












在自然语言处理、语音识别和时间序列分析等众多领域中,序列建模是一项至关重要的任务。然而,现有的模型在捕捉长程依赖关系和高效建模序列方面仍面临诸多挑战。
因此,北京大学林宙辰、徐鑫提出了一种全新混合序列建模架构 ——MixCon,它为解决这些难题带来了创新性的方案。经实验验证,其性能远超 Mixtral、Mamba 和 Jamba。论文已在 European Conference on Artificial Intelligence (ECAI) 2024 上发表。
- 论文标题:MixCon: A Hybrid Architecture for Efficient and Adaptive Sequence Modeling
- 论文地址:https://zhouchenlin.github.io/Publications/2024-ECAI-MixCon.pdf
一、现有序列建模模型的困境
线性注意力 Transformer
线性注意力 Transformer 旨在通过近似注意力机制来提高原始 Transformer 模型的效率,将计算复杂度从 降低到
降低到 或
或 ,但在处理长序列时可能会面临性能下降和计算开销增加的问题。
,但在处理长序列时可能会面临性能下降和计算开销增加的问题。
例如,早期利用局部敏感哈希方案虽降低复杂度,但引入大常数因子;近期通过改变计算顺序等方法近似 Softmax 函数,但仍存在性能不如 Softmax 注意力且可能增加额外开销的情况。
线性 RNN 模型
线性 RNN 模型如 Mamba 等通过将序列表示为状态空间并利用扫描操作,以线性时间复杂度提供了序列建模的新解决方案。
然而,它们可能缺乏复杂序列建模任务所需的适应性和动态特性,并且像传统序列模型一样,缺少反馈机制和自适应控制。
MoE 模型
MoE 模型通过结合专家模块,能有效处理长序列并保持计算效率,根据输入数据自适应选择专家模块。
但 MoE 模型的专家模块稀疏激活可能导致训练稳定性问题,部分参数不常使用降低参数效率,在处理长序列时可能在计算效率和训练稳定性方面面临挑战,且对动态变化适应性不足。
二、MixCon 的核心架构与技术
Conba 模型架构
1. 状态空间方程
Conba 将序列建模任务表示为状态空间系统,状态空间定义为 和
和 ,其中
,其中 、
、 和
和 分别为时间步
分别为时间步 的状态、输入和输出,
的状态、输入和输出, 和
和 是非线性函数,可由神经网络近似。
是非线性函数,可由神经网络近似。
 ,其中
,其中 和
和 是可学习参数矩阵。
是可学习参数矩阵。 ,
, 是可学习参数矩阵。
是可学习参数矩阵。
为处理长序列,Conba 采用选择性状态空间机制 ,以及引入延迟状态
,以及引入延迟状态 和动态状态缩放机制
和动态状态缩放机制 。
。
最后状态空间系统表示为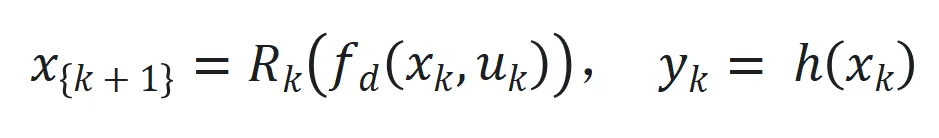 来捕捉长程依赖和适应序列动态变化。
来捕捉长程依赖和适应序列动态变化。
2. 自适应控制机制
设计目标是最小化实际输出 和期望输出
和期望输出 之间的跟踪误差
之间的跟踪误差 。
。
控制增益矩阵 通过
通过 更新,其中
更新,其中 是跟踪误差向量
是跟踪误差向量 的 2 范数,
的 2 范数, 是学习率。
是学习率。
3. 实施细节

4. 模型架构图如下所示:

MixCon 模型架构
MixCon 是结合注意力机制的 Transformer 层、Conba 层和 MoE 组件的创新混合解码器架构。
在内存使用方面,通过平衡注意力和 Conba 层,相比 Mamba 可将 KV 缓存减少 32 倍。例如,在 256K 令牌上下文环境中,MixCon 仍能保持较小的 KV 缓存优势(如表 1 所示)。

