本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面 && 笔者理解
对于自动驾驶车辆要无缝融入为人类设计的交通系统,它们首先要“安全”,也就是作者常说的"Safty first!",但是同时也还会有一个关键要求就是“遵守交通规则(交通法规、法律和社会规范)”。但是交通规则是多样且复杂的,涵盖了来自不同地区法律、驾驶规范的数千条法规。在这些交通规则中,自车必须考虑各种因素,比如其他道路参与者的行为、当前道路状况和环境背景,来识别与特定场景相关的规则。这些因素的任何变化可能需要不同的规则或重新优先考虑现有规则。
- 论文链接:https://arxiv.org/pdf/2410.04759
之前的一些工作集中在选择关键规则和人工写的决策规则上,然而,这种手动编码方法难以处理大量交通规则,并且不能轻易适应不同地区的法规。另外,交通规则的语义复杂性和上下文依赖性也是做决策的另一个难点。交通规则从标准解释到特定驾驶行为都有涵盖,需要以不同的方式整合到决策过程中。例如,法律的约束是严格的,而当地规范和安全条款可能需要根据场景灵活应用。因此,智能地理解和将人工写的的规则纳入决策系统对于自动驾驶车辆无缝融入人类交通系统至关重要。
对于为特定任务训练的传统AI系统来说,这是一个挑战,但具有强大理解和推理能力的大型语言模型(LLMs),可以做到!本文介绍了一个新的可解释的遵守交通规则的决策者,它结合了一个基于检索增强生成(Retrieval-Augmented Generation,RAG)构建的交通规则检索智能体和使用LLM(GPT-4o)的推理模块。推理模块会从两个层面上来评估行动:
- 行动是否合规,即它是否遵循所有强制性交通规则;
- 行动是否被认为是安全行为,即它是否既遵守强制性交通规则又遵循安全指南。
这种双重层面的评估确保了对合法合规和遵守安全驾驶实践的全面评估和决策。此外,为了增强可解释性,中间推理信息,如推理过程中使用交通规则,也会被输出,提供了评估者决策过程的透明度。
相关工作
自动驾驶中的交通规则
为了将交通规则集成到自动驾驶系统中,已经有过很多的方法。早期的方法包括基于规则的系统和有限状态机,这些系统通过显式的if-then规则或状态转换来编码交通法律。为了处理复杂场景,出现了更复杂的方法:行为树创建了能够表示和执行交通规则的分层决策结构,以及使用LTL或MTL等时间逻辑的形式方法为指定和验证遵守交通法律提供了严格的框架。然而,这些方法通常难以应对现实世界交通规则的模糊性和地域差异,导致在创建能够适应不同监管环境的自动驾驶车辆时面临挑战。最近,大型语言模型(LLMs)在理解自然语言和解释复杂场景方面展现出了显著的能力。利用这些能力,LLMs可以以更灵活和上下文感知的方式处理和整合交通规则,无需基于规则的编码。例如,LLaDA利用LLMs从当地手册中解释交通规则,使自动驾驶车辆能够相应地调整任务和运动计划。同样,AgentDriver将交通规则纳入基于LLM的认知框架中,在规划期间存储和参考这些规则。然而,确保LLMs准确应用相关交通规则而不产生幻觉或误解仍然是一个关键挑战。
检索增强生成
检索增强生成(Retrieval-Augmented Generation,RAG)通过结合神经检索和sequence-tosequence生成器,解决LLM幻觉问题并提高信息检索的准确性,最近的一些研究已经证明了RAG在提高LLM在当前事件、语言建模和开放领域问答等领域的准确性和事实正确性方面的有效性。这些发现引发了RAG在提高基于LLM的自动驾驶系统的交通规则合规性方面的潜力。其动态检索能力使实时访问特定地区的交通规则成为可能,解决了适应不同监管环境的挑战。RAG提供的事实增强可以减少LLM中的幻觉,降低编造或误用交通规则的风险。RAG处理复杂和上下文信息的能力也非常适合解释具有多个条件或例外的微妙交通规则。此外,RAG的检索过程中固有的透明度可以提高自动驾驶系统中决策的可解释性,这是法规合规性和公众信任的一个关键因素。
自动驾驶的决策
自动驾驶的决策方法已经从基于规则的发展到基于学习的方法。基于学习的方法在动态驾驶环境中比前者表现出更大的适应性,使自动驾驶车辆摆脱了复杂手工规则的约束。两种典型的学习方法是模仿学习(imitation learning, IL)和强化学习(reinforcement learning, RL)。IL专注于模仿专家的决策,但面临在线部署中的不同分布问题。相反,RL在在线交互中探索和学习,但这种试错方法效率低下。此外,另一篇论文GPT-Driver引入了GPT到自动驾驶车辆中,将规划重新构想为语言建模问题。然而,在由交通规则构建的人类驾驶环境中,自动驾驶车辆不仅需要确保安全,还需要在驾驶过程中遵循这些规则,同时与人类驾驶的车辆一起驾驶。使用统一模型将不同的语义交通规则整合到决策中仍然是一个未充分探索的领域。
提出的方法
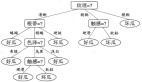
作者提出的方法,如图1所示,包含两个主要组件:
- 一个交通规则检索智能体(Traffic Rules Retrieval Agent),它使用检索查询从法规文档中检索相关交通规则;
- 一个推理智能体(Reasoning Agent),它基于环境信息、自车的状态和检索到的交通规则来评估行动集(action set)中每个行动的交通规则依从性。

