













本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面 && 笔者理解
随着自动驾驶技术的不断进步,我们可能正在进入一个连接自动驾驶车辆(Connected Autonomous Vehicles, 简称CAVs)和人工驾驶车辆(Human-Driven Vehicles, 简称HDVs)共存的时代。尽管CAVs在提高交通安全和效率方面具有巨大潜力,但它们在开放道路上的表现还远未达到令人满意的程度。根据加利福尼亚州机动车管理局的报告,51%的车辆解绑是由于CAVs的决策失败造成的。此外,北京自动驾驶车辆道路测试报告揭示,高达91%的解绑事件发生在与其他车辆交互时,这表明目前的自动驾驶技术还不足以应对复杂的交互场景。为了改善这个问题,利用CAVs的协同驾驶能力是一个较为有希望的方法。
针对不同场景下的协同驾驶问题,目前流行的方法大致可以分为以下几种:
- 基于优化的方法旨在最大化或最小化目标函数以实现特定目标。但是基于优化的方法往往未能在驾驶过程中明确考虑法规和社会规范,使得他们的决策结果难以理解。
- 基于规则的方法在形式上简单,因此计算效率高。然而,尽管可以将基于规则的方法与交通法规结合起来,但预设的规则通常会导致鲁棒性差。
- 基于学习方法,如深度学习和强化学习。这些方法已成功应用于交叉口、合并区域和高速公路等环境中的协同驾驶,表现出良好的性能。但基于学习模型的性能在转移到未经训练的环境中时往往会显著下降。
另一方面,近年来Transformer模型和大型语言模型(LLMs)的快速发展为实现协同决策提供了新的可能性。这些模型已经在自然语言处理和智能体决策制定等领域展示了巨大的潜力。在这种背景下,作者提出了一个交互式和可学习的LLM驱动的协同驾驶框架,用于全场景和全Cooperative Driving Automation(简称CDA)。
- 论文链接:https://arxiv.org/pdf/2409.12812
- 开源链接:https://github.com/FanGShiYuu/CoDrivingLLM
问题表述
目前,CAVs在开放道路上的表现仍然不是很理想。在某些场景下,CAV的事故率甚至是人类驾驶员的5.25倍,这显然不能满足人们对自动驾驶技术的期望。而CAVs的通信能力使其能够实现互联互通和相互协助。因此,利用协同驾驶能力是提高CAVs性能是作者认为非常有前途的方式。

观测空间 (Observation Space)

动作空间 (Action Space)

模型结构
CoDrivingLLM主要包括三个模块:环境模块、推理模块和记忆模块。
A. 总体架构
图2展示了CoDrivingLLM中的主要模块及其逻辑关系,包括三个主要模块:环境模块、推理模块和记忆模块。环境模块根据上一个时间步的CAV和HDV的动作更新当前场景信息,包括所有车辆的状态,如位置、速度等。接下来,作者设计了一个集中-分布式结合的LLM推理模块。基于SAE J3216标准定义的CDA的四个级别,作者将这个推理模块整合了四个子功能:状态共享、意图共享、协商和决策。通过结合思维链(Chain-of-Thought, COT)方法,作者将推理过程中的每个子功能顺序连接起来,以增强决策的安全性和可靠性。在这个过程中,每个CAV使用LLMs进行分布式的高级逻辑推理,完成不同级别的协同驾驶,并利用框架内的冲突协调器进行集中冲突解决,进一步提高安全性。最后,推理过程中的场景描述、冲突描述和最终决策以向量化形式存储在记忆数据库中。在随后的推理中,CAV可以参考最相似的过去记忆作为经验,使设计的CAV能够在驾驶过程中不断学习和提高其能力。

B. 环境模块
环境模块包括两个子模块:
- 环境动态模拟子模块,它模拟真实世界的环境动态,为协同驾驶框架提供现实的背景交通流和训练反馈;
- 基于模型的控制执行子模块,为LLM提供基于模型的车辆控制单元,提高动作执行的准确性和成功率。
环境动态模拟子模块:真实世界的反馈对于训练一个稳定和可靠的协同决策模型至关重要。为了确保模拟的真实性和可靠性,作者在环境动态模块中考虑了一个混合人自动驾驶环境,引入不受控制的人工驾驶车辆,为协同驾驶框架创造更加现实的背景交通流。这些不受控制的车辆不参与协同驾驶任务,意味着它们不共享它们的意图,并仅基于它们自己的决策逻辑运行。鉴于IDM(Intelligent Driver Model)和MOBIL(Minimizing Overall Braking Induced by Lane changes)的结合被广泛用于表征人类驾驶行为,并且在交叉口、环形交叉口和合并区域等各种场景中都显示出良好的结果,作者分别利用IDM和MOBIL来代表HDV的纵向和横向行为。HDV的加速度由IDM给出,如下所示:
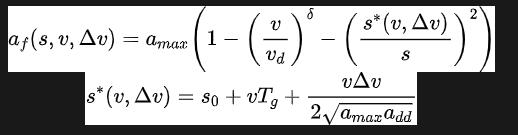

