作者 | 崔皓
审校 | 重楼
OpenAI 推出的 Realtime API 标志着语音交互技术的一次重大突破。它允许开发者构建低延迟、高效率的多模态对话体验,支持文本和音频输入输出,为语音助手、在线教育、游戏等场景带来了新的可能性。
传统的语音交互模式存在明显延迟,需要经过“声音->文字->文字推理->声音”的转换过程,导致情感、重点和口音的丧失,影响用户体验。Realtime API 通过直接流式传输音频输入输出,优化了这一过程,实现了更加自然、流畅的对话体验。它还能够自动处理中断,并支持函数调用,使得语音助手能够更加智能地响应用户请求。
Realtime API 使用 WebSocket 协议进行双向通信,并通过事件机制实现消息的发送和接收。开发者可以通过监听不同的事件来完成消息的发送和接受,而且事件驱动机制非常适合处理异步通信。
本文详细介绍了 Realtime API 的功能、原理和应用场景,并通过代码示例展示了如何使用该 API 创建语音交互应用。
开篇
OpenAI最近推出的Realtime API,标志着人工智能交互技术的一个重大突破。这个API目前处于公开测试阶段,允许开发者在其应用中构建低延迟的多模态对话体验,支持文本和音频作为输入和输出。这意味着,通过Realtime API,开发者可以创建出自然、实时的语音对语音交互,无需经过中间的文本转换,从而实现更加流畅和互动的用户体验。此API的发布,不仅降低了开发门槛,还推动了AI技术的应用创新,为语音助手、在线教育、游戏等场景带来了新的可能性。

为什么需要 Realtime API?
在追求极致用户体验的今天,传统的语音助手技术面临着重大挑战。在过去,为了构建类似的语音交互体验,开发人员必须依赖一系列复杂的流程:首先使用类似Whisper语音识别模型来转录音频,也就是将人类输入的声音转化为文字的形式。接着,转化之后的文字传递给LLM(大预言模型,例如:GPT-4o)进行推理,最后将LLM推理出来的文字通过文本转语音的模型来播放输出。相应过程经历了“声音->文字->文字推理->声音”,方法不仅会引入明显的延迟,还常常导致情感、重点和口音的丧失,从而影响用户体验。
然而,随着OpenAI Realtime API的推出,这一切都得到了显著改善。Realtime API通过直接流式传输音频输入和输出优化了这一过程,实现了更加自然和实时的对话体验。它还能够自动处理中断,类似于ChatGPT中的高级语音模式。此外,实时API允许创建持久的WebSocket连接,以便与GPT-4o交换消息,支持函数调用,这使得语音助手能够更加智能地响应用户请求。例如,助手可以代表用户下订单或检索相关客户信息,以个性化其响应。简而言之,Realtime API不仅解决了“实时”交互的主要问题,还通过函数调用功能,满足了客户对个性化服务的需求,为语音交互应用带来了革命性的进步。
尝鲜 Realtime API?