作者首先做环境分析,为交通规则检索智能体生成检索查询,并为推理智能体提供环境信息输入。为了提取超出常见感知输出的更多法规相关特征,作者使用视觉语言模型(Vision Language Model,VLM)GPT-4o,基于自车的摄像头图像分析环境。分析遵循精心设计的“思考链”(Chain-of-Thought,CoT)流程:VLM首先进行广泛的环境概览并检查一般道路信息,然后进行详细分析,重点关注关键要素,如其他道路使用者、交通元素和车道标记,特别是与车辆全局规划输出相关的元素(例如,“右”、“左”或“向前”)。然后VLM生成一个简洁的检索查询,总结当前场景的情况,供交通规则检索智能体使用。

图3展示了环境分析的一个示例输出。作者从基于全局规划输出的行动空间(Action Space)中提取一个行动集,该行动集包含所有可能的行动。为了简单起见,作者将行动空间仅包含一组预定义的行动:右转、左转、向前行驶(以当前速度、加速或减速)、向左变道和向右变道。提取过程选择与全局规划输出一致的行动。例如,如果全局规划输出是“左”,行动集将包括以当前速度、加速或减速左转。
交通法规的检索增强生成
为了增强模型对本地交通规则和规范的理解,并充分考虑所有可用来源的相关规则,作者开发了交通规则检索(Traffic Regulation Retrieval, TRR)智能体,如图2所示。

