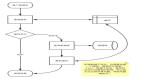
原理
布隆过滤器(Bloom Filter)是1970年由伯顿·霍华德·布隆(Burton Howard Bloom)提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash Table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n)、O(logn)、O(1)。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。
 图片
图片
检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。
 图片
图片
接下来,我们看下在Java中怎么使用。
单机版:Guava
首先引入依赖:
然后使用Guava中的BloomFilter类开始实现:
Guava实现的是单机版,虽然提供了文件写出的功能,可以将文件分发到分布式系统中,但是这种方式只能是补充。推荐只在单机场景中使用Guava的布隆过滤器。
如果想要在分布式服务中使用,可以选择Redission。
分布式版:Redission
引入依赖:
使用Docker在本地启一个Redis服务,用来验证:
然后编码测试:
使用Redission的RBloomFilter,会根据布隆过滤器名字在Redis中生成两个key,比如上面代码的名字是“myBloomFilter”,生成的配置为:
- "myBloomFilter"是string类型,布隆过滤器的主存,用来存储二进制数组;
- "{myBloomFilter}:config"是hash结构,存储元信息,比如大小size、期望容量expectedInsertions、误报率falseProbability、使用的哈希函数数量hashIterations等。