既然Realtime API 可以让用户与大模型通过语音方式进行实时交互,那么就让我们走近Realtime API 感受一下它的魅力吧!通过OpenAI的Playground的页面就可以访问Realtime API,如下图所示。这是 OpenAI Playground 的界面,用于访问 Realtime API 功能。该界面为开发者提供了一个简单易用的平台,用来测试实时的语音交互应用。

在这个界面中,开发者可以进行以下操作:
1.会话区域
中心区域显示的是实时会话窗口,任何语音或文本交互都会在这里出现。在靠下方的区域中,用户可以通过点击“Start session”按钮启动一个会话,与 API 进行交互。
2.语音设置
右侧提供了一些基本设置,如选择语音模型(例如 Alloy)和配置语音活动检测。
Threshold(阈值)、Prefix padding(前缀填充)、Silence duration(静默时长):这些参数允许用户微调语音检测的灵敏度,确保系统能够准确地捕捉和处理语音输入。
3.功能与模型配置
开发者可以添加自定义的功能(Functions),这为构建复杂的语音交互场景提供了可能。还有模型的温度(Temperature)和最大生成字数(Max tokens)的配置,用来控制模型生成内容的创意程度和响应长度。
目前该界面已经给Plus 用户开放使用权限,开发者可以配置和测试 Realtime API,了解其响应效果并调整设置。
我们可以点击“Start session”开启一次兑换,此时需要获取麦克风的权限,在对话之前需要在右上方的“System instructions”中告诉模型要执行的指令。
当出现下图“Start talking”的时候就可以与LLM进行对话了。

如下图所示,我们输入简单的“Who are you?”(00:03)时,LLM 在很短时间(00:04)立即给出了回复:“I’m an AI here to help out!” 。目前来说是Realtime API的Beta 版本,对话的token 有一定限制。

通过官网宣传可知,该 API 的音频功能由全新的 GPT-4o 模型提供支持,具体版本为 gpt-4o-realtime-preview。而在几周内,开发者还将迎来 gpt-4o-audio-preview,该版本支持通过文本或音频输入与 GPT-4o 模型交互,并生成文本或音频输出,或两者兼备的响应形式。
不过从使用价格方面来看,是有一点小贵,如下:
文本Token:每 100 万个输入Token 5 美元,每 100 万个输出Token 20 美元。
音频Token:每 100 万个输入Token 100 美元,输出Token 200 美元。这意味着,开发者大致会为每分钟音频输入支付 0.06 美元,音频输出支付 0.24 美元。
为什么不直接调用API ?
从上面的Realtime API 演示可以看出,仅仅通过输入语音就可以和GPT 模型进行对话,这个和ChatGPT的功能类似,仅仅把输入的文字改成了语音,看上去好像就是直接调用API接口就可以完成功能,为什么硬生生搞出一个Realtime API的概念。细心的你可能注意到了,在语音对话的场景中有一个特点,用户与大模型之间需要创建一个会话,基于这个会话会有多次的,实时的交流,这里的“实时”就是Realtime API与普通API存在不同的地方。
由此我们可以推断出Realtime API执行的基本逻辑,也就是模型、外部系统、用户输入之间的协同工作:
Client 端的角色:Client(客户端)是负责发起操作和接收用户输入的地方。在这个架构中,客户端可以是与用户交互的界面,比如一个聊天应用、网页、移动端应用等。客户端需要将用户的请求传递给服务端,并且根据返回的结果展示给用户。
Server 端的角色:Server(服务器端)是主要的处理中心,它负责:接收从客户端发来的请求。与 OpenAI 的模型(API)交互,获取初步的结果。根据情况,决定是否需要进一步调用外部系统或函数(如数据库查询、外部服务请求)。处理外部请求的结果,并通过事件机制将结果推送回客户端。需要注意的是这里的Client 和Server 需要保持一个实时的,“长”连接保证信息沟通的顺畅。
为了实现Client 与Server 之间的信息沟通,于是Realtime 引入了事件机制:
异步操作处理:Server 在与外部系统通信时,有可能需要等待数据返回,而不希望在这期间阻塞整个流程。事件驱动机制使得 Server 可以发起请求后立即返回,而在外部操作完成时,通过事件通知系统完成操作并返回结果。
事件驱动的更新:比如在某些场景下,外部系统可能随时推送新的状态更新或结果,这时候事件机制可以使得 Server 自动处理并通过事件将结果通知客户端。
多客户端协作:在一些实时系统中,比如聊天系统、监控系统,多个客户端可能同时与服务器交互,事件驱动模型允许多客户端之间实时共享和同步数据,而不需要每个请求都单独进行阻塞调用。
Realtime API的特点
我们通过使用OpenAI 提供的Playground 了解了Realtime API的基本功能,虽然目前测试的Token量有限,但让我们对它的了解更近了一步。然后,分析了Realtime API 执行的基本逻辑,通过Client 与Server 创建长连接,利用事件机制在他们之间发送实时消息。
在接下来的部分,我们将详细介绍 Realtime API 的功能和应用,在Realtime API中特别实现了一个实时 API。这个实时API是一种有状态、基于事件的API,通过 WebSocket 进行通信。这个如何理解呢?这里就需要理解Realtime API 机制的三个特点:
WebSocket 通信:该 API 使用 WebSocket 协议进行双向通信。与传统的 HTTP 请求-响应模式不同,WebSocket 允许客户端和服务器之间建立持久连接,降低了延迟,提高了数据传输的效率,特别适合实时语音、文本或其他模态数据的交互。
设置状态:由于需要保持实时通信,因此需要通过WebSocket实现长连接。那么就需要针对 WebSocket 连接保持其会话的上下文,从而在整个会话中跟踪用户的请求和响应,这样才能支撑持续、多轮次的对话场景。