由于不同地区有不同的交通规则来源,作者以美国为例来展示TRR智能体如何充分考虑可用来源。由于宪法原因,美国的交通规则由各州而不是联邦政府制定。城市还建立了本地规则以管理交通并确保安全。为确保全面覆盖,TRR包括州和地方法规。此外,为美国司法系统提供参考的案例法和提供额外安全指南的驾驶手册也被视为重要来源,并被纳入TRR。因此,作者设计的TRR包含以下综合法规文档集合:
- 州级交通法律:由州立法机构制定并在整个州执行的,规范车辆运营并确保道路安全的法律。
- 州级驾驶手册:由各州DMV出版,详细说明州交通法律和安全驾驶实践。它包括以文本和插图形式呈现的驾驶安全指南。
- 市级交通规则:由地方政府制定,用于解决特定需求(如停车、速度限制和车道使用)的规则,以管理本地交通并确保安全。
- 州级法院案例:对交通相关案例的司法裁决澄清法律并影响执法。
- 交通规范:被广泛认可的驾驶员遵循的行为,以确保顺畅和安全的道路互动。这些规范对于自动驾驶车辆与人类驾驶行为和社会期望保持一致至关重要。本文不专注于为这些规范建立记录库,但作者将使用示例来说明作者的框架仍然适用。
在评估了基于传统倒排索引的检索方法(依赖于关键词输入,如BM25和Taily)的检索性能后,作者发现基于嵌入的算法(利用信息丰富的长查询并根据段落相似性检索)在完整性和效率方面显著优于前者。集成到TRR智能体中,基于嵌入的方法更有效地处理驾驶场景的复杂性。
每个文档或记录都被重新格式化为带有层次标题的markdown,以提高清晰度,使随后的推理智能体更好地解释。除了文本内容,尤其是在州级手册中广泛使用,用视觉示例澄清法规的图表,也被集成到TRR智能体中。这种集成特别重要,因为有些法规细节嵌入在图像中,但并未在相应的文本中明确描述。所以,图表被转换为文本标签,并附在相关段落的末尾,并在检索过程结束时适当恢复。
在检索过程中,作者首先为法规文档和先前生成的交通规则检索查询生成向量嵌入,然后应用FAISS相似性搜索来确定它们之间的相关性。从段落级到句子级的级联检索pipeline有助于确保结果既全面又简洁。在对整个数据源进行段落级嵌入后,应用top-k选择来选择最相关的段落,形成一个新颖的细分数据库。为解决由于大型标记化交通手册的规模而可能影响搜索准确性的稀疏性问题,作者对选定的段落进行了句子级重新嵌入。这第二级嵌入通过专注于最相关的部分,提供了更好的索引和搜索能力。这种方法允许动态适应,通过优先考虑可用法规的相关性。最终,TRR智能体汇总了从交通法规和州级法律中选定的句子、城市法规的规则以及法院案例,以及属性图像,以产生一个全面的结果,提供给推理智能体。
推理智能体
推理智能体利用带有CoT提示方法的LLM(GPT-4o),来负责确定行动集中的每个行动是否符合交通规则。推理智能体接收三个关键输入:
- 来自环境分析的当前环境信息
- 自车的行动集
- 从TRR智能体检索到的一组交通规则。
在推理过程中,智能体首先过滤检索到的交通规则,以识别最适用于当前情况和自车预期行动的规则。然后,这些规则被归类为强制性规则(必须遵循以确保合法合规)或安全指南(代表最佳实践,虽然不具有法律要求,但建议采取以实现最佳驾驶行为)。推理智能体接着检查是否符合强制性规则。如果当前行动违反任何强制性规则,智能体得出行动不合规的结论;否则,它被标记为合规。然后模型通过检查强制性规则和安全指南(如果有检索到)来评估安全性,如果行动同时符合两者,它被标记为安全;否则,被标记为不安全。推理智能体为行动集中的每个行动输出一个二元合规性和安全性决策,并清晰地引用每个适用规则,详细说明行动为何合规或不合规,以提高推理过程的可解释性。然后框架选择被标记为既合规又安全的行动作为决策的最终输出。图3最右侧则展示了推理智能体的一个示例输出。
实验结果
为了验证提出的方法以及其在利用法规进行决策制定方面的有效性,作者开发了一个全面的基准,其中包含了假设的和现实世界场景,如图3所示。假设场景提供了更大的多样性,而现实世界数据实验展示了框架在真实驾驶条件下的实际性能。作者主要在波士顿地区评估了这些场景。
交通规则检索(TRR)智能体和RAG
作者在TRR智能体中使用的文档集合遵循图2所示的架构,包括以下内容:

