 并随机挑选剩余的 key 进行扣减,直到成功完成一次库存的扣除。
不过,除了这种方法之外,我更推荐使用 Redis 的原子操作来处理库存问题。原子操作的粒度更小,并且 Redis 本质上是单线程运行,能够提供全局唯一的决策。很多原子操作的底层实现甚至是通过硬件实现的,性能非常优异,且不会产生锁竞争问题。
以 Redis 的 INCR 和 DECR 操作为例,它们可以在不加锁的情况下实现对库存的精确修改,这样能同时保证高性能和数据的一致性。
redis> decr prod_1475_stock_1
14incr、decr 这类操作就是原子的,我们可以根据返回值是否大于 0 来判断是否扣库存成功。但是这里你要注意,如果当前值已经为负数,我们需要考虑一下是否将之前扣除的补偿回来。并且为了减少修改操作,我们可以在扣减之前做一次值检测,整体操作如下:
//读取当前库存,确认是否大于零
//如大于零则继续操作,小于等于拒绝后续
redis> get prod_1475_stock_1
1
//开始扣减库存、如返回值大于或等于0那么代表扣减成功,小于0代表当前已经没有库存
//可以看到返回-2,这可以理解成同时两个线程都在操作扣库存,并且都没拿到库存
redis> decr prod_1475_stock_1
-2
//扣减失败、补偿多扣的库存
//这里返回0是因为同时两个线程都在做补偿,最终恢复0库存
redis> incr prod_1475_stock
0这个库存保护方案确实很有价值,但也有其局限性。库存的准确性依赖于业务是否能成功“返还”之前扣减的库存。如果在服务运行过程中“返还”操作被中断,人工修复将变得非常困难,因为无法确定当前还有多少库存正在处理中。通常,我们需要等到活动结束后再查看最终库存。
为了完全保证库存不丢失,通常会依赖事务和回滚机制,但 Redis 作为外置的库存服务,并不属于数据库的缓存范畴。这就要求我们在每个可能出现故障的业务环节中都能够妥善处理库存问题。因此,许多秒杀系统在出现故障时往往选择不返还库存,并不是因为不想,而是因为很多意外场景无法做到。
至于使用 SETNX 指令或数据库的 CAS(比较并交换)机制来实现互斥锁,尽管这能解决库存问题,但这种锁机制会引入自旋等待。在并发高的情况下,用户服务需要反复尝试才能获取锁,这样会浪费系统资源,并对数据服务造成较大压力。因此,这种方法并不推荐使用。
令牌库存
除了这种用数值记录库存的方式外,还有一种比较科学的方式就是“发令牌”方式,通过这个方式可以避免出现之前因为抢库存而让库存出现负数的情况。
 图片
图片
具体是使用 Redis 中的 list 保存多张令牌来代表库存,一张令牌就是一个库存,用户抢库存时拿到令牌的用户可以继续支付:
//放入三个库存
redis> lpush prod_1475_stock_queue_1 stock_1
redis> lpush prod_1475_stock_queue_1 stock_2
redis> lpush prod_1475_stock_queue_1 stock_3
//取出一个,超过0.5秒没有返回,那么抢库存失败
redis> brpop prod_1475_stock_queue_1 0.5在库存抢购失败时,用户只会收到 nil,这种实现方式确实能避免失败后还要补偿库存的问题。不过,即便如此,如果我们的业务代码在异常处理上不够完善,依然可能发生库存丢失的情况。同时,如果需要从队列中取出令牌,使用 brpop 可以阻塞等待,而使用 rpop 则在压测场景下性能表现更好,因为不需要等待。
然而,当库存数量非常庞大时,令牌方式可能并不适用。比如,如果有1万个库存,就需要插入1万个令牌到 Redis 的 list 中;如果库存有10万,就得连续插入10万个字符串,这会导致 Redis 在入库期间发生大量卡顿。
到这里,库存设计似乎已经比较完善了,但如果产品团队提出“一个商品可以一次抢多个库存”的需求(比如一次秒杀两袋大米),这个方案可能就无法满足了。因为我们依赖于多个锁来降低竞争,而一次性扣减多个库存会让这个设计变得复杂,锁争抢问题依旧存在。
多库存秒杀
其实这种情况经常出现,这让我们对之前的优化有了更多的想法。对于一次秒杀多个库存,我们的设计需要做一些调整。
 图片
图片
之前,我们为了减少锁竞争,将库存拆分成了 10 个不同的 key 并随机获取。但如果到了库存只剩下最后几个商品的极端情况,用户一次秒杀三件商品(如上例所示),可能需要尝试所有的库存 key。最终,在尝试了 10 个 key 后,可能只成功扣减了两个库存。这个时候,我们就面临选择:是拒绝用户的订单,还是返还库存?
