














10 月 9 日消息,科技媒体 marktechpost 昨日(10 月 8 日)发布博文,报道称谷歌公司推出了选择性注意力(Selective Attention)方法,可以提高 Transformer 架构模型的性能。
Transformer 架构简介
Transformer 是一种革命性的神经网络架构,由谷歌在 2017 年提出,主要用于处理序列数据,特别是在自然语言处理(NLP)领域。
Transformer 的核心是自注意力机制,允许模型在处理输入序列时捕捉词与词之间的关系,让模型能够关注输入序列中的所有部分,而不仅仅是局部信息。
Transformer 由多个编码器和解码器组成。编码器负责理解输入数据,而解码器则生成输出。多头自注意力机制使模型能够并行处理信息,提高了效率和准确性。
Transformer 架构模型挑战
Transformer 架构的一大挑战是它们在处理长文本序列时效率低下,由于每个标记与序列中的每个其他标记都相互作用导致二次复杂度,这就导致随着上下文长度的增加,计算和内存需求呈指数增长。
现在解决这一问题的方法包括稀疏注意力机制(sparse attention mechanisms),它限制了标记之间的交互数量,以及通过总结过去信息来减少序列长度的上下文压缩技术。
不过这种方法是通过减少在注意力机制中考虑的标记数量达成的,因此通常以性能为代价,可能会导致上下文关键信息丢失。
谷歌新方法
谷歌研究的研究人员提出了一种名为选择性注意的新方法,可以动态忽略不再相关的标记,从而提高 Transformer 模型的效率。
选择性注意力使用软掩码矩阵来确定每个标记对未来标记的重要性,减少对不重要标记的关注。
研究表明,配备选择性注意的 Transformer 架构模型在多个自然语言处理任务中表现出色,同时显著降低了内存使用和计算成本。
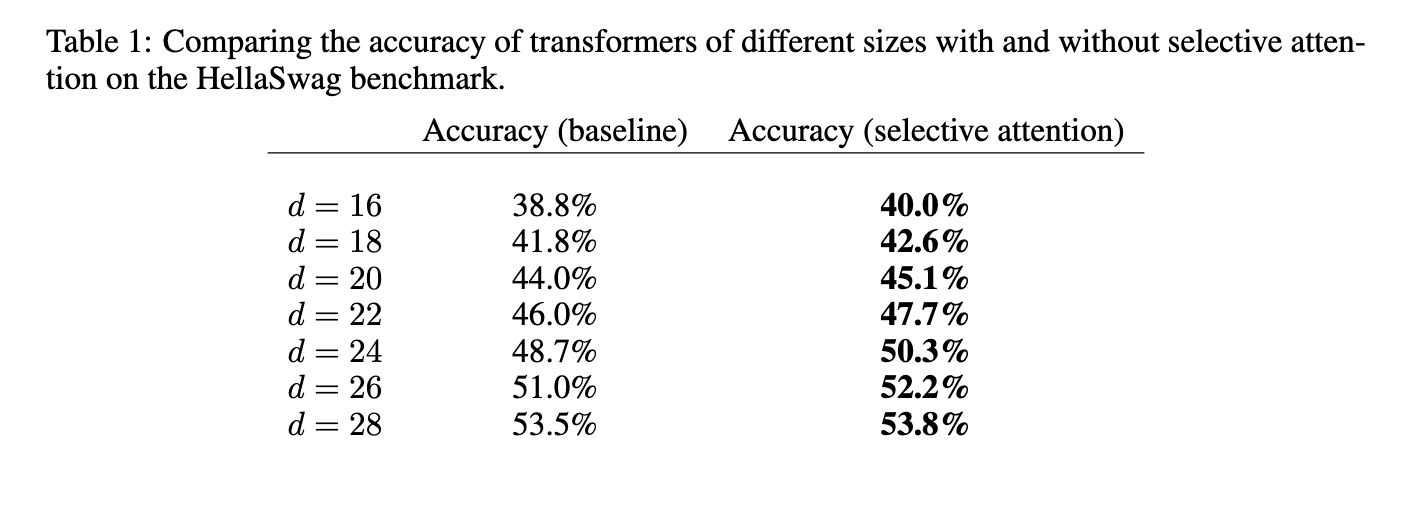

例如,在拥有 1 亿参数的 Transformer 模型中,注意力模块的内存需求在上下文大小为 512、1024 和 2048 个 tokens 时分别减少至 1/16、1/25 和 1/47。所提方法在 HellaSwag 基准测试中也优于传统 Transformer,对于较大的模型规模实现了高达 5% 的准确率提升。
选择性注意力允许构建更小、更高效的模型,在不损害准确性的情况下,显著减少内存需求。
IT之家附上参考地址