事件交互:在创建会话通道之后,就需要定义沟通方式,Realtime API 是基于事件来收发消息的,开发者可以通过监听不同的事件完成消息的发送和接受,而且事件驱动机制非常适合处理异步通信。
我们通过一段Realtime API的代码让大家更近一步了解,代码如下:
import WebSocket from "ws";
const url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01";
const ws = new WebSocket(url, {
headers: {
"Authorization": "Bearer " + process.env.OPENAI_API_KEY,
"OpenAI-Beta": "realtime=v1",
},
});
ws.on("open", function open() {
console.log("Connected to server.");
ws.send(JSON.stringify({
type: "response.create",
response: {
modalities: ["text"],
instructions: "Please assist the user.",
}
}));
});
ws.on("message", function incoming(message) {
console.log(JSON.parse(message.toString()));
});代码中,通过 wss://api.openai.com/v1/realtime URL 建立一个 WebSocket 连接,并指定使用模型 gpt-4o-realtime-preview-2024-10-01。在连接成功后,发送一个请求,让模型使用 "text" 模态,并为用户提供帮助。随后,当服务器发送消息时,我们会通过 "message" 事件接收到响应,并将其打印出来。
import WebSocket from "ws";使用 WebSocket 模块,它是基于 WebSocket 协议的一个库,用于在客户端和服务器之间创建持久的、全双工通信通道。ws 模块是 Node.js 环境中常用的 WebSocket 实现。
const url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01";url 是 WebSocket 的服务器地址,使用的是 OpenAI Realtime API 的 WebSocket 连接地址。wss:// 表示这是一个加密的 WebSocket 连接,类似于 https。model=gpt-4o-realtime-preview-2024-10-01 代表我们要使用的模型版本。
const ws = new WebSocket(url, {
headers: {
"Authorization": "Bearer " + process.env.OPENAI_API_KEY,
"OpenAI-Beta": "realtime=v1",
},
});使用 WebSocket 构造函数来创建一个 WebSocket 连接。Authorization 是API 的认证信息,用于验证开发者的身份。process.env.OPENAI_API_KEY 是从环境变量中读取的 OpenAI API 密钥,确保安全地访问 API。OpenAI-Beta 是额外的请求头,指定使用的是 Realtime API 的测试版本。"realtime=v1" 表示这是 Realtime API 的第一个版本。
ws.on("open", function open() {
console.log("Connected to server.");
ws.send(JSON.stringify({
type: "response.create",
response: {
modalities: ["text"],
instructions: "Please assist the user.",
}
}));
});ws.on("open", ...):这是一个事件监听器,当 WebSocket 连接成功打开时,会触发 "open" 事件。我们使用匿名函数来处理这个事件。
console.log("Connected to server.") 用于输出成功连接的消息到控制台,确认连接已经建立。
ws.send(...) 通过 WebSocket 发送一条 JSON 格式的消息给服务器,表示希望创建一个响应。
"type": "response.create" 定义了请求的类型,这里表示要创建一个新的响应。"modalities": ["text"] 指定了使用的模态(即交互形式),此处是文本模态。"instructions": "Please assist the user." 是我们发给 API 的指令,让它协助用户进行对话。
ws.on("message", function incoming(message) {
console.log(JSON.parse(message.toString()));
});ws.on("message", ...):当从服务器接收到一条消息时,会触发 "message" 事件。message.toString() 将接收到的二进制消息转换为字符串形式。JSON.parse() 用于将字符串解析成 JSON 对象。console.log() 将解析后的消息对象打印到控制台,便于调试和查看返回结果。
通过上面的操作,我们就与Realtime API建立了连接,接着就可以通过发送事件的方式,让Realtime API帮我们完成各种不同的功能。
接下来,试图通过如下代码让Realtime API针对我们输入的文字产生响应。
const event = {
type: 'conversation.item.create',
item: {
type: 'message',
role: 'user',
content: [
{
type: 'input_text',
text: 'Hello!'
