今天我们继续深入学习Kafka的核心组件,重点解析副本状态机(ReplicaStateMachine)的实现原理。这节课将带领大家走进Kafka源码,深入理解副本状态机的工作机制和各个状态的转换逻辑。
在之前的学习中,我们多次提到Kafka中的副本状态机和分区状态机,它们是Kafka集群运作的基础模块。副本状态机负责Kafka集群中所有副本的状态转换与管理,而分区状态机则负责分区的状态管理。今天我们将首先聚焦于副本状态机的内部实现,逐步剖析其运行流程和关键代码逻辑。
一、什么是副本状态机?
副本状态机是Kafka控制器的一部分,专门负责管理集群中所有副本的状态变化。当Kafka中的某些操作,如节点故障、集群扩展、分区重新分配等事件发生时,控制器通过副本状态机来管理和协调副本的状态。副本在集群中可以处于不同的状态,比如从ISR中加入或移除、被标记为不可用等。
副本的主要状态
在深入源码之前,我们先来看一下Kafka中副本的主要状态:
- OfflineReplica:副本当前不可用,无法提供服务。
- OnlineReplica:副本当前处于在线状态,参与正常的读写操作。
- NonExistentReplica:副本在当前节点上不存在,可能是刚被创建或者已被删除。
- ReplicaDeletionStarted:副本正在被删除。
- ReplicaDeletionSuccessful:副本已经成功删除。
- ReplicaDeletionIneligible:副本不适合被删除。
通过副本状态机,Kafka可以在不同状态之间进行转换,并确保系统的高可用性和一致性。
二、ReplicaStateMachine 的实现结构
接下来,我们进入Kafka源码,首先找到副本状态机的核心实现文件——ReplicaStateMachine.scala。以下是ReplicaStateMachine类的核心结构:
该类主要负责管理Kafka控制器上下文中的副本状态,以下是几个重要的组件:
- controllerContext:控制器的上下文信息,包含集群元数据。
- stateChangeLogger:状态变化日志,记录副本状态的变化。
- controllerBrokerRequestBatch:控制器向Broker发送的批量请求,用于通知Broker执行相应的操作。
状态变化的核心方法
- handleStateChanges:处理副本的状态变化,它是状态机的入口方法。当控制器检测到副本需要进行状态转换时,会调用该方法。
- initialize:初始化副本状态机。通常在控制器启动时调用,用于构建当前集群副本的状态视图。
- shutdown:关闭副本状态机,清理相关资源。
- doHandleStateChanges:这是状态变化的实际处理逻辑。在这个方法中,状态机会根据目标状态targetState,执行相应的状态转换操作。
- replicaStateTransition:该方法负责具体的状态转换逻辑。它根据副本的当前状态和目标状态,决定是否需要执行某些操作,如将副本标记为在线、离线、删除等。
三、状态转换逻辑详解
接下来,我们详细分析状态转换的核心逻辑,主要集中在replicaStateTransition方法中。此方法根据副本的当前状态和目标状态,执行相应的操作。
3.1 OnlineReplica -> OfflineReplica
当一个副本从OnlineReplica转变为OfflineReplica时,意味着该副本不再提供服务。状态转换逻辑如下:
在这个状态转换过程中,副本从ISR中被移除,表示该副本不再同步最新的数据。系统会通过日志记录该状态变化。
3.2 NonExistentReplica -> OnlineReplica
当一个新副本被创建并且成功启动后,它会从NonExistentReplica状态转为OnlineReplica。这个过程通常发生在集群扩容或者分区重新分配时:
此时,该副本被加入到ISR中,开始与Leader副本保持数据同步。
3.3 OfflineReplica -> OnlineReplica
当一个副本从OfflineReplica恢复为OnlineReplica时,意味着它恢复了正常的服务能力,重新参与数据的读写操作:
在此过程中,该副本重新加入ISR,开始接收Leader的同步数据,恢复正常服务。
3.4 ReplicaDeletionStarted -> ReplicaDeletionSuccessful
当副本开始删除时,状态会从ReplicaDeletionStarted变为ReplicaDeletionSuccessful,表示副本已被成功删除:
在这里,副本的元数据会从控制器上下文中删除,同时通过日志记录删除操作的成功。
四、副本状态机的工作流程
4.1 事件驱动
Kafka副本状态机是基于事件驱动的。Kafka控制器监听集群中的各类事件(如节点加入、节点失效、分区重新分配等),并根据这些事件触发状态机的状态转换。Kafka控制器主要通过Zookeeper或KRaft(Kafka自带的元数据管理系统)感知这些事件,并做出相应的状态转换决策。
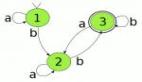
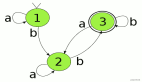
4.2 状态机流程图
下面是副本状态机的状态转换流程图,帮助大家理解各个状态之间的关系:
五、小结
在本文中,我们深入剖析了Kafka副本状态机(ReplicaStateMachine)的实现原理,重点介绍了其主要状态、核心代码逻辑以及状态转换的工作机制。副本状态机作为Kafka控制器的重要组成部分,确保了Kafka集群中各个副本的高效管理和协调工作。
通过源码解析,我们可以清晰地看到Kafka如何通过状态机来保证副本在各种情况下的正确状态转换,从而保障系统的稳定性和高可用性。希望这篇文章能够帮助大家更好地理解Kafka副本状态机的内部实现原理。