












最近,我大部分时间都在玩大型语言模型(LLMs),但我对计算机视觉的热爱从未真正消退。因此,当有机会将两者结合起来时,我迫不及待地想要深入研究。在Goodreads上扫描书的封面并将其标记为“已读”总是感觉像一种魔法,我忍不住想要为自己重现这种体验。

通过结合自定义训练的YOLOv10模型和OCR技术,你可以获得巨大的准确性提升。但当你加入一个LLM(Llama 3)时,真正的魔法就发生了——那些混乱的OCR输出突然变成了干净、可用的文本,非常适合实际应用。
为什么我们需要在OCR中使用YOLO和Ollama?
传统的OCR(光学字符识别)方法在从简单图像中提取文本方面做得很好,但当文本与其他视觉元素交织在一起时,往往难以应对。通过使用自定义的YOLO模型首先检测文本区域等对象,我们可以为OCR隔离这些区域,显著减少噪声并提高准确性。让我们通过在没有YOLO的图像上运行一个基本的OCR示例来演示这一点,以突出单独使用OCR的挑战:
import easyocr
import cv2
# Initialize EasyOCR
reader = easyocr.Reader(['en'])
# Load the image
image = cv2.imread('book.jpg')
# Run OCR directly
results = reader.readtext(image)
# Display results
for (bbox, text, prob) in results:
print(f"Detected Text: {text} (Probability: {prob})")THE 0 R |G |NAL B E STSELLE R THE SECRET HISTORY DONNA TARTT Haunting, compelling and brilliant The Times虽然它可以很好地处理更简单的图像,但当存在噪声或复杂的视觉模式时,错误就开始堆积。这时,YOLO模型介入并真正发挥作用。
1. 训练自定义Yolov10数据集
用对象检测增强OCR的第一步是在你数据集上训练一个自定义的YOLO模型。YOLO(You Only Look Once)是一个强大的实时对象检测模型,它将图像划分为网格,允许它在单次前向传递中识别多个对象。这种方法非常适合检测图像中的文本,特别是当你想要通过隔离特定区域来提高OCR结果时。

