一、前言
在前几篇文章中,我们在分析线程池和ReentrantLock的时候,其内部实现大量用到了volatile关键字来修饰变量,前面我们也简单分析过使用volatile是为了用它的内存可见性。除了内存可见性,它还有哪些能力呢?这篇文章来详细告诉你。
二、大象装进冰箱的case
给你一台足够大的冰箱,把大象塞进去至少需要三步,第一步打开冰箱门,第二步将大象搬进去,第三步将冰箱门关上。我们来假设一个场景:冰箱只有一台且同一时刻只能放入一只大象,但在某一时刻有5只大象都要进入冰箱降暑,那么在大象装进冰箱这件事情的整个过程中,中间任一步骤失败就会直接导致整件事情的失败。如果不想存在中间过程中出现失败的可能,只有一个办法这件事件的三个步骤合三为一,使其成为一个整体,从外部看就像只有一个“将大象塞进冰箱”动作。我们在多线程环境下对一个变量进行操作时,会经常遇到这种问题,下面我们来看看如何完美解决。
二、Java内存模型
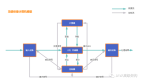
想要完美解决多线程下对同一变量进行安全操作,我们得先要了解清楚Java内存模型,内存模型如下图所示
 图片
图片
- Java内存模型规定了所有的变量都必须存储在主内存中,而每条工作线程有自己的工作内存,工作内存中存储的的是该线程执行过程中临时用到的变量信息,这些信息都是从主内存中拷贝的副本,另外线程对变量的所有操作行为都必须在工作内存完成,而不能直接操作主内存中的变量信息。
- 不同线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需通过自己的工作内存和主内存之间进行数据交互,然后再传递到别的线程工作内存中完成信息的交互。
小结:JMM(Java Memory Model)是一种规范,目的是解决由于多线程通过共享内存进行通信时,存储在工作内存的数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
三、volatile三大属性
2.1 原子性
2.1.1 volatile为什么不能保证原子性
/**
* @author 程序反思录 <程序反思录@xxx.com>
* Created on 2024-09-29
*/
public class MultiThreadCount {
private volatile int salesCount = 0;
public void addSalesCount() {
salesCount++;
}
public static void main(String[] args) {
MultiThreadCount multiThreadCount = new MultiThreadCount();
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
multiThreadCount.addSalesCount();
}
}).start();
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
multiThreadCount.addSalesCount();
}
}).start();
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
multiThreadCount.addSalesCount();
}
}).start();
System.out.println(multiThreadCount.salesCount);
}
}运行上面这段代码,在不同的机器上得到的结果大概率都不一样且结果值都不是3000。
现在我们再回过头来分析上面的那段示例代码,刚开始3个线程分别从主内存copy salesCount=0到各自的工作内存中去,然后分别执行自增操作,完后后将各自的值刷回到主内存,一次salesCount自增操作会涉及三步操作(就像将大象放入冰箱的case一样),多个线程同时多次执行这三步操作势必会造成主内存中值被覆盖情况,这也就解释了volatile没能保证原子性的原因。
2.1.2 如何实现原子性
解决上面的问题很容易,只需要将salesCount的修饰由volatile改成就可以了,代码如下
private AtomicInteger salesCount = new AtomicInteger(0);
public void addSalesCount() {
salesCount.incrementAndGet();
}有同学就会好奇了,为什么AtomicInteger就可以解决数据被刷回到主内存后数据被覆盖的问题呢?点开AtomicInteger的源码会有有两个关键的动作:
- AtomicInteger内部维护的value属性是用volatile修饰的,利用其内存可见性的特性使得值被修改后,别的线程能够及时感知到(后面分析内存可见性的时候再展开)
- 使用了CAS特性加死循环来保证值不会被覆盖,并将当前最新值累加上去刷回到主内存,我们稍微展开分析一下具体实现
// 调用该方法对计数器进行+1操作
public final int incrementAndGet() {
// 通过unsafe类实现原子加+1操作
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
// 1. 首先通过CAS尝试将+1后的数据写入到工作线程,
// 然后回写到主内存(这里会通过lock指令强制将修改后的值回写到主内存,
// 下面分析可见性的时候在展开)。
// 2. 如果CAS操作失败了,通过while死循环不断自旋,直到最新值被成功回写到主内存,
// 说点题外话,相信看过线程池和ReentrantLock文章的同学会有感觉,
// 一般CAS出现的地方,会伴随着死循环的身影出现。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}2.2 内存可见性
2.2.1 什么是内存可见性
内存可见性(Memory Visibility)是指在一个线程中修改了某个变量的值之后,这些修改能够被其他线程立即看到。在多线程环境中,由于每个线程可能有自己的工作内存(缓存),而不是直接操作主内存,因此会出现内存可见性问题。
2.2.2 volatile是如何解决内存可见性的问题
当对volatile修饰的变量进行修改时,JVM会向处理器发送一条lock前缀的指令,将当前处理器中缓存的最新值强制写回到主存中,所有处理器都需要遵守缓存一致性协议,当其他处理器发现自己缓存的数据已经被修改,则会从主存中拉取最新的值缓存到自己的缓存内,从而实现了可见性的特性。 缓存一致性协议:每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是否已过期,当处理器发现自己缓存行的内存地址被修改,就会将当前处理器的缓存设置成无效状态,当处理器要对这个数据进行修改操作时,会强制从主存读取最新数据写入到处理器缓存中。
2.2.3 解决内存可见性问题的替代方案
i) 通过锁来解决同一时刻只有一个线程可以修改值
- 使用synchroized关键字,保证多个线程操作时,只有抢到锁的线程才可以执行修改操作
- 使用Atomic类,通过CAS+死循环的方式
ii) 使用final关键字修饰,使得变量不能被修改,从而避开了内存可见性问题的发生
2.3 指令重排
2.3.1 什么是指令重排
指令重排是指编译器、运行时系统或处理器为了优化性能,对程序中的指令顺序进行调整的过程。
2.3.2 指令重排有什么好处
i) 编译器优化:编译器可能会对代码进行重排序,以减少寄存器的使用、提高指令流水线的效率等。
ii) 运行时系统优化:运行时系统可能会对字节码进行优化,以提高执行效率。
iii) 处理器优化:现代处理器具有复杂的流水线和多级缓存,可能会对指令进行重排序以提高性能。
2.3.3 为什么volatile禁止指令重排
大多数情况下指令重排这种优化操作是透明的,但在多线程环境中,指令重排可能会导致一些问题 i) 内存可见性问题:由于指令执行顺序被重排,使得修改操作被延迟触发,最终导致一个线程对变量的修改可能不会理解对其他线程可见。ii) 竞态条件:指令重排可能导致两个线程之间的操作顺序不符合预期,从而引发竞态条件。
2.3.4 禁止指令重排是如何实现的
禁止指令重排序是通过内存屏障来实现的。内存屏障是一种特殊的指令,它可以确保某些操作在屏障前后按照特定的顺序执行,从而防止编译器、运行时系统和处理器对这些操作进行重排序。内存屏障分为两种:i) 写屏障:在写操作之后插入一个写屏障,确保所有之前的写操作都已完成并回写到主内存中。ii) 读屏障:在读操作之前插入一个读屏障,确保所有后续的读操作都从主内存中读取最新的值。
四、后续
本篇文章从volatile的特性展开,介绍到了Java的JMM(Java内存模型)模型,有些同学这个时候心里就要开始迷糊了,我听过Java对象模型、JVM内存模型,那它们又是干什么用的呢?我知道你很急,但是你不用急,下篇文章接着解答的疑惑。