这就取决于产品的设计思路了。同时,我们还需要增加一个检测机制:如果库存已经售罄,就不要再去尝试获取 10 个库存 key 了。毕竟,在没库存的情况下,每次请求都会刷 10 次 Redis,而这会对 Redis 服务带来较大压力。虽然 Redis 的 O(1) 操作理论上可以达到每秒 10 万次操作(OPS),但一次请求刷 10 次,理想情况下抢购库存的接口性能大约为每秒 1 万次请求(QPS)。实际压测后,建议按照实测性能的 70% 来进行漏斗式限流。
你应该注意到了,在“一个商品可以抢多个库存”的场景下,库存拆分方案并没有减少锁的争抢次数,反而增加了维护的复杂性。当库存越来越少时,系统性能会显著下降,这样的设计已经不符合我们最初的目的(这种由业务需求引发的设计不适配问题在实际项目中非常常见,需要我们在设计之初更深入地理解产品需求)。
那么,应该怎么优化呢?我们可以考虑将原来拆分的 10 个 key 合并为 1 个,然后使用 rpop 来实现多个库存的扣减操作。对于库存不足的情况(例如,用户想买 3 件但只剩 2 件库存),需要产品侧给出明确的建议,看是否继续处理交易。同时,在每次操作开始时,可以使用 LLEN(O(1) 操作)检查 list 中是否有足够的库存支持 rpop。
//取之前看一眼库存是否空了,空了不继续了(llen O(1))
redis> llen prod_1475_stock_queue
3
//取出库存3个,实际抢到俩
redis> rpop prod_1475_stock_queue 3
"stock_1"
"stock_2"
//产品说数量不够,不允许继续交易,将库存返还
redis> lpush prod_1475_stock_queue stock_1
redis> lpush prod_1475_stock_queue stock_2通过这个设计,我们已经大大降低了下单系统锁争抢压力。要知道,Redis 是一个性能很好的缓存服务,其 O(1) 类复杂度的指令在使用长链接的情况下多线程压测,5.0 版本的 Redis 就能够跑到 10w OPS,而 6.0 版本的网络性能会更好。这种利用 Redis 原子操作减少锁冲突的方式,对各个语言来说是通用且简单的。不过你要注意,不要把 Redis 服务和复杂业务逻辑混用,否则会影响我们的库存接口效率。
自旋互斥超时锁
如果我们在库存争抢时需要操作多个决策 key 才能够完成争抢,那么原子这种方式是不适合的。因为原子操作的粒度过小,无法做到事务性地维持多个数据的 ACID。这种多步操作,适合用自旋互斥锁的方式去实现,但流量大的时候不推荐这个方式,因为它的核心在于如果我们要保证用户的体验,我们需要逻辑代码多次循环抢锁,直到拿到锁为止,如下:
//业务逻辑需要循环抢锁,如循环10次,每次sleep 10ms,10次失败后返回失败给用户
//获取锁后设置超时时间,防止进程崩溃后没有释放锁导致问题
//如果获取锁失败会返回nil
redis> set prod_1475_stock_lock EX 60 NX
OK
//抢锁成功,扣减库存
redis> rpop prod_1475_stock_queue 1
"stock_1"
//扣减数字库存,用于展示
redis> decr prod_1475_stock_1
3
// 释放锁
redis> del prod_1475_stock_lock 图片
图片
这种方式的缺点在于,在抢锁阶段如果排队抢的线程越多,等待时间就越长,并且由于多线程一起循环 check 的缘故,在高并发期间 Redis 的压力会非常大,如果有 100 人下单,那么有 100 个线程每隔 10ms 就会 check 一次,此时 Redis 的操作次数就是:
100线程×(1000ms÷10ms)次=10000ops