书籍封面数据集
我们将使用这里链接的预注释书籍封面数据集,并在它上面训练一个YOLOv10模型。YOLOv10针对较小的对象进行了优化,使其非常适合在视频或扫描文档等具有挑战性的环境中检测文本。
from ultralytics import YOLO
model = YOLO("yolov10n.pt")
# Train the model
model.train(data="datasets/data.yaml", epochs=50, imgsz=640)你可以调整周期数量、数据集大小等参数,或者尝试调整超参数以提高模型的性能和准确性。
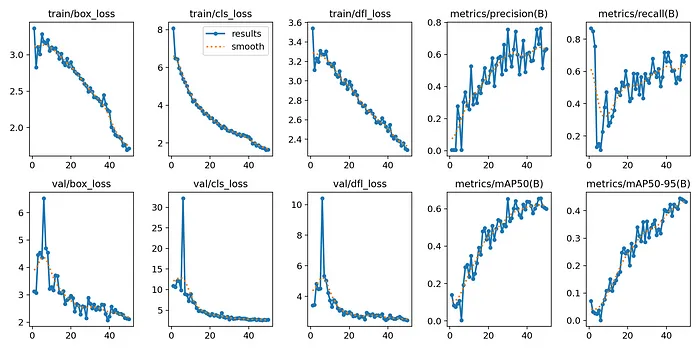
YOLOv10自定义数据集训练的关键指标
2. 在视频上运行自定义模型以获取边界框
一旦你的YOLO模型训练完成,你可以将其应用于视频以检测文本区域周围的边界框。这些边界框隔离了感兴趣的区域,确保了更干净的OCR过程:
import cv2
# Open video file
video_path = 'books.mov'
cap = cv2.VideoCapture(video_path)
# Load YOLO model
model = YOLO('model.pt')
# Function for object detection and drawing bounding boxes
def predict_and_detect(model, frame, conf=0.5):
results = model.predict(frame, conf=conf)
for result in results:
for box in result.boxes:
# Draw bounding box
x1, y1, x2, y2 = map(int, box.xyxy[0].tolist())
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
return frame, results
# Process video frames
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Run object detection
processed_frame, results = predict_and_detect(model, frame)
# Show video with bounding boxes
cv2.imshow('YOLO + OCR Detection', processed_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video
cap.release()
cv2.destroyAllWindows()
这段代码实时处理视频,绘制检测到的文本周围的边界框,并隔离这些区域,为下一步——OCR——做好了完美的准备。
3. 在边界框上运行OCR
现在我们已经用YOLO隔离了文本区域,我们可以在这些特定区域内应用OCR,与在整个图像上运行OCR相比,大大提高了准确性:
import easyocr
# Initialize EasyOCR
reader = easyocr.Reader(['en'])
# Function to crop frames and perform OCR
def run_ocr_on_boxes(frame, boxes):
ocr_results = []
for box in boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0].tolist())
cropped_frame = frame[y1:y2, x1:x2]
ocr_result = reader.readtext(cropped_frame)
ocr_results.append(ocr_result)
return ocr_results
# Perform OCR on detected bounding boxes
for result in results:
ocr_results = run_ocr_on_boxes(frame, result.boxes)
# Extract and display the text from OCR results
extracted_text = [detection[1] for ocr in ocr_results for detection in ocr]
print(f"Extracted Text: {', '.join(extracted_text)}")'THE, SECRET, HISTORY, DONNA, TARTT'结果明显改善,因为OCR引擎现在只处理被特别识别为包含文本的区域,减少了从无关图像元素中误解的风险。
4. 使用Ollama改进文本
使用easyocr提取文本后,Llama 3可以进一步通过完善通常不完美和混乱的结果。OCR功能强大,但它仍然可能误解文本或返回无序的数据,特别是书籍标题或作者名称。LLM介入整理输出,将原始OCR结果转化为结构化、连贯的文本。通过用特定提示引导Llama 3来识别和组织内容,我们可以将不完美的OCR数据完善为整洁格式化的书籍标题和作者名称。最好的部分?你可以使用Ollama在本地运行它!
import ollama
# Construct a prompt to clean up the OCR output
prompt = f"""
- Below is a text extracted from an OCR. The text contains mentions of famous books and their corresponding authors.
- Some words may be slightly misspelled or out of order.
- Your task is to identify the book titles and corresponding authors from the text.
- Output the text in the format: '<Name of the book> : <Name of the author>'.
- Do not generate any other text except the book title and the author.
TEXT:
{output_text}
"""
# Use Ollama to clean and structure the OCR output
response = ollama.chat(
model="llama3",
messages=[{"role": "user", "content": prompt}]
)
# Extract cleaned text
cleaned_text = response['message']['content'].strip()
print(cleaned_text)The Secret History : Donna Tartt一旦LLM清理了文本,抛光后的输出可以存储在数据库中,或用于各种实际应用,例如:
- 数字图书馆或书店:自动分类并显示书籍标题及其作者。
- 档案系统:将扫描的书籍封面或文件转换为可搜索的数字记录。
- 自动元数据生成:根据提取的信息为图像、PDF或其他数字资产生成元数据。
- 数据库输入:将清理后的文本直接插入数据库,确保更大系统中的数据结构化和一致性。
通过结合对象检测、OCR和LLMs,你解锁了一个强大的管道,用于更结构化的数据处理,非常适合需要高精度的应用。
结论
你可以通过结合自定义训练的YOLOv10模型和EasyOCR,并使用LLM增强结果,显著改进文本识别工作流程。无论你是在处理棘手的图像或视频中的文本,清理OCR混乱,还是使一切超级抛光,这个管道都能为你提供实时、激光精确的文本提取和细化。
完整代码:https://github.com/tapanBabbar9/yolov10/tree/main/book-cover
