在吞吐量方面,处理长序列时,Conba 层计算效率更高,增加其比例可提高整体吞吐量。
基本配置单位是 MixCon 块,由 Conba 或注意力层组合而成,每个层包含注意力模块或 Conba 模块,后接 MLP 或 MoE 层。MixCon 中的 MLP 层被 MoE 层替换,以增加模型容量同时保持较低计算负载。
对于 Conba 层实施,采用 RMSNorm 等技术,模型词汇量为 256K,使用 BPE 进行训练,每个数字为单独令牌。
模型架构图如下所示:

三、MixCon 的实验与评估
实施细节
选择特定配置适应单块 80GB A800 NVIDIA GPU 的计算能力,实现质量和吞吐量的优化。
序列由 4 个 MixCon 块组成,每个 MixCon 块含 8 层 L = 8,注意力层和 Conba 层比例为 2:6 (a:c = 2:6),每隔一层 (e = 2) 用 MoE 替换 MLP 模块,模型有 16 个专家 (n = 16),每个令牌使用 2 个顶级专家 (K = 2)。
上下文长度分析
MixCon 在单块 80GB A800 GPU 上的最大上下文长度是 Jamba 的两倍、Mixtral 的四倍、Llama - 2 - 70B 的十四倍(如图 3 所示)。

吞吐量分析
1. 配置一:考虑不同批大小,在单块 A800 80GB GPU(int8 量化)、8K 上下文长度下生成 512 个输出令牌,MixCon 吞吐量是 Mixtral 的三倍、Jamba 的两倍(如图 4 所示)。

2. 配置二:单批次(批大小 = 1)、四块 A800 GPUs(无量化)、不同上下文长度下生成 512 个输出令牌,处理 128K 令牌时,MixCon 吞吐量是 Jamba 的 1.5 倍、Mixtral 的 4.5 倍(如图 5 所示)。

数据集评估
本文在一系列标准学术基准测试中评估 Conba 性能,包括常识推理任务(如 HellaSwag、WinoGrande、ARC - E、ARC - Challenge)、阅读理解任务(如 BoolQ、QuAC)、聚合基准测试(如 MMLU、BBH),采用不同的学习策略。
MixCon 性能与类似或更大规模的先进公开模型相当或更优,尽管总参数比 Llama - 2 少,但作为稀疏模型,其活跃参数仅 5B,处理长序列时 KV 缓存仅需 2GB,而 Mixtral 需 32GB(如表 2 所示)。

消融实验
展示注意力和 Conba 层结合的优势及最佳比例和交织技术。纯 Conba 模型在上下文学习有困难,Attention - Conba 混合模型有类似纯 Transformer 模型的上下文学习能力。
以 HellaSwag(10 - shot)、WinoGrande(5 - shot)、Natural Questions(NQ,5 - shot)为指标,MixCon 表现稳健(如表 3 所示),MixCon(无 MoE)训练过程损失更低(如图 6 所示)。

长上下文评估
利用问答基准测试评估 MixCon 处理长上下文能力,使用 L - Eval 中最长上下文数据集的五个数据集,以少样本格式(每个实验用三个例子)进行实验。
在 NarrativeQA、LongFQA、Natural Questions(NQ)、CUAD 等数据集上评估,MixCon 在多数数据集上优于 Mixtral 和 Jamba,平均性能优越,且在长上下文任务中具有更好的吞吐量(如表 4 所示)。

结合注意力和 Conba 的优势及混合专家的影响
1. 注意力和 Conba 比例研究
用 13 亿参数模型在 2500 亿令牌上训练,MixCon 性能优于纯注意力或纯 Mamba,注意力和 Conba 层比例为 2:6 或 1:7 时性能差异小(如表 5 所示)。
2. 混合专家的影响
当在 MixCon 架构的大规模情境(5B 参数,在 50B 令牌上训练)中应用 MoE 技术时,性能有显著提升(如表 6 所示)。

四、MixCon 的优势与展望
MixCon 作为创新的混合序列建模架构,通过整合多种技术,在处理复杂动态序列时具有高效的计算效率,在各项任务中展现出显著优势,能高效处理长序列、内存使用低且吞吐量高,具有高可扩展性和实用性。然而,它仍有改进空间,如进一步优化状态空间表示、长序列的自适应控制、特定领域微调以及训练算法等。
总体而言,MixCon 为序列建模提供了新的解决方案,在复杂序列处理方面表现出色,为 NLP 及其他领域的应用开辟了新道路。未来,我们期待它在更多领域发挥更大的作用,为技术发展带来更多的突破和创新。


