}
]
}
};
ws.send(JSON.stringify(event));
ws.send(JSON.stringify({type: 'response.create'}));上述代码首先创建event对象,通过 WebSocket 发送用户的文本输入(Hello!)到服务器。Event对象中定义了type: 'conversation.item.create' ,从字面理解为对话。如果说每次客户端与服务器的WebSocket的连接为一个session(会话),一旦客户端创建会话,它就会发送包含文本和音频块的 JSON 格式的event(事件)。服务器将包含语音输出的音频、该语音输出的文本记录和函数调用进行响应。
一个session(会话)中有可能包含多个conversation(对话)。每次对话的内容可以不同,可以聊天气,可以聊商品订单,当时他们都保存在一个session(会话)中,也就是通过一个长连接session支持多次对话。
event 对象中的 item 属性用于向 Realtime API 发送不同类型的消息或事件。在这个例子中,item 具有一个名为 message 的属性,它表示一条消息,用户发送的文本或音频都可以封装在这里。item 可以是三种类型之一:message、function_call 或 function_call_output。
- message: 表示一条消息,包含文本或音频的输入。
- function_call: 表示模型希望调用某个工具或函数。
- function_call_output: 表示函数调用的返回结果。
在这段代码中,通过 WebSocket 向服务器发送一个 conversation.item.create 事件,其中 item 是一条用户发送的文本消息。这一事件告知服务器用户输入了 "Hello!",并请求模型生成适当的响应。
音频交互
前面通过两段代码描述了如何通过Client 与Server 端进行WebSocket连接,利用event发送消息得到响应。接下来利用相同的手法,通过event 传送音频信息获得响应。我们需要将音频文件转换为 PCM16 格式的 base64 编码数据,并通过 WebSocket 发送到服务端作为用户输入的音频消息。接下来是代码的片段:
1.引入模块
import fs from 'fs';
import decodeAudio from 'audio-decode';fs模块用于读取本地文件系统中的音频文件。
audio-decode 库用来将音频文件解码为原始的音频字节(`AudioBuffer` 对象),便于后续处理。
2.floatTo16BitPCM 函数
function floatTo16BitPCM(float32Array) {
const buffer = new ArrayBuffer(float32Array.length * 2);
const view = new DataView(buffer);
let offset = 0;
for (let i = 0; i < float32Array.length; i++, offset += 2) {
let s = Math.max(-1, Math.min(1, float32Array[i]));
view.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7fff, true);
}
return buffer;
}函数用于将 Float32Array(浮点数组格式的音频数据)转换为 PCM16 格式的 ArrayBuffer。PCM16 是常见的音频编码格式,将浮点值(-1 到 1 之间)转换为 16 位整数。DataView对象允许你对二进制 ArrayBuffer 进行逐字节操作。setInt16 方法用于写入 16 位整数。
3.base64EncodeAudio 函数
function base64EncodeAudio(float32Array) {
const arrayBuffer = floatTo16BitPCM(float32Array);
let binary = '';
let bytes = new Uint8Array(arrayBuffer);
const chunkSize = 0x8000; // 32KB chunk size
for (let i = 0; i < bytes.length; i += chunkSize) {
let chunk = bytes.subarray(i, i + chunkSize);
binary += String.fromCharCode.apply(null, chunk);
}
return btoa(binary);
