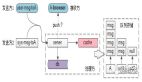
今天我们来深入探讨Kafka中的延迟处理机制,即通过DelayedOperation来实现的延时处理请求。具体来说,Kafka使用了一种名为“分层时间轮”的数据结构来管理延时任务,并通过它实现了对延迟请求的高效处理。这种延时机制广泛应用于Kafka的各个模块,比如控制器、分区管理、副本同步等。
本节课我们将通过分析Kafka的相关源码,详细讲解DelayedOperation是如何在Broker中延时处理请求的。同时,我们还会讲解两个关键类:Timer和SystemTimer,看看它们是如何与Kafka的整体框架结合的。
一、Kafka延时处理机制概述
Kafka中延迟请求的处理场景非常多,比如:
- 消费者组协调器:处理消费者组中的成员加入和离开时的超时。
- 控制器:在处理集群元数据的变化时需要对副本分配、Leader选举进行延时操作。
- 副本管理:当副本与Leader失联时,需要延迟一段时间再决定是否剔除该副本。
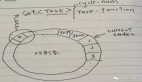
Kafka为了应对这些场景,使用了一种高效的延时处理机制:分层时间轮(Hierarchical Timing Wheels)。这个数据结构通过将延时任务按照超时时间分层存储,极大地提高了处理大量延时任务的性能。
1.1 什么是分层时间轮?
分层时间轮是一种常用于处理延迟任务的数据结构,它的核心思想是将时间分为一系列固定大小的时间槽(Bucket),每个槽对应一个时间段。延时任务会根据它的超时时间被放入相应的时间槽中,时间轮会随着时间推移不断向前转动,每当转到某个时间槽时,执行其中的所有任务。
Kafka实现的分层时间轮有多个层次,每一层的时间槽覆盖不同的时间范围。随着层次的增加,每个时间槽覆盖的时间也逐渐变大。这样设计的好处是,可以通过较少的层次和时间槽来管理大范围的延时任务。
二、核心类:Timer 和 SystemTimer
在Kafka中,延时任务的管理由两个关键类负责:
- Timer:这是时间轮的抽象接口,定义了延时任务的调度方法。
- SystemTimer:这是Timer的具体实现,使用分层时间轮来管理任务。
接下来,我们通过源码详细了解这两个类的实现。
2.1 Timer接口
首先来看Timer接口,这是Kafka中用于管理延时任务的通用接口。它的主要方法包括:
public interface Timer {
/**
* 添加一个延时操作到定时器中。
*/
void add(DelayedOperation operation);
/**
* 触发到期的延时操作。
*/
boolean advanceClock(long timeoutMs) throws InterruptedException;
/**
* 检查定时器中是否有待执行的操作。
*/
int size();
/**
* 关闭定时器。
*/
void shutdown();
}- add(DelayedOperation operation):将一个延时任务添加到时间轮中。
- advanceClock(long timeoutMs):推进时间轮的时钟,触发已经到期的延时任务。
- size():返回当前定时器中未执行的任务数。
- shutdown():关闭定时器,停止任务调度。
Timer接口为Kafka中所有延时任务的管理提供了统一的抽象,各个模块的延时任务都通过这个接口进行调度。
2.2 SystemTimer类
SystemTimer是Timer接口的具体实现,它使用了分层时间轮来管理延时任务。我们来看一下它的主要实现:
public class SystemTimer implements Timer {
private final String executorName;
private final TimerTaskList[] timeWheel;
private final long tickMs;
private final int wheelSize;
private final long startMs;
// 构造函数,初始化时间轮
public SystemTimer(String executorName, long tickMs, int wheelSize) {
this.executorName = executorName;
this.tickMs = tickMs;
this.wheelSize = wheelSize;
this.timeWheel = new TimerTaskList[wheelSize];
this.startMs = System.currentTimeMillis();
// 初始化时间轮的每个Bucket
for (int i = 0; i < wheelSize; i++) {
timeWheel[i] = new TimerTaskList();
}
}
@Override
public void add(DelayedOperation operation) {
long expiration = operation.expirationMs();
long delayMs = expiration - System.currentTimeMillis();
int bucketIndex = (int) ((delayMs / tickMs) % wheelSize);
timeWheel[bucketIndex].add(operation);
}
@Override
public boolean advanceClock(long timeoutMs) {
long currentTimeMs = System.currentTimeMillis();
int currentBucket = (int) ((currentTimeMs - startMs) / tickMs % wheelSize);
// 处理当前 Bucket 中的到期任务
timeWheel[currentBucket].advance();
return true;
}
@Override
public int size() {
int size = 0;
