













译者 | 朱先忠
审校 | 重楼
本文将通过具体的实战代码示例来探索谷歌开源Gemini Flash模型的学习曲线和采样效率。
在大多数常见的机器学习和自然语言处理中,实现最佳性能通常需要在用于训练的数据量和由此产生的模型准确性之间进行权衡。本文中,我们将以PII(个人识别信息)脱敏算法数据集为例,探讨使用微调谷歌Gemini Flash模型的情况下样本效率的概念。我们将研究随着样本数量的增加而进行的微调如何影响调整后的模型的功能。
何谓样本效率,为什么它很重要?
样本效率(Sample efficiency)是指模型在有限的训练数据量下实现高精度的能力。这是机器学习开发的一个关键方面,尤其是在处理大型标记数据集可能稀缺或获取成本高昂的任务或领域的情况下。一个样本高效的模型可以从更少的样本中有效地学习,减少与数据收集和训练相关的时间、成本和精力。LLM被证明是非常有样本效率的,甚至能够在很少的样本情况下进行情境学习,也能够显著提高性能。本文的主要目标是以谷歌开源的Gemini Flash模型为例来探讨这方面的问题。我们将在不同设置条件下评估此LLM模型,然后绘制学习曲线,以便更直观地了解训练数据量是如何影响性能的。
显示训练得分和交叉验证得分的学习曲线示例(来源:维基百科)
微调Gemini Flash模型实现PII脱敏实战
为了展示样本效率的影响,我们将进行一项实验,重点是微调Gemini Flash模型,从而应用于个人识别信息脱敏。我们将使用Hugging Face公司的公开个人识别信息脱敏数据集,并评估模型在不同微调场景下的性能:
- 零样本设置:评估预先训练的Gemini Flash模型,无需任何微调。
- 小样本设置(3-shot):在要求模型个人识别信息脱敏新文本之前,为模型提供3个样本。
- 使用50|200|800|3200|6400个样本进行微调:使用从小到大的“PII/Masked(个人识别信息明文/个人识别信息密文)”对数据集对模型进行微调。
对于每种设置,我们将在200个句子的固定测试集上评估模型的性能,使用BLEU(bilingual evaluation understudy:双语替换测评)指标来衡量生成的脱敏文本的质量。该指标能够评估模型输出和脱敏句子之间的重叠性,提供脱敏准确性的定量衡量。
实验限制
这个小实验的结果可能不会直接推广到其他使用场景或数据集情况下。另外,微调的最佳数据量取决于各种因素,包括任务的性质和复杂性、数据的质量以及基础模型的具体特征等。
我的建议是,你可以从这篇文章提供的代码中获得一些灵感,或者:
- 如果你已经有了数据,可以直接将其应用于你的使用场景,这样你就可以看到你的训练曲线是否变慢了(这意味着,你的收益正在显著下降)
- 或者,如果你没有数据的话,那么可以为你所遇到的同类问题(分类、命名实体识别、摘要)和类似的难度级别找到一个数据集。这样的话,你就可以通过绘制学习曲线来了解你自己的任务需要多少数据。
实验数据
我们将使用在Huggingface上共享的PII(个人身份信息)掩蔽数据集。
该数据集中包含两对文本,一对是带有脱敏信息的原始文本,另一对文本隐藏了所有原始个人身份信息。
举例
输入:
目标:
注意,上面数据是经过合成处理的;所以,这里实际上没有共享真正的个人身份信息。
我们的目标是建立从源文本到目标文本的映射,以自动隐藏所有个人身份信息。
数据许可:https://huggingface.co/datasets/ai4privacy/pii-masking-200k/blob/main/license.md。
编程实现
我们将提供一些编程代码,以方便加速此实验进程。编码中,我们将利用Hugging Face数据集库加载个人身份信息脱敏数据集,并利用google.generativeai库与Gemini Flash交互,还将利用evaluate库来计算BLEU(双语替换测评)分数。
