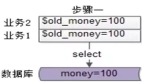
当机房 A 修改了一条数据的同时,机房 B 也对该数据进行了更新,Otter 会通过合并逻辑来处理冲突的数据行或字段,以达到合并效果。为了避免这种冲突,我们在上节课对客户端提出了要求:用户客户端在一定时间内只能连接一个机房。然而,如果业务对“事务和强一致性”有极高的需求,例如库存不允许超卖的场景,通常只有两种选择:一种是将服务部署为本地服务,但这并不适用于所有业务;另一种是使用多机房架构,但必须采用分布式强一致性算法以确保多个副本之间的一致性。
在业界,最知名的分布式强一致性算法是 Paxos。尽管它的原理非常抽象,经过多次修改后往往会与最初设计产生很大偏离,使得很多人难以判断这些修改是否合理。通常需要一到两年的实践经验才能完全掌握该算法。随着对分布式多副本同步需求的增加,Paxos 的抽象性已无法完全满足市场需求,因此 Raft 算法应运而生。相比于 Paxos,Raft 更易于理解,同时能够保证操作的顺序一致性,因此被广泛应用于分布式数据服务中,像 etcd 和 Kafka 等知名基础组件都使用了 Raft 算法。
如何选举 Leader?
 图片
图片
如图所示,我们启动了五个 Raft 分布式数据服务节点:S1、S2、S3、S4 和 S5。每个节点可以处于以下三种状态之一:
- Leader:负责处理数据修改,并主动将变更同步到其他 Follower 节点。
- Follower:接收并应用 Leader 推送的变更数据。
- Candidate:当集群中没有 Leader 时,Follower 节点会进入选举模式。
如果某个 Follower 节点在规定时间内未收到 Leader 的心跳信号,则意味着当前 Leader 可能已失效,集群无法继续更新数据。在这种情况下,Follower 节点会进入选举模式,并在多个 Follower 节点之间选出一个新的 Leader,确保服务集群中始终有一个 Leader,确保数据变更的唯一决策进程。
那么 Leader 是如何选举出来的呢?在进入选举模式后,这五个节点会各自随机等待一段时间。等待时间一到,当前节点会先为自己投一票,并将其任期(term)加 1(如图中的 term:4 表示第四任 Leader),然后通过发送 RequestVote RPC(即请求投票的远程过程调用)向其他节点拉票。
 图片
图片
S1失去联系,S5最先超时发起选举
当服务节点收到投票请求时,如果该请求节点的任期和日志同步进度都领先或相同,则会向其投票,并将自己的当前任期更新为新的任期。在此期间,收到投票请求的节点将不会再发起投票,而是等待其他节点的投票邀请。需要注意的是,每个节点在同一任期内只能投出一票。
如果所有节点在选举过程中都未获得多数票(即超过半数的票数),则在选举超时后,节点会将任期加 1 并重新发起选举。最终,获得多数票且最早结束选举倒计时的节点将当选为新的 Leader。该 Leader 随即广播通知其他节点,并同步新的任期和日志进度。
在成为 Leader 后,新的 Leader 会定期发送心跳信号,确保各个 Follower 节点保持连接状态,不因超时而进入选举模式。在选举过程中,如果有节点收到了前一任 Leader 的心跳信号,便会停止当前的选举并拒绝新的选举请求。选举结束后,所有节点进入数据同步状态,确保日志一致性。
如何保证多副本写一致?
当服务节点收到投票请求时,如果该请求节点的任期和日志同步进度都领先或相同,则会向其投票,并将自己的当前任期更新为新的任期。在此期间,收到投票请求的节点将不会再发起投票,而是等待其他节点的投票邀请。需要注意的是,每个节点在同一任期内只能投出一票。
如果所有节点在选举过程中都未获得多数票(即超过半数的票数),则在选举超时后,节点会将任期加 1 并重新发起选举。最终,获得多数票且最早结束选举倒计时的节点将当选为新的 Leader。该 Leader 随即广播通知其他节点,并同步新的任期和日志进度。
在成为 Leader 后,新的 Leader 会定期发送心跳信号,确保各个 Follower 节点保持连接状态,不因超时而进入选举模式。在选举过程中,如果有节点收到了前一任 Leader 的心跳信号,便会停止当前的选举并拒绝新的选举请求。选举结束后,所有节点进入数据同步状态,确保日志一致性。
 图片
图片
具体来说,当 Leader 成功修改数据后,它会生成一条对应的日志,并将该日志发送给所有 Follower 节点进行同步。只要超过半数的 Follower 返回同步成功的反馈,Leader 就会将该预提交的日志正式提交(commit),并向客户端确认数据修改成功。
在下一个心跳中,Leader 会通过消息中的 leader commit 字段,将当前最新提交的日志索引(Log index)告知各 Follower 节点。Follower 节点依据该提交的索引更新数据,仅对外提供被 Leader 最终提交的数据,未被提交的数据不会被持久化或展示。
如果在数据同步期间,客户端继续向 Leader 发送其他修改请求,这些请求会进入队列等待处理,因为此时 Leader 正在等待其他节点的同步响应,导致暂时的阻塞。
 图片
图片
不过,这种阻塞等待的设计使得 Raft 算法对网络性能的依赖性较强,因为每次数据修改都需要向多个节点发出并发请求,等待大多数节点成功同步。最糟糕的情况是,返回的往返时延(RTT)会受到最慢节点的网络响应时间影响,例如“两地三中心”的一次同步时间可能达到约 100ms。此外,由于主节点只有一个,这限制了 Raft 服务的整体性能。
为了解决这个问题,我们可以通过减少数据量和对数据进行切片来提升集群的修改性能。需要注意的是,当大多数 Follower 与 Leader 的日志进度差异过大时,数据变更请求将会处于等待状态,直到超过一半的 Follower 与 Leader 的进度一致后,才会返回修改成功的结果。当然,这种情况并不常见。
服务之间如何同步日志进度?