基于模型的控制执行子模块:虽然LLMs具有强大的推理能力,但它们在精确的数学计算和低级车辆运动控制方面表现不佳。为了解决这个问题,作者设计了一个基于模型的控制执行子模块。在这个模型中,作者使用基于模型的方法将推理模块的语义输出转换为加速度和前轮角度,然后用于更新车辆在下一个时间步的位置、速度和其他信息。具体来说,加速度和前轮角度都由相对简单的比例控制器控制,计算公式如下:

C. 推理模块
作者构建了一个集成的推理模块,从状态共享到意图共享、协商,最终决策。该模块以思维链的方式运作,首先从环境中提取周围车辆的信息以创建场景描述。然后,它将车辆的状态组织成冲突对,形成冲突描述。为了确保在冲突期间车辆决策的一致性并避免碰撞,作者开发了一个基于LLM的冲突协调器。该协调器将当前的冲突描述与交通规则结合起来,确定每个冲突组的优先级顺序。最后,每个CAV根据冲突协调器的建议和自己的情境描述做出决策。
State-perception:状态感知功能负责获取和处理当前环境的信息,包括动态数据,如车道信息和车辆信息。CAV被允许与他人交换信息,因此为后续更高级别的CDA铺平了道路。状态感知功能可以构建一个完整准确的驾驶环境识别,为后续推理提供可靠的基础。
Intent-sharing:意图共享功能,传达车辆驾驶意图给其他CAV,是协同驾驶的一个关键优势。从宏观到微观,驾驶意图主要包括共享预期车道和预期速度。通过意图共享,其他车辆可以更好地理解自我车辆的意图,使它们能够在避免冲突的同时做出决策。
Negotiation:作者设计了一个冲突协调器来解决冲突,并实现寻求共识的合作。冲突协调器识别当前环境中所有潜在的冲突,并根据所涉及两辆车的当前状态评估每个冲突的严重程度。为了量化冲突的严重程度,以时间差作为替代指标定义为:


冲突协调器根据冲突的严重程度确定每对冲突车辆的通行顺序。在此过程中,交通规则和驾驶过程中的社交规范同时被冲突协调器考虑。例如,如图1所示,根据交通规则,转弯车辆应该让直行车辆先行。因此,在协商后,冲突协调器确定CAV2应该在这组冲突中让行。协商结果和原因被发送到决策功能以做出最终决策。然而,需要注意的是,协商结果是建议性的,最终决策还取决于自我车辆周围环境的其他因素。
D. 记忆模块
日常生活中,新司机通过持续的驾驶实践积累经验,评估不同行为的效果,并从中学习以提高驾驶技能。借鉴这一机制,作者引入记忆模块,使CAV能够从过去的经历中学习,并利用这些知识进行未来的互动。这一过程也被称为检索增强生成(RAG)。RAG赋予LLMs访问特定领域或组织内的知识数据库的能力。这种能力允许在不需要模型重新训练的情况下,经济高效地改进LLM输出,确保在解决特定领域问题时的相关性、准确性和实用性。具体来说,设计的记忆模块包含两个主要功能:记忆增强和记忆检索。
记忆增强:记忆增强功能评估CAV在前一个场景中的行为影响,以确定这些行为是否加剧了冲突。如果CAV的行为导致危险增加,系统会产生负面反馈,例如:“你的行为加剧了冲突;应避免采取类似行动。”这种反馈机制在场景、行为和结果之间建立了联系,将这些映射存储在记忆数据库中以供将来参考。在每次调用LLM进行推理之前,从记忆数据库中检索与当前场景最相关的记忆以增强提示,从而避免重复过去的错误。
记忆检索:随着互动数量的增加,记忆数据库将累积众多过去的经历。将所有记忆作为提示输入会导致冗余,使得CAV在推理过程中难以提取关键信息。为了解决这个问题,采用记忆检索功能,在利用记忆指导推理之前,从数据库中提取与当前场景最相关的记忆。具体来说,当前场景描述和冲突描述被转换为向量形式,并使用余弦相似度根据它们与当前场景的相关性对库中的记忆进行排名。排名靠前的记忆随后被选为CAV推理的提示的一部分。这些类似的记忆,被称为少量体验,被注入到CAV的推理模块中,使CAV能够从过去的错误中学习。记忆模块的引入不仅提高了CAV在复杂环境中的决策能力,而且赋予了类似人类的持续学习能力。通过不断从过去的经历中学习,CAV能够更好地适应动态环境,提高驾驶安全性,减少交通事故,提高其在现实世界应用中的可靠性和实用性。
实验结果
实验设置
仿真环境作者基于highway-env开发了环境模块。设计了三种场景来进行实验,如图4所示,包括四车道高速公路场景、合并场景和单车道无信号交叉口。上下文交通流和HDV的设置遵循作者框架的环境模块的说明。