此代码段实现安装项目所需的库,包括:
- 数据集:便于从Hugging Face加载和处理数据集。
- evaluate库:允许使用SacreBLEU等评估指标。
- google-generativeai:允许与谷歌的Gemini API交互。
首先,我们进行数据加载和拆分:
接下来,我们尝试为该任务提示零样本。这意味着,我们向LLM解释任务,并要求它从原始文本中生成个人身份信息脱敏数据。这是通过使用一个列出所有需要脱敏标签的提示来完成的。
我们还将LLM API的调用并行化,以稍微加快速度。
最后,我们使用BLEU评分进行评估。它是一种基于精度的度量方案,通常用于机器翻译,将模型输出与参考句子进行比较。虽然这种方法存在一定局限性,但却易于应用,适用于像我们手头这样的文本到文本任务。
现在,让我们进一步探讨有关提示的问题。除了向LLM解释任务外,我们还将向它展示三个我们期望它做什么的例子。这种技巧通常有助于提高性能。
最后,我们来尝试一下使用微调方案。在这里,我们只使用Gemini API的托管服务。它现在是免费的,所以不妨使用一下。注意,我们将使用越来越多的数据,并比较每种数据的性能。
运行调优任务再简单不过了:我们只需使用genai.create_tuned_model函数来处理数据、迭代次数、学习率和参数。
训练任务是异步的,这意味着我们不必等待程序的运行结束。不过,程序的执行要排队,通常在24小时内完成。
你可以使用以下代码片段来检查一下调优任务的状态:
实验结果对比分析
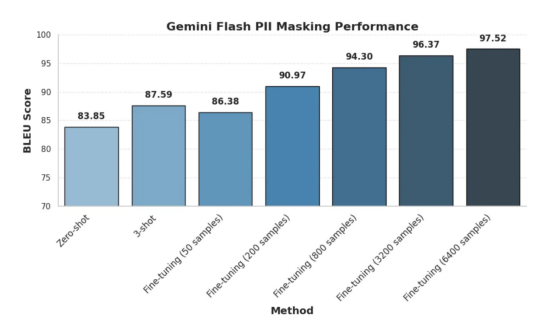
构建PII数据脱敏函数时不同设置方案结果比较
容易看出,PII数据脱敏算法通过添加更多用于微调的训练数据提高了性能。
零样本和小样本情况
由上图可知,零样本方法获得了83.85的令人尊敬的BLEU分数。这表明,即使没有任何训练样本,模型也会对任务有一些基本的理解。然而,实验中只提供三个样本(3-shot)就可以将分数提高到87.59,这说明了即使是有限的样本情况下,这些样本在LLM情境学习中也是非常有效的。
微调情况
实验一开始,我们使用50个样本的小数据集进行微调,得出的BLEU得分为86.38,略低于3-shot方法。然而,随着训练数据的增加,性能显著提高。在使用了200个样本的情况下,BLEU得分跃升至90.97,而在使用了800个样本时则达到了94.30。当使用最大数量达到6400个样本测试的情况下达到最高BLEU分数97.52。
结论
我们最后得到的基本结论是:一切都在意料之中,随着数据的增加,性能也会提高。虽然Gemini Flash模型的零样本和小样本功能令人印象深刻,证明了其具有推广到新任务的能力,但是使用足够大的数据进行微调时也会显著提高其准确性。这里唯一出乎意料的是,如果训练数据的数量太少或质量太低,那么小样本提示结果的准确率有时会胜过经过微调后的准确率。
总之,我们可以得到如下几条关键结论:
- 要实现高性能目标,微调可能是必要的:即使少量的微调数据也比零样本和小样本方法产生巨大的改进。
- 更多的数据通常会带来更好的结果:随着微调数据集大小的增加,调优后的模型的准确脱敏个人身份信息的能力也会提高,如上图中BLEU分数的上升所表明的。
- 收益递减:虽然更多的数据通常会产生更好的数据结果,但也可能会出现性能增长开始趋于平稳的时刻。确定这一点可以帮助我们更好地权衡标签预算和调整模型质量之间的权衡。
还需要说明的是,在我们的例子中,稳定期从3200个样本开始,任何高于这个水平的样本都会产生正的但递减的回报。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:How Much Data Do You Need to Fine-Tune Gemini?,作者:Youness Mansar





























