大家好,我是小寒
今天给大家分享处理不平衡数据集的常用方法。
在开始之前,我们先来了解一下什么是不平衡的数据集。
不平衡数据集是指在分类任务中,不同类别的样本数量差异显著的数据集,通常表现为少数类样本远少于多数类样本。这样的数据集在现实生活中很常见,比如欺诈检测、医疗诊断、故障预测等场景。
例如,在一个包含 10,000 个实例的数据集中,95% 属于一个类(类 0),只有 5% 属于另一个类(类 1),很明显,模型可能会高度关注多数类,而经常完全忽略少数类。
不平衡数据的问题
在不平衡的数据集中,多数类别主导着模型的预测,导致少数类别的预测性能较差。
例如,如果 95% 的数据被标记为 0 类,则将所有实例预测为 0 类可获得 95% 的准确率,即使 1 类预测完全不正确。
示例:
考虑一个欺诈检测系统,其中 99% 的交易是合法的,只有 1% 是欺诈的。预测所有交易均为合法的模型将达到 99% 的准确率,但无法检测到任何欺诈行为,使其无法达到预期目的。
让我们通过一个例子来可视化不平衡数据
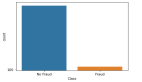
此代码生成一个不平衡的数据集,其中 95% 的实例被标记为类 0,只有 5% 被标记为类 1。
当我们可视化类别分布时,我们会看到两个类别之间的明显不平衡。
 图片
图片
混淆矩阵显示,虽然准确率很高,但少数类(类1)的准确率和召回率要低得多。该模型偏向多数类。
 图片
图片
 图片
图片
处理不平衡数据的技术
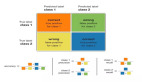
1.随机欠采样
随机欠采样是一种通过减少多数类样本的数量来平衡类分布的方法。
具体做法是随机选择部分多数类样本并将其移除,使得多数类和少数类的样本数量接近平衡。
优点
- 简单易行,不需要复杂的算法。
- 减少了数据集的规模,降低了计算成本。
缺点
- 可能丢失重要的多数类信息,导致模型性能下降。
- 缩小的数据集可能导致模型对多数类的泛化能力变差。
 图片
图片
2.随机过采样
随机过采样通过增加少数类样本的数量来平衡类分布。
常见的做法是随机复制少数类的样本,直到少数类样本的数量与多数类样本的数量相等。
优点
- 不会丢失数据,不像欠采样那样丢失多数类的样本。
- 在数据较少时,可以通过增加样本数量提高模型的学习效果。
缺点
- 由于重复样本的存在,可能导致模型过拟合少数类样本。
 图片
图片
3.SMOTE
SMOTE 是一种合成过采样方法,通过生成新的少数类样本来平衡数据集。
它不是简单地复制现有的少数类样本,而是通过对现有少数类样本的特征进行插值,创建新样本。
具体来说,SMOTE 从少数类样本中选取一个样本和其最近邻样本,在它们之间生成新的合成样本。
优点
- 通过生成新样本代替简单复制,缓解了过拟合的问题。
- 利用插值方法生成多样化的少数类样本,扩展了少数类样本的分布。
缺点
- 生成的合成样本可能落在错误的决策边界上,尤其是在样本分布不清晰时。
- 对高维数据的效果不佳,因为高维数据中的样本通常稀疏,插值生成的样本可能不具有代表性。
 图片
图片
4.成本敏感型学习
成本敏感型学习通过为分类错误分配不同的成本来解决数据不平衡问题。
在不平衡数据集中,错分少数类的代价通常比多数类更高。成本敏感型学习通过在损失函数中引入成本矩阵来调整模型,使得少数类的错分类损失更大,从而引导模型更加关注少数类。
优点
- 不需要对数据进行重采样,可以直接在模型训练中融入不平衡问题。
- 可以灵活调整不同错误分类的成本,适应不同场景的需求。
缺点:
- 成本矩阵的设置需要根据实际问题调整,具有一定的挑战性。
- 在处理严重不平衡的数据时,仍可能遇到少数类样本过少的问题。
5.平衡随机森林
平衡随机森林是在随机森林的基础上改进的一种方法,针对不平衡数据集做了优化。
它通过在构建每棵决策树时,对多数类进行随机欠采样,确保每棵树的训练集都是平衡的。同时,它结合了随机森林的特性,通过多个弱分类器的集成来提高整体的预测能力。
优点
- 保留了随机森林的优势,如高准确性和鲁棒性。
- 对多数类进行欠采样,能够减少模型对多数类的偏向,提高对少数类的预测能力。
- 集成多个决策树,具有较强的泛化能力,减少了单一模型的偏差。
缺点:
- 相比于传统随机森林,平衡随机森林的计算成本更高,因为需要对多数类进行多次欠采样。
- 欠采样过程中可能丢失多数类的重要信息,影响模型的整体表现。