FastAPI已成为构建Python API的最流行框架之一,因其速度和易用性而广受欢迎。但在构建高性能应用程序时,有一个重要问题需要回答:应该使用同步(sync)还是异步(async)代码执行?
在本文中,我们将通过现实世界的性能测试,对同步和异步的FastAPI实现进行基准测试,并深入分析相关数据,以帮助开发者决定何时使用这两种方法。
一、同步与异步在FastAPI中的区别是什么?
- 同步代码(sync):在同步执行中,任务一个接一个地处理。每个请求都需要等待前一个请求完成,这在用户数量较多或存在慢I/O操作(如数据库查询或文件上传)时,可能会导致瓶颈。
- 异步代码(async):异步执行支持多个请求并发处理。应用程序无需等待I/O操作(如数据库调用)完成,而是可以继续处理其他请求,从而在高并发环境中更有效率。
那么,这两者在性能上的真实差异是什么呢?让我们来看看。
二、设置:在FastAPI中基准测试同步与异步
为了比较同步和异步实现,在这里创建了两个版本的FastAPI应用程序。
- 同步版本:使用传统的阻塞数据库查询,采用psycopg2。
- 异步版本:使用非阻塞的异步查询,采用asyncpg。
这两个版本都执行一个简单的任务:从PostgreSQL数据库查询用户。数据库中包含极少的数据,以便隔离同步/异步机制的影响。
技术栈:
- 使用FastAPI作为API框架。
- 使用SQLAlchemy作为ORM。
- 使用psycopg2或psycopg2-binary(同步)和asyncpg(异步)进行数据库连接。
- 使用PostgreSQL作为数据库。
为了测试性能,使用**Apache Benchmark(ab)**模拟了1000个请求,具有100个并发连接。
2.1 同步版本代码 💻
在同步版本中,在这里使用psycopg2驱动与SQLAlchemy,后者可执行阻塞查询。表格是使用同步的SQLAlchemy引擎创建的。
同步:main.py
同步:database.py
2.2 异步版本代码 💻
在异步版本中,在这里使用asyncpg驱动与SQLAlchemy,进行非阻塞查询。然而,表的创建仍然是同步进行的,因为SQLAlchemy的metadata.create_all()不支持异步。
异步:main.py
异步:database.py
在这个版本中,请求是以异步方式处理的,支持多个请求在等待I/O时并发处理。
三、基准测试命令
- 同步版本:ab -n 1000 -c 100 http://127.0.0.1:8000/users/1
- 异步版本:ab -n 1000 -c 100 http://127.0.0.1:8001/users/1
基准测试结果:同步vs异步
以下是基准测试的性能指标分析。
基准测试结果:同步vs异步(Airtable)
性能明细
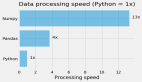
- 每秒请求数:
异步版本每秒可处理50.68个请求,而同步版本每秒只能处理36.89个请求。
在相同时间内,异步处理的请求数比同步版本多37%,因此在并发性方面,异步显然胜出。
- 每个请求的响应时间(平均值):
异步版本的平均响应时间低于同步版本27%(1973毫秒vs2710毫秒),这表明在高负载情况下,异步处理请求的效率更高。
最长请求时间:
两个版本的最长请求时间相似(约4000毫秒),但异步版本的表现更稳定,这体现在响应时间的波动较小。
图表比较
图表比较
以上是同步和异步版本在不同百分位数下的比较图,包括平均和最长请求时间。
- 实线表示不同百分位数下的响应时间。
- 虚线表示同步(2710.648毫秒)和异步(1973.057毫秒)的平均响应时间。
- 点线突出显示同步(4167毫秒)和异步(3851毫秒)的最长请求时间。
四、何时在FastAPI中使用同步与异步?
使用异步的情况:
- 应用程序需要处理高流量和大量并发用户。
- 应用程序是与I/O绑定的,需要进行大量数据库查询或API调用。
- 需要为大量请求最小化响应时间。
使用同步的情况:
- 应用程序的并发量较小,或主要执行CPU密集型任务。
- 希望保持代码库的简单性,避免异步处理的复杂性。
- 不希望应用程序扩展到同时处理数百或数千个请求。
五、优化异步性能
虽然异步在这些测试中速度更快,但仍有一些方法可以进一步优化。
- 连接池:使用连接池重用数据库连接,避免为每个请求创建一个新连接。
- 使用异步库:确保所有I/O绑定的任务(例如文件读/写、外部API调用)都以异步方式处理,以获得最佳性能。
- 测试更高的并发性:进行更高并发量的负载测试(例如,500+用户),以充分发挥异步的优势。
六、结论
如果你的应用程序需要处理大量并发用户,并严重依赖于I/O绑定任务,那么异步FastAPI可以提供更好的性能、可扩展性和响应能力。不过,对于更简单的用例,可以选择同步实现。