}该函数首先调用 `floatTo16BitPCM` 将音频数据转换为 PCM16 格式。接下来,它将 `ArrayBuffer` 转换为 `Uint8Array`,方便逐字节处理。然后,它将音频数据按 32KB 块(`chunk`)读取,并通过 `String.fromCharCode` 将字节转换为字符串形式。最后,为了便于通过网络传输音频数据,使用 `btoa` 将该二进制字符串编码为 base64。
4.解码音频文件并获取通道数据
const myAudio = fs.readFileSync('./path/to/audio.wav');
const audioBuffer = await decodeAudio(myAudio);
const channelData = audioBuffer.getChannelData(0); // 仅处理单声道音频fs.readFileSync 同步读取音频文件的内容。decodeAudio 将音频文件解码为 AudioBuffer,并通过 getChannelData(0)获取音频的通道数据。这里假设处理的是单声道音频(如果是多声道,需要处理多个通道)。
5.发送音频数据
const base64AudioData = base64EncodeAudio(channelData);
const event = {
type: 'conversation.item.create',
item: {
type: 'message',
role: 'user',
content: [
{
type: 'input_audio',
audio: base64AudioData
}
]
}
};
ws.send(JSON.stringify(event));
ws.send(JSON.stringify({type: 'response.create'}));通过调用 base64EncodeAudio 函数,将音频通道数据编码为 base64 格式。构建 WebSocket 事件,其中 item是类型为 message 的用户输入,且内容是 base64 编码的音频数据(input_audio)。ws.send(JSON.stringify(event)) 通过 WebSocket 向服务器发送这条消息。随后,通过发送 response.create 请求,要求服务器生成对应的响应。
事件类型定义
前面几段代码我们发现无论是Client还是Server 在发送和接受event的时候都会定义event类型,比较常见的有conversation.item.create 创建对话,respnse.create响应。如下图所示,实际上在Realtime API中定义了9个Client 事件类型和28个Server事件类型。


以我们常用的conversation.item.create类型为例, 其完全体的定义如下:
{
"event_id": "event_345",
"type": "conversation.item.create",
"previous_item_id": null,
"item": {
"id": "msg_001",
"type": "message",
"status": "completed",
"role": "user",
"content": [
{
"type": "input_text",
"text": "Hello, how are you?"
}
]
}
}conversation.item.create 是一个事件类型,主要用于在对话中添加一个新项目(例如消息或函数调用)。此事件包含以下关键属性:
- event_id:可选的客户端生成的 ID,用于标识事件。
- type:事件类型,必须为 "conversation.item.create"。
- previous_item_id:新项目插入后,前一个项目的 ID。
- item:要添加的项目,包含:
- id:项目唯一 ID。
- type:项目类型("message"、"function_call"、"function_call_output")。
- status:项目状态("completed"、"in_progress"、"incomplete")。
- role:消息发送者的角色("user"、"assistant"、"system")。
- content:消息内容。
- call_id、name、arguments、output:用于函数调用相关的详细信息。
Realtime AI 最佳实践
在OpenAI推出Realtime API的第一时间,LangChain也推出了与之相关的开源项目: Voice ReAct Agent,它是一个基于OpenAI实时API的ReAct风格代理的最佳实现。它通过LangChain工具列表调用工具,并且用户可以编写和传递自定义工具给模型。目前该项目包含Python 和TypeScript两个版本。具体的安装、使用过程可以参考官方链接,整个过程非常简单,这里不做赘述。
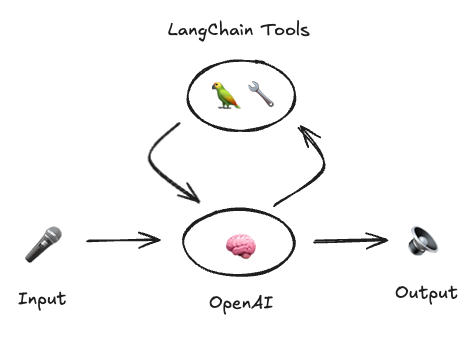
我们把关注点放到代码实现上, 如下图所示,这里是Python Server端的代码,__init__.py。 它主要完成了下面三个方面的任务,
