














译者 | 李睿
审校 | 重楼
RAG可以利用外部信息提升大型语言模型的性能,其性能依赖于检索文档的质量。除了标准检索方法之外,还有4种方法可以提高所检索文档的质量。
检索增强生成(RAG)是利用外部信息定制大型语言模型的重要技术之一。但是,RAG的性能取决于检索到的文档的质量。除了在RAG管道中使用的标准检索方法之外,还有这4种技术有助于提高所检索文档的质量。
基于标准嵌入的检索
RAG管道中使用的标准检索方法是在用户查询和知识语料库的嵌入之间进行相似性搜索。在这种方法中,可以通过以下步骤准备知识库:
1.文档首先被分解成更小的块(例如500~1000个令牌)。
2.编码器模型(例如SentenceTransformers或OpenAI嵌入)计算每个块的嵌入。
3.嵌入存储在向量数据库中(例如Pinecone或Qdrant)。
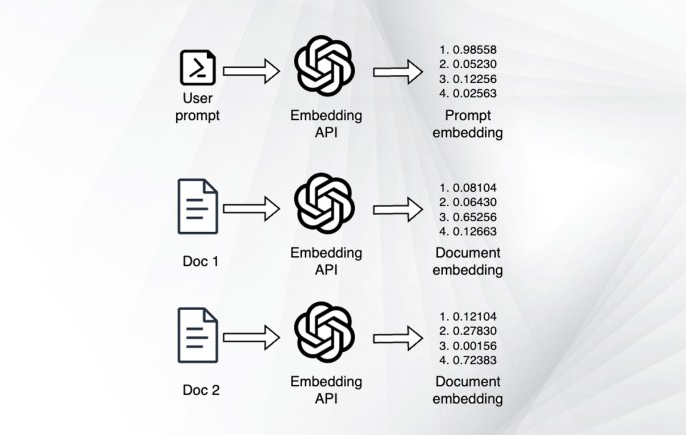
图1使用标准检索方法检索相关文档
一旦向量数据库准备就绪,那么RAG管道就可以开始向用户查询添加场景:
1.用户向应用程序发送查询。
2.在准备阶段使用的编码器模型计算查询的嵌入。
3.将嵌入与向量数据库中存储的嵌入进行比较,以检索最相似的文档。
4.检索到的文档的内容作为场景添加到用户提示中。
5.将更新后的提示信息发送给LLM。
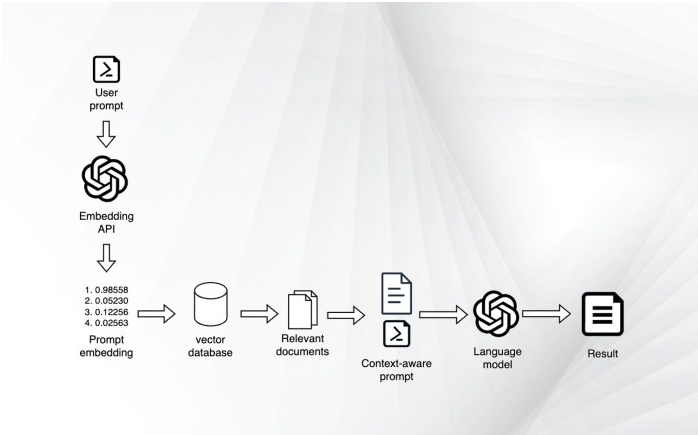
图2使用嵌入和向量数据库检索相关文档
文档和查询域对齐
有时,包含有用信息的文档在语义上与用户的查询不一致。因此,它们嵌入的相似性得分将非常低,RAG管道将无法检索到它们。
文档领域对齐可以通过修改提示的方式来解决,使其与相关文档更加接近。文档对齐的一种有效技术是假设文档嵌入(HyDE)。
给定一个查询,假设文档嵌入(HyDE)会提示语言模型生成一个包含答案的假设文档。这个生成的文档可能包含虚假的细节,但它将具有知识语料库中相关文档附近的相关模式。在检索阶段,不是使用用户查询,而是将假设文档的嵌入发送到向量数据库,以计算与索引文档的相似度得分。
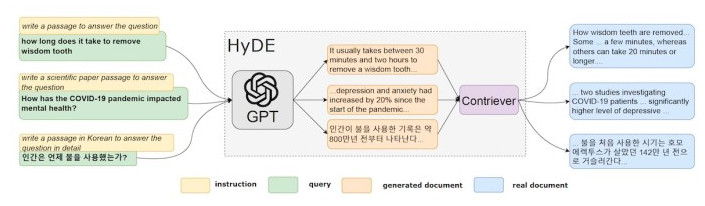
图3假设文档嵌入(HyDE)框架
还有另一种方法可以改进查询和文档之间的一致性。在“查询域对齐”中,使用LLM生成一组问题,每个文档可以回答这些问题,并将它们的嵌入存储在向量存储库中。在检索过程中,将查询的嵌入与问题的嵌入进行比较,并返回与最佳匹配对应的文档。将问题与问题进行比较可以确保查询和向量存储之间更好地对齐。
混合搜索
传统的RAG管道非常有效,但也有其局限性。嵌入模型在捕获语义信息方面非常有效,但在寻找精确匹配时可能返回不精确的结果。为此,可以使用经典搜索算法或SQL查询来增强RAG管道。
例如,可以使用像BM25这样的算法,根据用户查询的关键字搜索文档。BM25的优点是它会自动降低可能出现在大型语言模型(LLM)查询中的常见词的权重,并专注于最重要的关键词。
