在业务初期,为了控制投入成本,许多公司通常只使用一个机房提供服务。但随着业务的发展和流量的增长,对服务响应速度和可用性的要求逐渐提高,这时就需要考虑在不同地区部署服务,以提供更好的用户体验。这也是互联网公司在流量增长阶段的必经之路。
我之前所在的公司连续三年流量不断增长。有一次,机房的对外网络突然断开,导致线上服务全面离线,网络供应商也无法联系上。由于没有备用机房,我们花了三天时间紧急协调,重新拉线路才恢复服务。这次事故造成的影响非常大,公司损失达千万元。吸取了这次教训后,我们将服务迁移到了更大型的机房,并决定在同一城市建设双机房,以提高服务的可用性。这样,当一个机房出现故障时,用户可以通过 HttpDNS 接口快速切换到另一个正常的机房。
为了确保在一个机房故障时,另一个机房能够直接接管流量,我们对两个机房的设备进行了 1:1 的采购。但如果让其中一个机房长时间处于冷备状态会造成资源浪费,因此我们希望两个机房能同时对外提供服务,也就是实现同城双活。不过,双活方案的一个关键问题是如何实现双机房之间的数据库同步。
核心数据中心设计
由于数据库使用的是主从架构,因此全网只能有一个主库来进行数据更新。我们只能在一个机房部署主库,然后由这个机房将数据同步到其他备份机房。虽然两个机房之间有专线连接,但网络的完全稳定性无法保证。如果网络出现故障,我们需要确保机房之间在网络恢复后能够快速恢复数据同步。
有人可能会认为直接采用分布式数据库可以解决这个问题。然而,改变现有的服务体系并全面迁移到分布式数据库不仅需要相当长的时间,成本也非常高昂,对大多数公司来说并不实际。因此,我们需要考虑如何改造现有系统,实现同城双活机房的数据库同步。这也正是我们的目标
核心数据库中心方案是常见的实现方式,这种方案只适合相距不超过 50 公里的机房。
 图片
图片
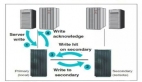
在这个方案中,主库集中部署在一个核心机房,其余机房中的数据库则作为从库。当有数据修改请求时,核心机房的主库会首先完成修改,然后通过主从同步将更新的数据传输到其他备份机房的从库。
由于用户通常是从缓存中获取信息,为了降低主从同步的延迟,备份机房会将更新后的数据直接写入本地缓存。同时,客户端会在本地记录下数据修改的最后时间戳(若没有,则记录当前时间)。当客户端向服务端发起请求时,服务端会自动对比缓存中该数据的更新时间与客户端本地的修改时间。如果缓存中的更新时间早于客户端记录的时间,服务端会触发同步操作,尝试在从库中查找最新数据;若从库中没有最新数据,则从主库中获取最新数据并更新到该机房的缓存中。
通过这种方式,可以有效避免机房之间的数据更新延迟问题,从而确保用户能更及时地获取到最新的数据。
 图片
图片
此外,客户端还会通过请求调度接口,使用户在短时间内只访问同一个机房,避免用户在多个机房之间来回切换时,因数据在不同机房同时修改而产生更新合并冲突。总体来看,这种方案设计相对简单,但也存在一些明显的缺点。
例如,如果核心机房发生故障,其他机房将无法执行数据更新。故障期间,需要人工切换各个代理(proxy)的主从库配置才能恢复服务,故障恢复后也需要手动介入以恢复主从同步。此外,由于主从同步存在一定的延迟,刚更新的数据在备用机房中会有短暂的不可见时间,这种延迟会导致业务逻辑中需要人工处理这种情况,整体操作较为繁琐,增加了实现的复杂性。
这里我给你一个常见的网络延迟参考:
同机房服务器:0.1 ms同城服务器(100 公里以内) :1ms(10 倍 同机房)北京到上海:38ms(380 倍 同机房)北京到广州:53ms(530 倍 同机房)