- WebSocket 连接:connect()负责管理与 OpenAI API 的 WebSocket 连接,发送和接收数据。
- 工具执行:VoiceToolExecutor 负责工具调用的异步执行,确保并发操作的安全性。
- 实时 API 代理:OpenAIVoiceReactAgent 管理与 OpenAI 实时 API 的交互,执行工具并根据输入流式传输响应。

由于篇幅有限,这里不对所有代码进行讲解,只针对主要的类和函数进行描述如下:
1.connect()(函数)
这是一个异步上下文管理器,用于建立到 OpenAI API 的 WebSocket 连接。它接收 API 密钥、模型和 URL,并返回两个组件:用于发送数据的函数 send_event 和用于接收事件的迭代器 event_stream。该函数保证在使用后正确关闭 WebSocket。
2.VoiceToolExecutor (类)
此类通过函数调用异步执行工具,当与用户交互时,如果需要用到外部工具就会启用该类。
包含属性:
- tools_by_name: 工具名称与 BaseTool 对象的字典。
- _trigger_future: 管理函数调用触发的 asyncio.Future 对象。
- _lock: 用于安全处理并发操作的asyncio.Lock。
函数:
- _trigger_func():等待 future 对象返回工具调用数据。
- add_tool_call(tool_call):添加工具调用,确保不会被其他并发调用覆盖。
- _create_tool_call_task(tool_call):创建并运行处理工具调用的任务,使用工具的 `ainvoke()` 方法解析 JSON 参数并处理错误。
- output_iterator():持续返回任务结果的主循环,管理并发任务并处理错误。
3.OpenAIVoiceReactAgent (类)
这是核心代理类,负责管理用户输入和 Realtime API 实时交互,并处理工具的执行。
属性:
- model: 使用的 OpenAI 模型。
- api_key: 以 SecretStr 格式安全存储的 API 密钥。
- instructions: 可选的模型指令。
- tools: 可用的工具列表。
- url: OpenAI API 的 WebSocket URL。
函数:
- aconnect(input_stream, send_output_chunk):连接 OpenAI API 并管理实时的输入输出通讯。它发送工具信息和指令,监听响应,处理工具输出,并流式传输对话内容,使用 amerge 合并多个输入输出流。该方法还处理特定的响应类型并触发必要的工具调用。
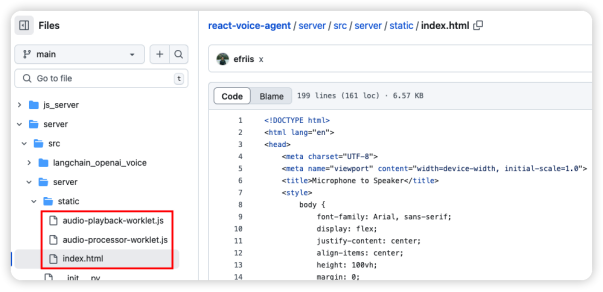
- audio-playback-worklet.js:实现了一个 AudioPlaybackWorklet,负责将接收到的 PCM 数据解码并播放。它包含了handleMessage 方法,将传入的音频数据存入缓冲区;process 方法负责将缓冲区的数据输出到扬声器,按每次的缓冲量来处理数据。
- audio-processor-worklet.js:实现了 PCMAudioProcessor,将麦克风捕获的 Float32 音频数据转换为 Int16 格式,然后通过 postMessage 发送到主线程,供后续处理。
- Index.html:通过WebSocket("ws://localhost:3000/ws")与服务器建立连接后,即可实现音频的实时传输和处理。为此,我们创建了一个Player类来初始化音频上下文,并利用AudioWorkletNode(引用audio-playback-worklet.js)播放服务器传来的音频数据。同时,设计Recorder类,用于获取用户麦克风输入,通过audio-processor-worklet.js提供的方法处理音频数据,将其分片编码为base64格式,然后通过WebSocket发送到服务器。在接收到服务器返回的音频流后,客户端会对其进行解码,并传递给播放器,从而实现音频的播放功能。整个流程形成了一个闭环,确保了音频从录入到播放的顺畅进行。
看完服务端代码,再看看客户端代码,如下图所示:
总结
Realtime API 改变了传统语音交互模式,通过流式传输音频输入输出,实现低延迟、高效率的语音对话。它支持文本和音频两种模态,并提供事件驱动机制,方便开发者构建复杂的语音交互场景。通过 WebSocket 连接和事件交互,Realtime API 为开发者提供了强大的工具,推动语音交互应用的创新和发展。本文介绍了 Realtime API 的功能、原理和应用,并通过代码示例展示了其使用方法,为开发者提供实用的参考和指导。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。