作者使用了OpenAI的“text-embedding-ada-002”模型进行段落级检索,阈值设定为0.28,以及SentenceTransformers的“paraphrase-MiniLM-L6-v2”进行句子级检索,并收集了top-5检索到的句子。
假设场景
假设场景以文本格式描述,包括30种情况,涵盖了从转弯或通过交叉口等常见场景,到在分隔道路上超过停止的学校巴士或让从后方接近的紧急车辆等罕见案例,这些通常不被真实世界数据集所涵盖。这些场景由研究人员通过审查波士顿的法规代码和驾驶手册手动识别,因为它们对人类或自动驾驶驾驶员来说可能具有挑战性。作者评估了框架在30个假设场景中的性能,包括使用和不使用TRR智能体的数据,如图4所示。

在缺乏特定本地法规或依赖交通规范的场景中,LLM有效地使用其广泛的预训练知识做出正确的决策。然而,在需要遵守详细的市级或州级法规或司法先例的场景中,仅LLM不足以确保安全。整合了包括本地法规和司法决定的TRR智能体,将场景-行动推理精度从82%提高到100%,决策制定精度从76%提高到100%。这突出了将全面的法律和司法信息整合到LLM框架中,以有效应对复杂的现实世界驾驶情况的重要性。
现实世界场景
为了评估框架在现实世界数据上的性能,作者在nuScenes数据集上对其进行了测试。由于它不是为与交通规则相关的任务设计的,因此不包含交通规则注释。为此,作者手动审查了摄像头图像,并选择了与交通规则强相关的样本,其中行动更多地受到交通规则的约束或影响。对于每个样本,作者为行动集中的行动标注了合规性和安全性标签,确定合规和安全的行动作为决策输出的基准真实值。为确保有意义的评估并避免由于重复或过于相似的场景导致的不平衡,作者仔细选择了适用不同交通规则的样本,或者由于与法规直接相关的场景特定因素导致相同规则的应用存在变化。因此,作者从验证集中识别出了17个多样化的样本进行评估,作者的模型为其中的15个样本产生了正确的输出和准确的推理。

在图5(a)和(b)中,作者展示了两个场景:一个是没有行人的斑马线,一个是有行人的斑马线。对于没有行人的斑马线,模型在自车加速向前时输出“合规但不安全”,这符合常识。在有行人的场景中,加速向前不符合交通规则,作者的框架正确地识别了这一点,输出了正确的合规判断。这两个例子展示了模型根据环境因素的变化,准确地调整其评估的能力。在(c)中,作者进一步展示了一个需要同时考虑多个交通元素和规则的案例。在这个场景中,车辆在没有“禁止红灯右转”标志的红灯处右转,这使得右转在法律上是允许的。然而,有一个行人正在车辆前方的斑马线上过马路,要求车辆让行。因此,不礼让的右转是不遵守交通规则的。如最终输出所示,作者的模型成功识别了这一点,并输出了“不合规”。在(d)中,作者展示了一个自车接近施工区域并应减速的案例,作者的模型成功识别了这一点,输出了行动“以减速向前行驶”。这是以前基于规则的方法难以处理的场景,因为它们通常由于需要手工制定规则,通常只选择关键规则,经常省略特定案例,如施工区域的法规。

在图6中,作者展示了新加坡的一个案例,以展示作者的模型可以轻松适应不同地区。在这个场景中,自车试图在红灯处右转。虽然在波士顿右转是合法的,但在新加坡是非法的。如图所示,作者的模型正确地输出了“不合规”,符合新加坡的交通规则。与以前需要为每个新地区重新制定规则的基于规则的方法不同,作者的模型只需简单地将交通规则文件从波士顿的切换到新加坡的,就可以无缝地适应新场景。
写在最后
本文介绍了一个可解释的、由LLM驱动的、重视交通规则的决策框架,该框架集成了交通规则检索(TRR)智能体和推理智能体。在假设的和现实世界场景上进行的实验证实了作者方法的强大性能及其对不同地区的无缝适应性。作者相信,该框架将显著提高自动驾驶系统的安全性和可靠性,增强监管机构和公众的信任。未来的工作将扩展框架的测试到更多地区,并多样化作者的测试场景。此外,开发一个全面的现实世界数据集,用于与交通规则相关的任务,对于该领域的未来研究和进步至关重要。