select a.line_store_goods_id as line_resource_id, a.group_num as group_num, a.approval_erp as approval_erp, a.approval_person as approval_person, a.approval_status as approval_status, a.approval_time as approval_time, a.approval_remark as approval_remark, a.master_slave as master_slave, a.parent_line_code as parent_line_code, a.remarks as remarks, a.operator_time, a.same_stowage as same_stowage, b.start_org_id, b.start_org_name, b.start_province_id, b.start_province_name, b.start_city_id, b.start_city_name, b.start_node_code, b.start_node_name, b.end_org_id, b.end_org_name, b.end_province_id, b.end_province_name, b.end_city_id, b.end_city_name, b.end_node_code, b.end_node_name, b.depart_time, b.arrive_time, b.depart_wave_code, b.arrive_wave_code, b.enable_time, b.disable_time, a.store_enable_time, a.store_disable_time, a.update_name operator_name, b.line_code, b.line_type, b.transport_type,IF(a.store_enable_time > b.enable_time,IF(a.store_enable_time > c.enable_time, a.store_enable_time, c.enable_time),IF(b.enable_time > c.enable_time, b.enable_time, c.enable_time))as insect_start_time,IF(a.store_disable_time < b.disable_time,IF(a.store_disable_time < c.disable_time, a.store_disable_time, c.disable_time),IF(b.disable_time < c.disable_time, b.disable_time, c.disable_time))as insect_end_time FROM join_table
1.
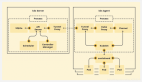
level3 - join_table
(select*FROM line_store_goods WHERE yn =1and master_slave =1) a join(select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type,min(enable_time)as enable_time,max(disable_time)as disable_time from line_resource where line_code in(select line_code from line_store_goods WHERE yn =1)and yn=1groupby line_code) b ON a.line_code = b.line_code and a.start_node_code = b.start_node_code join(select line_code,start_node_code,min(enable_time)as enable_time,max(disable_time)as disable_time from line_resource WHERE yn =1groupby line_code) c ON a.parent_line_code = c.line_code and a.start_node_code = c.start_node_code
1.
level4 - a,b,c
select*FROM line_store_goods WHERE yn =1and master_slave =1select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type,min(enable_time)as enable_time,max(disable_time)as disable_time from line_resource where line_code in(select line_code from line_store_goods WHERE yn =1)and yn=1groupby line_code
1.
2.
select line_code,start_node_code,min(enable_time)as enable_time,max(disable_time)as disable_time from line_resource WHERE yn =1groupby line_code
selectcount(*)from((select line_code FROM line_store_goods WHERE yn =1and parent_line_code = line_code and master_slave =1and start_node_code ='311F001') a join(select line_code,min(enable_time)as enable_time,max(disable_time)as disable_time from line_resource where yn=1and start_node_code ='311F001'groupby line_code) b ON a.line_code = b.line_code)where disable_time >'2023-11-15 00:00:00'and enable_time < disable_time














 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片