讲到这我们不难看出,在 Raft 的数据同步机制中,日志发挥着重要的作用。在同步数据时,Raft 采用的日志是一个有顺序的指令日志 WAL(Write Ahead Log),类似 MySQL 的 binlog。该日志中记录着每次修改数据的指令和修改任期,并通过 Log Index 标注了当前是第几条日志,以此作为同步进度的依据。

在 Raft 中,Leader 节点的日志是永久保留的,所有 Follower 节点会与 Leader 保持完全一致。如果出现差异,Follower 的日志将被强制覆盖以与 Leader 同步。此外,每条日志记录都经过“写入”和“提交”(commit)两个阶段。在选举过程中,每个节点会基于自身未提交的日志索引(Log Index)进度优先选择进度最靠前的节点,从而确保当选的 Leader 拥有最新、最完整的数据。
在 Leader 任期内,它会按顺序向各 Follower 节点推送日志以实现同步。若 Leader 的同步进度领先于某个 Follower,该 Follower 将拒绝同步请求。收到拒绝反馈后,Leader 会从日志末尾向前回溯,找出 Follower 未同步或存在差异的日志部分,然后逐条推送覆盖,直到 Follower 与 Leader 保持一致。
 图片
图片
Leader 和 Follower 的日志同步进度是通过日志索引(index)来确认的。Leader 对日志的内容和顺序拥有绝对的决策权,当发现自己的日志与某个 Follower 的日志存在差异时,为了确保多个副本的数据完全一致,Leader 会强制覆盖该 Follower 的日志。
那么,Leader 是如何识别 Follower 的日志与自己的日志之间的差异呢?在向 Follower 同步日志时,Leader 会同时提供自己上一条日志的任期和索引号,与 Follower 当前的同步进度进行比较。对比主要涉及两个方面:
- 当前日志对比:Leader 会对比自己和 Follower 的当前日志中的索引、多条操作日志和任期。
- 上一条日志对比:Leader 会对比自己和 Follower 的上一条日志的索引和任期。
如果以上任意一个方面存在差异,Leader 就会认为 Follower 的日志与自己的日志不一致。在这种情况下,Leader 会逐条倒序对比日志,直到找到日志内容和任期完全一致的索引,然后从这个索引开始按顺序向下覆盖。
在日志同步期间,Leader 只会提交其当前任期内的数据,之前任期的数据则依赖日志同步来逐步恢复。可以看到,这种逐条推送的同步方式效率较低,特别是对新启动的服务并不友好。因此,Leader 会定期生成快照,将之前的修改日志记录合并,以降低日志的大小。同时,进度差距过大的 Follower 会从 Leader 的最新快照中恢复数据,并按快照最后的索引追赶进度。
如何保证读取数据的强一致性?
通过前面的讲解,我们了解了 Leader 和 Follower 之间的同步机制,那么从 Follower 的角度来看,它又是如何确保自己对外提供的数据始终是最新的呢?这里有一个小技巧:当 Follower 收到查询请求时,会同时向 Leader 请求当前最新提交的日志索引(commit log index)。如果这个日志索引大于 Follower 当前的同步进度,就意味着 Follower 的本地数据不是最新的。此时,Follower 会从 Leader 获取最新的数据并返回给客户端。
由此可见,保持数据的强一致性需要付出较大的代价。
 图片
图片
你可能会好奇:如何在业务使用时保证读取数据的强一致性呢?其实我们之前说的 Raft 同步等待 Leader commit log index 的机制,已经确保了这一点。我们只需要向 Leader 正常提交数据修改的操作,Follower 读取时拿到的就一定是最新的数据。
总结
很多人都说 Raft 是一个分布式一致性算法,但实际上 Raft 算法是一个共识算法(多个节点达成共识),它通过任期机制、随机时间和投票选举机制,实现了服务动态扩容及服务的高可用。通过 Raft 采用强制顺序的日志同步实现多副本的数据强一致同步,如果我们用 Raft 算法实现用户的数据存储层,那么数据的存储和增删改查,都会具有跨机房的数据强一致性。这样一来,业务层就无需关心一致性问题,对数据直接操作,即可轻松实现多机房的强一致同步。