或者,可以使用文本到SQL技术(text-to-SQL techniques),该技术使用LLM根据用户的请求创建SQL查询。然后可以将查询发送到关系数据库以检索匹配的记录。
可以组合由不同检索方法检索的文档,删除重复的文档,并将它们作为场景添加到提示符中。这可以确保获得不同检索方法的值。
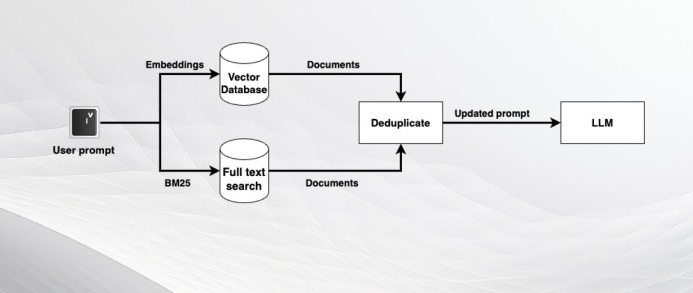
图4基于嵌入检索和BM25的混合搜索
场景检索
在许多情况下,包含查询答案的文档块缺少重要的信息。如果要处理被分成多个块的大型文档,这一点尤其正确。在这种情况下,用户查询的答案可能需要来自文档多个块的信息。
例如,知识语料库可能包括X公司的季度收益,想回答这个问题:“X公司2024年第一季度的收入增长是多少?”
季度文件的其中一个部分可能包含正确的答案:“公司的收入与上一季度相比增长了3%。”但这部分并没有指明是哪家公司,也没有说明是指哪个时间段。
在这些案例下,可以通过在计算嵌入和索引之前向每个块添加场景信息来增强检索。最近,Anthropic AI引入了场景检索。在上述示例中,包含答案的文档块前面将添加以下信息:“这个块来自X公司的季度收益。它讨论了该公司2024年第一季度的收益。”
重新排序
无论如何改进索引和检索机制,都有可能遗漏某些提示的重要文档。一个易于实施且广受欢迎的解决方法是重新排序。
重新排序算法将文档的全文与用户查询进行比较。虽然它们在对整个语料库进行处理时效率不高,但可以非常快速地处理几十篇文档。因此,如果希望将n个文档作为场景添加到LLM中,则可以检索2n或3n个文档,并通过重新排序算法运行它们,以检索与查询相关的前n个文档。
Cohere Rerank 是一个快速且易于使用的基于API的重新排序工具。如果想要一个开源的重新排序模型,可以使用bge-reranker。
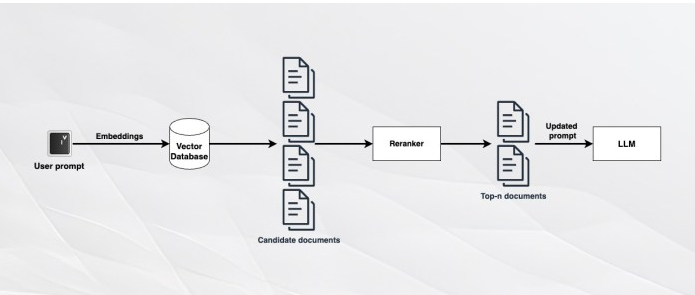
图5 采用重新排序的RAG
注意事项
虽然使用先进检索技术可以提高RAG管道的性能,但考虑权衡因素同样重要。增加复杂性层次可能会导致计算和存储成本上升,或者减慢检索过程。例如,文档域对齐需要在RAG流程中额外调用一次LLM,从而减慢流程并在大规模应用时显著增加成本。采用经典搜索算法和重新排序为RAG增加了额外的处理步骤。场景检索需要多次调用LLM来生成场景信息,从而增加了准备和索引步骤的成本。
通常从为任务设定预期准确率开始,然后确定额外的努力和成本是否值得回报。例如,在一个写作辅助应用程序中,如果期望一位对该主题有全面了解的专家来审查和纠正整个答案,那么可能不需要通过向RAG管道添加额外的处理层来获得几个百分点的准确率提升。另一方面,如果正在开发一个应用程序,其中检索文档的准确性是一个很大的差异化因素,并且用户不介意多等待几秒钟来获得更准确的答案,那么添加额外的技术是有意义的。
原文标题:4 ways to improve the retrieval of your RAG pipeline,作者:Ben Dickson





















