我们之前提到过,互联网大多数业务场景的数据都属于读多写少,在请求的读写比例中,写的比例会达到百分之一,甚至千分之一。而对于用户中心的业务来说,这个比例会更大一些,毕竟用户不会频繁地更新自己的信息和密码,所以这种读多写少的场景特别适合做读取缓存。通过缓存可以大大降低系统数据层的查询压力,拥有更好的并发查询性能。但是,使用缓存后往往会碰到更新不同步的问题,下面我们具体看一看。
缓存性价比
是的,缓存的确有可能被滥用,特别是在像用户中心这样对数据准确性要求很高的场景中。你提到在对用户中心进行优化时,首要想到的就是将用户信息放入缓存,以提高性能。这确实是一个常见的优化思路,因为缓存能够显著减少数据库的访问频率,提升系统响应速度。
# 表结构
CREATE TABLE `accounts` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`account` varchar(15) NOT NULL DEFAULT '',
`password` char(32) NOT NULL,
`salt` char(16) NOT NULL,
`status` tinyint(3) NOT NULL DEFAULT '0'
`update_time` int(10) NOT NULL DEFAULT '0',
`create_time` int(10) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
# 登录查询
select id, account, update_time from accounts
where account = 'user1'
and password = '6b9260b1e02041a665d4e4a5117cfe16'
and status = 1确实,这是一个简单的查询需求。乍一看,似乎将 2000 万条用户数据都放入缓存可以极大地提升性能,但实际上并不完全如此。虽然缓存能提供高性能的服务,但其性价比并不一定高。这个表主要用于账号登录的查询,而登录操作本身即使频繁,也不会对系统带来巨大的流量压力。因此,即便将所有用户数据放入缓存,大部分时间这些数据都处于闲置状态。这样一来,缓存资源反而被浪费,我们也不必要将并发量不高的数据缓存起来,从而增加预算开销。
这就引出一个核心问题:缓存的使用需要考虑性价比。如果花费大量时间和资源将某些数据放入缓存,但对系统性能并没有显著的提升,甚至增加了额外的成本,那么这样的缓存策略就是不合理的。缓存的效果需要经过评估,通常来说,只有热点数据才值得放入缓存。
临时热缓存
在推翻了将所有账号信息都放入缓存的方案后,我们将目标转向那些被频繁查询的信息上,比如用户信息。用户信息的使用频率非常高,尤其是在论坛等场景中,常常需要频繁展示,例如用户的头像、昵称和性别等。不过,由于这些数据量较大,全部缓存起来不仅浪费空间,还不具备性价比。
针对这种情况,我们可以考虑使用一种临时缓存的策略:当某个用户信息首次被访问时,将其存入缓存;在短时间内,若有类似查询请求,就可以直接从缓存中获取。这样既可以有效地降低数据库查询压力,又不会占用过多的缓存空间。以下是一个常用的实现临时缓存的代码示例:
# 示例代码
def get_user_info(user_id):
# 首先尝试从缓存中获取用户信息
user_info = cache.get(user_id)
if user_info:
return user_info
# 如果缓存中没有,查询数据库
user_info = db.query_user_info(user_id)
# 将查询到的信息存入缓存,并设置一个合理的过期时间
cache.set(user_id, user_info, timeout=300) # 缓存五分钟
return user_info正如我们看到的,这种策略将数据临时放入缓存,在 60 秒过期后自动淘汰。如果在这段时间内再次查询相同数据,我们的代码会重新将数据填入缓存,继续提供使用。这种临时缓存策略非常适合数据量大但热点数据较少的场景,有助于缓解数据库的查询压力。
设置缓存的 TTL(Time-to-Live)是为了更有效地利用内存资源。当数据在指定时间内未被再次访问,就会被自动清除,这样我们就能避免购买过多内存。通过这种方式,可以在节省成本的同时,提高缓存的性价比,且实现起来简单,维护也方便,是一种很常用的策略
缓存更新不及时问题
临时缓存是有 TTL 的,如果 60 秒内修改了用户的昵称,缓存是不会马上更新的。最糟糕的情况是在 60 秒后才会刷新这个用户的昵称缓存,显然这会给系统带来一些不必要的麻烦。其实对于这种缓存数据刷新,可以分成几种情况,不同情况的刷新方式有所不同,接下来我给你分别讲讲。
1. 单条实体数据缓存刷新
单条实体数据缓存更新是最简单的一个方式,比如我们缓存了 9527 这个用户的 info 信息,当我们对这条数据做了修改,我们就可以在数据更新时同步更新对应的数据缓存:
Type UserInfo struct {
Id int `gorm:"column:id;type:int(11);primary_key;AUTO_INCREMENT" json:"id"`
Uid int `gorm:"column:uid;type:int(4);NOT NULL" json:"uid"`
NickName string `gorm:"column:nickname;type:varchar(32) unsigned;NOT NULL" json:"nickname"`
Status int16 `gorm:"column:status;type:tinyint(4);default:1;NOT NULL" json:"status"`
CreateTime int64 `gorm:"column:create_time;type:bigint(11);NOT NULL" json:"create_time"`