CAS 乐观锁:锁操作后置
另外一个推荐的方式是使用 CAS(Compare and Swap)乐观锁。与自旋互斥锁相比,在并发抢库存的线程较少时,CAS 乐观锁效率更高。传统的锁机制是通过先获取锁,再对数据进行操作,这个过程中抢锁本身会消耗性能,哪怕没有其他线程参与争抢,抢锁的开销依然存在。
而 CAS 乐观锁 的核心在于记录或监控当前的库存信息或版本号,在此基础上进行预操作。当线程准备修改数据时,系统会先检查当前的库存版本号是否和预期的一致。如果一致,则修改成功;否则,重新读取最新的数据并重试。这种方式可以避免锁竞争带来的性能损耗,在并发较低的场景下更具优势。
 图片
图片
如上图,在操作期间如果发现监控的数值有变化,那么就回滚之前操作;如果期间没有变化,就提交事务的完成操作,操作期间的所有动作都是事务的。
//开启事务
redis> multi
OK
// watch 修改值
// 在exec期间如果出现其他线程修改,那么会自动失败回滚执行discard
redis> watch prod_1475_stock_queue prod_1475_stock_1
//事务内对数据进行操作
redis> rpop prod_1475_stock_queue 1
QUEUED
//操作步骤2
redis> decr prod_1475_stock_1
QUEUED
//执行之前所有操作步骤
//multi 期间 watch有数值有变化则会回滚
redis> exec
3以看到,通过这个方式我们可以批量地快速实现库存扣减,并且能大幅减少锁争抢时间。它的好处我们刚才说过,就是争抢线程少时效率特别好,但争抢线程多时会需要大量重试,不过即便如此,CAS 乐观锁也会比用自旋锁实现的性能要好。当采用这个方式的时候,我建议内部的操作步骤尽量少一些。同时要注意,如果 Redis 是 Cluster 模式,使用 multi 时必须在一个 slot 内才能保证原子性。
Redis Lua 方式实现 Redis 锁
与“事务 + 乐观锁”类似的另一种实现方式是使用 Redis 的 Lua 脚本 来进行多步骤的库存操作。由于 Lua 脚本在 Redis 内部的执行是连续且原子的,因此所有操作不会被其他操作打断,避免了锁争抢的问题。
此外,Lua 脚本可以根据不同情况灵活处理不同的操作,业务只需调用指定的 Lua 脚本并传递相关参数,就可以实现高性能的库存扣减。这样做不仅提高了操作的原子性,也显著减少了由于多次请求等待所带来的 RTT(往返时间),提升了整体系统的响应速度和并发处理能力。
为了方便演示怎么执行 Lua 脚本,我使用了 PHP 实现:
<?php
$script = <<<EOF
// 获取当前库存个数
local stock=tonumber(redis.call('GET',KEYS[1]));
//没找到返回-1
if stock==nil
then
return -1;
end
//找到了扣减库存个数
local result=stock-ARGV[1];
//如扣减后少于指定个数,那么返回0
if result<0
then
return 0;
else
//如果扣减后仍旧大于0,那么将结果放回Redis内,并返回1
redis.call('SET',KEYS[1],result);
return 1;
end
EOF;
$redis = new \Redis();
$redis->connect('127.0.0.1', 6379);
$result = $redis->eval($script, array("prod_stock", 3), 1);
echo $result;通过这个方式,我们可以远程注入各种连贯带逻辑的操作,并且可以实现一些补库存的操作。
总结
 图片
图片