for (TimerTaskList taskList : timeWheel) {
size += taskList.size();
}
return size;
}
@Override
public void shutdown() {
// 清理所有未完成的任务
}
}SystemTimer的核心成员变量包括:
- tickMs:时间轮的最小时间间隔,也就是时间轮每次转动的步长。
- wheelSize:时间轮中时间槽的数量。
- timeWheel[]:时间轮的数组,每个元素对应一个时间槽(Bucket),用来存储延时任务。
2.2.1 add()方法
add()方法用于将延时任务添加到时间轮中。它通过计算任务的超时时间,确定该任务应该存放在哪个时间槽中。计算方式是根据当前时间和任务的超时时间,确定需要经过多少个tick,然后取模得到对应的时间槽。
long expiration = operation.expirationMs();
long delayMs = expiration - System.currentTimeMillis();
int bucketIndex = (int) ((delayMs / tickMs) % wheelSize);
timeWheel[bucketIndex].add(operation);这样,Kafka可以将延时任务按超时时间分布到不同的时间槽中,随着时间轮的转动逐渐触发这些任务。
2.2.2 advanceClock()方法
advanceClock()方法用于推进时间轮的时钟。当时间轮的时钟前进时,会检查当前时间槽中的任务,触发已经到期的任务。
long currentTimeMs = System.currentTimeMillis();
int currentBucket = (int) ((currentTimeMs - startMs) / tickMs % wheelSize);
timeWheel[currentBucket].advance();这个方法会计算当前的时间槽索引,并处理当前槽中的任务。Kafka通过不断推进时间轮的时钟,逐步触发延时任务的执行。
2.2.3 TimerTaskList类
时间轮中的每个时间槽是一个TimerTaskList对象,它存储了当前槽中的所有延时任务。TimerTaskList类的实现如下:
public class TimerTaskList {
private final List<DelayedOperation> tasks = new LinkedList<>();
// 添加任务
public void add(DelayedOperation operation) {
tasks.add(operation);
}
// 触发到期任务
public void advance() {
Iterator<DelayedOperation> iterator = tasks.iterator();
while (iterator.hasNext()) {
DelayedOperation task = iterator.next();
if (task.isExpired()) {
task.run();
iterator.remove();
}
}
}
public int size() {
return tasks.size();
}
}TimerTaskList通过链表存储延时任务,并在时钟推进时检查任务是否到期,执行到期任务并将其从列表中移除。
三、Kafka中的延迟处理示例
接下来我们结合Kafka的具体场景,来看一下DelayedOperation是如何被应用的。一个典型的例子就是消费者组协调器(GroupCoordinator)中的延迟处理。
3.1 消费者组协调器中的延迟请求
在Kafka的消费者组管理中,延迟请求被广泛应用。比如,当一个消费者加入或离开消费者组时,协调器需要等待一段时间,直到确定没有其他消费者的变更请求,这时就需要使用延迟操作来处理请求。
在GroupCoordinator中,有一个completeJoinGroupRequest()方法,它通过延迟操作来管理消费者加入组的请求:
public void completeJoinGroupRequest(String groupId, int memberId, long timeoutMs) {
DelayedJoinGroup delayedJoin = new DelayedJoinGroup(groupId, memberId, timeoutMs);
this.timer.add(delayedJoin);
}这里DelayedJoinGroup是`
DelayedOperation的一个子类,用来处理消费者加入组的逻辑。它会被添加到timer`中,并在超时后触发执行。
3.2 DelayedOperation类
DelayedOperation是Kafka中所有延迟任务的基类,定义了延迟任务的基本行为。它的核心方法如下:
public abstract class DelayedOperation {
private final long deadlineMs;
public DelayedOperation(long timeoutMs) {
this.deadlineMs = System.currentTimeMillis() + timeoutMs;
}
// 检查任务是否超时
public boolean isExpired() {
return System.currentTimeMillis() >= deadlineMs;
}
// 执行任务
public abstract void run();
}DelayedOperation通过isExpired()方法判断任务是否超时,并通过run()方法执行任务。Kafka中很多延时任务都是基于这个类实现的。
四、总结
通过分析Kafka中的Timer和SystemTimer类,我们深入了解了Kafka如何通过分层时间轮实现高效的延时任务调度机制。Kafka的延时处理不仅应用于消费者组协调器,还广泛用于副本管理、控制器等模块。
延时处理机制通过将任务分层存储,极大地提高了Kafka处理大量延时任务的性能。这种机制的设计既简洁又高效,适用于大规模分布式系统的延时任务处理需求。