Elasticsearch 是一个功能强大的分布式搜索引擎,广泛应用于全文检索、实时分析等场景。
尽管如此,像任何复杂系统一样,它也会遇到一些运行问题,其中较为常见且影响较大的就是 cluster_block_exception 错误。
本文将深入解析这种错误的常见原因、如何排查问题以及如何有效解决。
我们将为你提供一套简明的解决方案,帮助你轻松应对这个问题。
一、什么是 cluster_block_exception 错误?
cluster_block_exception 是 Elasticsearch 中的一种错误,通常表示集群由于某种状态阻止了某些操作的执行。
这是 Elasticsearch 的一种保护机制,避免数据丢失或系统崩溃。
常见的触发原因包括磁盘空间不足、集群健康状态不佳、节点故障或不正确的索引设置。
1. 磁盘空间不足
- 问题描述:
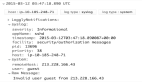
Elasticsearch 内置了磁盘空间警戒水位线机制,当磁盘空间不足时,系统会阻止数据写入,以保护集群的完整性。这是最常见的 cluster_block_exception 触发原因。
 图片
图片
- 如何检查磁盘空间:
使用以下命令检查集群各节点的磁盘使用情况:
GET _cat/allocation?v如果某个节点的磁盘使用率超过高水位线,Elasticsearch 会阻止进一步写入数据。
 图片
图片
 图片
图片
- 解决方法:
增加磁盘空间。删除不必要的旧索引:
DELETE /index_name2. 集群健康问题
- 问题描述:
当集群的健康状态变为 yellow 或 red 时,某些操作可能会被阻止。
yellow 表示副本分片未完全分配,而 red 则表明主分片不可用或丢失。
 图片
图片
- 如何检查集群健康状态:
GET _cluster/health如果集群状态为 yellow 或 red,这表明有潜在的集群健康问题需要解决。
- 解决方法:
确保所有节点正常运行,使用以下命令检查节点状态:
GET _cat/nodes?v 图片
图片
如果节点存在问题,检查硬件或网络问题,并重新启动故障节点。
重新分配分片以恢复集群健康:
POST /_cluster/reroute优化集群配置,如增加副本分片数。
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-reroute.html
3. 节点故障
- 问题描述:
节点故障通常是由于硬件、网络或资源不足引起的。
当一个或多个节点出现故障时,可能会导致 cluster_block_exception,因为部分分片变得不可用。
- 如何识别节点故障:
GET _cat/nodes?v 图片
图片
通过检查节点的状态和资源使用情况,尤其是 CPU 和内存,确定哪些节点可能出现问题。
- 解决方法:
重新启动出现故障的节点。
检查并解决硬件或网络问题,确保节点可以正常通信。
确保 Elasticsearch 进程有足够的系统资源(CPU、内存等)。
4. 集群或索引被设置为只读
- 问题描述:
有时,Elasticsearch 集群或索引可能被错误地设置为只读模式,尤其是在磁盘空间不足时。
message [ElasticsearchException[Elasticsearch exception [type=cluster_block_exception, reasnotallow=blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];]]]此时,所有写操作都会被阻止,导致 cluster_block_exception。
- 如何检查集群是否为只读:
GET /_cluster/settings 图片
图片
检查 cluster.blocks.read_only 或 cluster.blocks.read_only_allow_delete 是否为 true。
- 解决方法:
将集群或索引设置为可写:
PUT /_cluster/settings
{
"persistent": {
"cluster.blocks.read_only": false
}
}或者,移除索引的只读设置(常见移除基本都是设置 null,其他类似命令可以参见如下):
PUT /index_name/_settings
{
"index.blocks.read_only_allow_delete": null
}5. 索引设置问题
- 问题描述:
有时,错误的索引设置(例如分片分配问题或副本数过少)可能导致操作失败,引发 cluster_block_exception。
- 如何检查索引设置:
GET /index_name/_settings 图片
图片
- 解决方法:
确保分片合理分配,避免过度分配。推荐阅读:
Elasticsearch 使用误区之三——分片设置不合理
检查和调整副本分片数量,确保有足够的副本来保障数据冗余和查询性能。
二、预防措施
要预防 cluster_block_exception,我们可以采取以下措施:
- 措施1:定期监控磁盘空间
使用 Kibana 或其他监控工具设置磁盘空间的监控阈值,避免磁盘空间不足。
- 措施2:自动化分片管理:
使用索引生命周期管理(ILM)策略,自动化控制索引的迁移、删除或冻结操作,以避免无限制的索引增长。
ILM 实战视频:https://www.bilibili.com/video/BV1MU4y1u7D4/
- 措施3:定期健康检查。
定期检查集群的健康状态,并在集群状态变为 yellow 或 red 时立即采取措施。
- 措施4:备份和更新
定期备份 Elasticsearch 数据,确保出现问题时数据可以快速恢复。
此外,确保 Elasticsearch 版本是最新的,以利用性能改进和错误修复。
三、总结
cluster_block_exception 错误虽然听起来棘手,但只要你了解了它的触发原因和解决方法,就能轻松应对。
通过本文的指南,结合日常的监控和优化策略,你可以确保 Elasticsearch 集群在高效且稳定的状态下运行,避免潜在的停机和数据损失。
参考
【1】https://kasata.medium.com
【2】https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-reroute.html