实验细节作者使用GPT-4o mini作为基础LLM模型,进行高层次的逻辑思考和判断。每个模拟环境中控制四个CAV。此外,所有不同设置的场景都重复20次,使用不同的随机种子以获得最终结果。成功率被用作评估所有方法性能的指标。在一个案例中,如果所有CAV都能安全地完成驾驶任务并到达目的地,则该案例成功。成功率表示成功案例数与总案例数的比率。
协商模块消融研究
通过共享状态和意图,合作驾驶可以提供额外的信息,帮助冲突方协调他们的决策。为了实现这一点,作者在推理过程中引入了一个协商模块。通过建立一个LLM驱动的冲突协调器,将交通规则和场景描述整合在一起,以产生建议的交通顺序来协助最终决策,从而提高交互能力。为了验证冲突协调器在提高交互能力方面的有效性,作者进行了消融实验,比较了CoDrivingLLM在各种场景下有无协商模块的成功率。此外,作者还选取了一个案例来分析协商功能如何提高安全性。

如图5所示,在高速公路场景中,有无协商模块并不影响合作驾驶的性能,因为作者的方法始终实现了100%的成功率。作者将其归因于高速公路场景中缺乏重大的交互冲突,协商模块没有机会有效干预。然而,在合并和交叉口场景中,协商模块显著提高了决策的成功率。在这两种类型的场景中,车辆之间不可避免地会出现冲突,只有他们的决策一致,才能避免碰撞。具体来说,在合并场景中,CAV决策的成功率从33%提高到75%,在交叉口场景中,成功率从15%上升到78%。协商模块在交叉口场景中影响最大,因为交互的复杂性和交通冲突的密度远高于其他两种场景。这表明作者的协商模块有效地处理了复杂的交通冲突和交互场景,是整体合作驾驶框架的关键组成部分。
记忆模块消融研究
记忆模块旨在使CAV能够从过去的经验中学习,避免重复过去的错误。作者也做了记忆模块的消融实验。他们比较了在0次、2次和5次经验(shots)下,CoDrivingLLM在不同场景中的性能。这里的"shots"指的是在推理前向模型注入最相似过去经验的次数。在高速公路场景中,由于车辆冲突和交互挑战较少,即使不使用记忆模块,CoDrivingLLM也能达到100%的成功率,且2次和5次经验的添加对成功率没有影响。在合并和交叉口场景中,从0次经验增加到2次经验时,决策成功率显著提高,合并场景从78%增至90%,交叉口场景从75%增至85%。然而,当经验从2次增加到5次时,性能略有下降。这表明过多的记忆可能并不总是增强LLM的决策能力,过量的重复或低价值记忆可能会占用LLM的上下文窗口,降低其关注其他相关感知信息的能力,从而可能产生负面影响。所以作者认为,记忆模块为CoDrivingLLM提供了学习效用,通过持续从经验中学习,CAV能更好地适应动态环境,提高驾驶安全性,减少交通事故,增加现实应用的可靠性和实用性。
与其他方法的比较
作者选择在无信号交叉口场景下做对比实验,对比包括基于优化的方法(iDFST)、基于规则的方法(Cooperative game)和基于学习的方法(MADQN)。
整体性能作者总结了每种方法的成功率。根据表I中的数据,CoDrivingLLM的表现优于其他方法,达到了90%的成功率。iDFST和Cooperative Game方法略逊一筹,都达到了85%的成功率。

安全评估作者对各种方法进行了全面的安全性分析,使用了交通工程中公认的安全性参数PostEncroachment Time (PET)。这一指标有效地量化了车辆在复杂交通场景中的安全性和交互强度。根据图9和表I中的结果,iDFST方法和CoDrivingLLM表现都很出色,平均PET值分别为15.1秒和10.3秒。相反,MADQN和Cooperative方法的PET值分别为5.7秒和3.7秒,表明在交通环境中的决策交互中存在更高的风险。此外,PET值较低意味着存在更高的安全风险。通常,PET值小于1.5秒表示应避免的严重冲突。根据图9,所提出的CoDrivingLLM的PET分布主要集中在1.5秒以上。尽管MADQN的PET分布也没有低于1.5秒的值,但考虑到其成功率仅为20%,存在大量的碰撞。因此,CoDrivingLLM在安全性方面表现最佳。

效率评估作者还使用旅行速度评估了所有方法的效率。如表I所示,MADQN在测试期间达到了最高的平均速度6.1 m/s。然而,这种效率是以牺牲安全性和整体性能为代价的。iDFST方法在安全性和成功率方面表现良好,但驾驶效率低下,过度低速行驶导致平均速度仅为4.1 m/s。尽管基于规则的方法在安全性方面表现良好,但其低效率一直是普遍存在的问题。相比之下,CoDrivingLLM在安全性和效率之间取得了平衡,保持了5.7 m/s的高平均速度,同时确保了安全性。总之,CoDrivingLLM有效地平衡了安全性和效率,实现了最佳的整体性能,明显展示了其优越性。






