需要注意的是,上述设计只是一次 RTT 请求,而机房间的同步涉及多次顺序叠加的请求操作。如果要大规模更新数据,主从库的同步延迟将更为显著。因此,这种双活机房方案的数据量不能过大,且业务更新数据的频率也不能太高。另外,如果服务对强一致性有要求,即所有操作都必须在主库“远程执行”,这也会加大主从同步的延迟。
除了以上问题,双机房之间的专线偶尔也会出现故障。我曾遇到过一次专线断开持续了两小时,期间只能临时通过公网来保持同步,但公网同步不稳定,延迟在 10ms~500ms 之间波动,导致主从延迟超过 1 分钟。幸运的是,由于用户中心服务主要依赖长期缓存的数据,业务主要流程没有受到太大影响,只是用户修改信息的速度变得很慢。
双机房同步还可能偶发主从同步中断的情况,因此建议设置告警处理机制。一旦出现此情况,应立即向故障警报群发送通知,由 DBA 人员进行人工修复。此外,我还遇到过在主从不同步期间,用户注册时自增 ID 出现重复,导致主键冲突。为此,我建议将自增 ID 替换为基于 SnowFlake 算法生成的 ID,以减少主键冲突的风险。
总的来说,尽管这种核心数据库的中心化方案实现了同城双活,但人力投入成本非常高。DBA 需要手动维护同步,一旦主从同步中断,恢复起来相当耗时耗力,且研发人员也需要时刻关注主从不同步的情况。因此,我推荐使用另一种方案:数据库同步工具 Otter。
跨机房同步神器:Otter
Otter 是阿里开发的数据库同步工具,它可以快速实现跨机房、跨城市、跨国家的数据同步。如下图所示,其核心实现是通过 Canal 监控主库 MySQL 的 Row binlog,将数据更新并行同步给其他机房的 MySQL。
 图片
图片
因为我们要实现同城双机房双活,所以这里我们用 Otter 来实现同城双主(注意:双主不通用,不推荐一致要求高的业务使用),这样双活机房可以双向同步:
 图片
图片
如上图所示,每个机房内都有自己的主库和从库,缓存可以跨机房主从同步,也可以是本地的主从同步,这取决于具体的业务需求。Otter 使用 Canal 将机房内主库的数据变更同步到 Otter Node 中,然后通过 Otter 的 SETL(Select, Extract, Transform, Load)机制整理后,再将数据同步到对方机房的 Node 节点,从而实现双机房之间的数据同步。
在这里需要提到 Otter 处理数据冲突的方式,以解决双机房同时修改同一条数据的问题。Otter 中的数据冲突分为两类:行冲突和字段冲突。行冲突可以通过对比数据的修改时间来解决,或者在发生冲突时进行回源查询来覆盖目标库。而对于字段冲突,可以根据修改时间覆盖,也可以合并多个修改操作。例如,如果 a 机房和 b 机房分别对某字段进行了 -1 的操作,合并后该字段的最终修改值为 -2,以此实现数据的最终一致性。
但需要注意的是,这种合并策略并不适用于库存类的数据管理,因为可能会导致超卖现象。如果有类似的需求,建议使用长期缓存来处理,以避免并发修改导致的数据不一致问题。
总结
机房之间的数据同步一直是行业中的难题,由于其高昂的实现成本,如果无法实现双活,那么必然会有一个机房以 1:1 的机器数量在空跑。并且在发生故障时,也无法保证冷备机房能够立即对外提供服务。然而,双活模式的维护成本也不低,机房之间的数据同步经常会因网络延迟或数据冲突而中断,最终导致两个机房数据不一致。
好在 Otter 在数据同步方面采取了多种措施,能够在大多数情况下保证数据的完整性,并降低同城双活的实现难度。即便如此,在业务运转中,我们仍需人工梳理业务流程,以尽量避免多个机房同时修改同一条数据。为此,我们可以通过 HttpDNS 调度,让用户在一段时间内只在一个机房内活跃,减少数据冲突的可能性。对于频繁修改、资源争抢较高的服务,通常在机房本地执行完整事务操作,避免跨机房同时修改带来的同步错误。