UpdateTime int64 `gorm:"column:update_time;type:bigint(11);NOT NULL" json:"update_time"`
}
//更新用户昵称
func (m *UserInfo)UpdateUserNickname(ctx context.Context, name string, uid int) (bool, int64, error) {
//先更新数据库
ret, err := m.db.UpdateUserNickNameById(ctx, uid, name)
if ret {
//然后清理缓存,让下次读取时刷新缓存,防止并发修改导致临时数据进入缓存
//这个方式刷新较快,使用很方便,维护成本低
Redis.Del("user_info_" + strconv.Itoa(uid))
}
return ret, count, err
}总体来说,我们可以先识别出被修改的数据 ID,然后根据这些 ID 删除相应的数据缓存。在下次请求到来时,系统会重新获取最新的数据并更新到缓存中,这样可以有效减少并发操作将脏数据写入缓存的可能性。
除了这种方法,我们还可以向队列发送更新消息,让子系统处理更新,或者开发中间件,将数据操作发送到子系统,让其自行决定需要更新的数据范围。然而,通过队列更新消息时,我们可能会遇到一个问题——条件批量更新时,可能无法直接确定具体有多少个 ID 发生了变化。常见的解决方法是:首先按照相同的条件查询出所有受影响的 ID,然后执行更新操作,最后使用这些相关的 ID 更新具体的缓存。
2. 关系型和统计型数据缓存刷新
首先,有一种人工维护缓存的方式。众所周知,关系型数据或统计结果的缓存刷新具有一定的难度,主要原因在于这些统计数据通常是基于多条数据计算得出的。当我们需要刷新这类数据的缓存时,很难准确识别出需要更新的关联缓存。
为了解决这个问题,可以通过人工方式,在集中管理的地方记录或定义特定的刷新逻辑,以实现关联缓存的更新。
 图片
图片
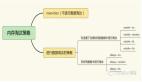
不过这种方式比较精细,如果刷新缓存很多,那么缓存更新会比较慢,并且存在延迟。而且人工书写还需要考虑如何查找到新增数据关联的所有 ID,因为新增数据没有登记在 ID 内,人工编码维护会很麻烦。除了人工维护缓存外,还有一种方式就是通过订阅数据库来找到 ID 数据变化。如下图,我们可以使用 Maxwell 或 Canal,对 MySQL 的更新进行监控。
 图片
图片
在这种方案中,变更信息会被推送到 Kafka。我们可以根据表名和具体的 SQL 确认哪些数据 ID 发生了更新,然后依据脚本中设定的逻辑,对相关缓存 key 进行更新。比如,当用户更新了昵称,缓存更新服务就能够识别需要更新 user_info_9527 这个缓存,同时根据配置找到并删除其他相关的缓存。这种方法的优势在于,可以快速地更新简单的缓存,并且核心系统可以向子系统广播数据变更信息,代码实现也相对简单。不过,对于复杂的关联关系刷新,仍然需要人工书写逻辑来实现。
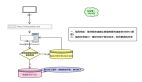
如果表内数据更新较少,还可以考虑使用版本号缓存策略。这种方法比较直接:一旦有任何更新,表中所有数据缓存都会过期。例如,可以为 user_info 表设置一个版本号 key,比如 user_info_version。当表数据发生更新时,直接将 user_info_version 自增 1。写入缓存时,同时记录当前版本号;读取时,业务逻辑会检查缓存版本号与表版本号是否一致。如果不一致,就更新缓存数据。需要注意的是,如果版本号频繁更新,缓存命中率会大幅下降,因此该方法更适合数据更新不频繁的表
当然,我们还可以对这个表做一个范围拆分,比如按 ID 范围分块拆分出多个 version,通过这样的方式来减少缓存刷新的范围和频率。
 图片
图片
此外,关联型数据更新还可以通过识别主要实体 ID 来刷新缓存。这要保证其他缓存保存的 key 也是主要实体 ID,这样当某一条关联数据发生变化时,就可以根据主要实体 ID 对所有缓存进行刷新。这个方式的缺点是,我们的缓存要能够根据修改的数据反向找到它关联的主体 ID 才行。
 图片
图片
最后,还有一种方法是通过异步脚本遍历数据库来刷新所有相关缓存。这种方式适用于在两个系统之间进行数据同步,能够减少系统之间的接口交互频率。其缺点是,在数据被删除后,还需要手动删除相应的缓存,因此更新存在一定延迟。不过,如果结合订阅更新消息广播机制,这种方案可以实现近乎同步的数据更新。
长期热数据缓存
回过头来看之前提到的临时缓存方案,虽然它能解决大部分问题,但有个潜在风险需要考虑:当 TTL 到期时,如果有大量缓存请求未命中,透传的流量可能会给数据库带来巨大的压力,甚至可能导致数据库崩溃。这就是业内常说的缓存穿透问题。如果发生大规模的并发穿透,服务可能宕机。因此,如果数据库无法承受日常流量,就不能依赖临时缓存方案来设计缓存系统,而应该采用长期缓存的方式来实现热点缓存,以避免缓存穿透对数据库的影响。
要实现长期缓存,需要更多的人工操作来保证缓存与数据表的一致性。长期缓存的普及主要得益于 NoSQL 技术的发展,它与临时缓存不同,需要业务几乎不依赖数据库,所有在服务运行期间所需的数据都必须在缓存中可用,并确保缓存不会在使用期间丢失。这带来的挑战是,我们需要精确知道缓存中的数据,并提前对这些数据进行预热。如果数据规模较小,还可以考虑将所有数据缓存起来,这样的实现会相对简单一些。
总结
并不是所有数据放入缓存都会带来良好的收益,因此我们需要从数据量、使用频率和缓存命中率三个方面进行分析。对于读多写少的数据,虽然将其缓存能够降低数据层的压力,但仍需根据一致性需求来更新缓存中的数据。
在这方面,单条实体数据的缓存更新相对容易实现,但对于需要条件查询的统计结果,实时更新则较为困难。因此,在设计缓存策略时,需综合考虑这些因素,以确保缓存的有效性和数据的一致。
 图片
图片