布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用于测试一个元素是否在一个集合中。其核心思想是在允许一定误判的情况下,大幅度节省内存空间。本文将详细介绍布隆过滤器的基本概念、实现方法,并通过 Spring Boot 例子演示如何在 Java 中手写一个启动布隆过滤器的例子。

什么是布隆过滤器
布隆过滤器是一种空间效率极高的概率型数据结构,用于测试一个元素是否在一个集合中。其特点是:可能会误判元素存在,但一定不会误判元素不存在。
布隆过滤器的原理
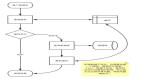
布隆过滤器的基本原理是使用多个哈希函数将元素映射到一个位数组中,并且每个元素对应的多个位置都被标记为 1。检查某个元素是否存在时,只需要验证这些位置是否都为1。如果有任意一个位置为 0,则该元素一定不存在。如果这些位置都为 1,则该元素可能存在。
(1) 哈希函数
布隆过滤器使用多个不同的哈希函数,将元素映射到位数组的多个位置。这些哈希函数需要独立且均匀分布。哈希函数的选择非常重要,如果哈希函数不合理,可能导致某些位置被过度映射,从而增加误判率。
(2) 位数组
位数组是布隆过滤器的核心结构。初始时位数组中的所有位都设为 0。当有元素加入时,通过哈希函数计算得到的位置被标记为 1。
(3) 检查元素
检查某个元素是否存在时,只需要验证这些位置是否都为1。如果有任意一个位置为 0,则该元素一定不存在;如果这些位置都为 1,则该元素可能存在,但不保证一定存在。
布隆过滤器的使用场景
布隆过滤器主要适用于需要快速判断元素存在性的场景,以下是一些具体应用:
- 缓存穿透:判断请求数据是否存在于缓存中,防止对数据库的重复查询。
- 缓存优化:在Web缓存中,布隆过滤器可以快速判断一个URL是否已经被缓存过,从而避免不必要的磁盘或网络访问。
- 数据库索引:在数据库中,布隆过滤器可以用来快速排除那些不可能包含查询结果的数据库页,从而减少查询的开销。
- 网络爬虫:在网页爬虫中,布隆过滤器可以用来存储已经访问过的网址,避免重复爬取。这对于处理大规模数据集非常有用,可以显著减少爬虫的负担。
- 垃圾邮件过滤:布隆过滤器可以用于构建邮件黑名单过滤系统,通过存储已知的垃圾邮件发送者信息,快速判断新邮件是否来自黑名单。这种场景下,布隆过滤器的误判率是可以接受的,因为重要的是快速识别出垃圾邮件,而不是完全避免误判。
如何在 Spring Boot 中使用布隆过滤器
我们可以使用 Guava 库提供的布隆过滤器来实现。本示例展示如何在 Spring Boot 项目中实现布隆过滤器。
(1) 添加依赖
首先,在pom.xml文件中添加 Guava 库的依赖:
(2) 示例代码解析
创建一个 Spring Boot 应用来演示布隆过滤器的使用:
我们实现了一个 Spring Boot 应用程序。在这个应用程序中:
- @PostConstruct注解:用于在 Spring Bean 的初始化完成后执行 init 方法。init 方法中创建布隆过滤器并填充测试数据。
- BloomFilter创建:使用 Guava 的 BloomFilter.create 方法创建一个布隆过滤器,预计存储 1000个整数,误判率设定为 0.01。
- 数据添加:通过循环向布隆过滤器中添加数据。
- 数据检查:提供 mightContain 方法检查元素是否可能存在于布隆过滤器中。
结语
通过本文内容,我们详细介绍了布隆过滤器的概念、原理、使用场景以及在 Spring Boot 中的实现。希望能帮助您更好地理解和使用布隆过滤器。