在当前数据驱动的商业环境中,人工智能(AI)和机器学习(ML)已成为各行业决策制定的关键工具。从金融机构的信贷风险预测到医疗保健提供者的疾病诊断,AI模型正在塑造对生活和业务有深远影响的结果。

然而随着这些模型日益复杂化,一个重大挑战浮现:即"黑盒"问题。许多先进的AI模型,尤其是深度学习算法,其运作机制甚至对其创建者而言也难以理解。这种不透明性引发了几个关键问题:
- 信任缺失:利益相关者可能对难以理解的决策过程持谨慎态度。
- 监管合规:多个行业要求可解释的决策流程。
- 伦理考量:不可解释的AI可能无意中延续偏见或做出不公平决策。
- 改进困难:若不了解决策过程,优化模型将面临挑战。
LIME(模型无关的局部解释)应运而生,旨在解析AI黑盒,为任何机器学习模型的个别预测提供清晰、可解释的说明。
LIME的起源:简要历史
LIME于2016年由华盛顿大学的Marco Tulio Ribeiro及其同事Sameer Singh和Carlos Guestrin引入机器学习领域。他们的开创性论文"'Why Should I Trust You?': Explaining the Predictions of Any Classifier"在第22届ACM SIGKDD国际知识发现与数据挖掘会议上发表。
Ribeiro团队受到AI社区面临的一个核心问题驱动:如果我们不理解模型的决策机制,如何信任其预测?鉴于复杂的不透明模型(如深度神经网络)在高风险决策过程中的广泛应用,这个问题尤为重要。
研究人员认识到,尽管全局可解释性(理解整个模型)对复杂AI系统通常难以实现,但局部可解释性(解释单个预测)可以提供有价值的洞察。这一认识促成了LIME的开发。
LIME的设计基于三个核心原则:
- 可解释性:解释应易于人类理解。
- 局部保真度:解释应准确反映模型在被解释预测附近的行为。
- 模型无关:该技术应适用于解释任何机器学习模型。
自引入以来,LIME已成为可解释AI领域最广泛使用的技术之一。它在各行业中得到应用,并推动了对模型解释方法的进一步研究。
LIME的工作原理
LIME的定义
LIME(Local Interpretable Model-Agnostic Explanations)是一种解释技术,能以人类可理解的方式阐释任何机器学习分类器的预测结果。它可以被视为一个高效的解释器,能将复杂的AI模型转化为易懂的术语,无论原始模型的类型如何。
LIME的核心原理
LIME基于一个基本假设:虽然复杂AI模型的整体行为可能难以理解,但我们可以通过观察模型在特定预测周围的局部行为来解释个别预测。
这可以类比为理解自动驾驶汽车在特定时刻的决策过程。LIME不是试图理解整个复杂系统,而是聚焦于特定时刻,基于当时的环境因素创建一个简化的解释模型。
LIME的工作流程
1、选择预测实例:确定需要解释的AI模型特定预测。
2、生成扰动样本:在选定预测的邻域生成略微改变的输入数据变体。
3、观察模型响应:记录模型对这些扰动样本的预测变化。
4、构建简化模型:基于这些观察结果,创建一个简单的、可解释的模型,以模拟复杂模型在该局部区域的行为。
5、提取关键特征:从简化模型中识别对该特定预测最具影响力的因素。
这一过程使LIME能够为特定实例提供模型决策过程的洞察,对于寻求理解和解释AI驱动决策的企业而言,这一功能极为重要。
LIME在实际业务中的应用
以下案例展示了LIME在不同行业和数据类型中的应用,凸显了其多样性和对业务运营的影响。
金融领域:信用风险评估
场景:某大型银行使用复杂的机器学习模型进行信用风险评估和贷款审批。该模型考虑数百个变量来得出结论。尽管机器决策可能基于复杂的模式匹配而具有准确性,但这使得贷款官员难以理解并向客户解释决策依据。
# 导入必要的库
# 加载数据集
# 使用来自openml的德国信用数据集
credit = fetch_openml('credit-g', version=1, as_frame=True)
X = credit.data
y = credit.target
# 将目标变量转换为二进制(好/坏到0/1)
y = y.map({'good': 0, 'bad': 1})
# 预处理:使用独热编码将分类特征转换为数值
X = pd.get_dummies(X, drop_first=True)
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化数据
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练随机森林分类器
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 初始化LIME
explainer = lime.lime_tabular.LimeTabularExplainer(
training_data=X_train,
feature_names=X.columns,
class_names=['Good', 'Bad'],
mode='classification'
)
# 遍历测试集中的多个实例
for i in range(3): # 可根据需要调整解释的实例数量
# 打印实际记录
actual_record = X_test[i]
print(f"Actual record for instance {i}:")
print(pd.DataFrame(actual_record.reshape(1, -1), columns=X.columns))
# 生成LIME解释
exp = explainer.explain_instance(X_test[i], model.predict_proba, num_features=5)
# 显示LIME解释
exp.show_in_notebook(show_table=True)
exp.as_pyplot_figure()
plt.show()
# 提取并打印解释详情
explanation = exp.as_list()
print(f"Explanation for instance {i}:")
for feature, weight in explanation:
print(f"{feature}: {weight:.2f}")
print("\n")
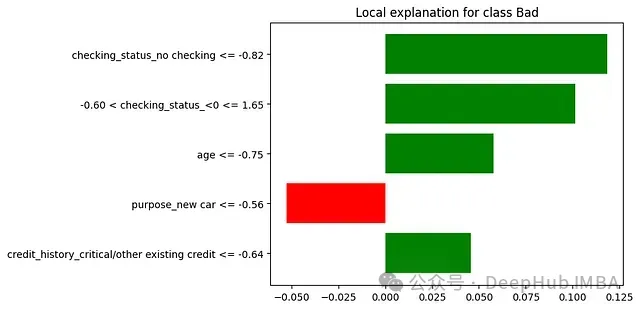

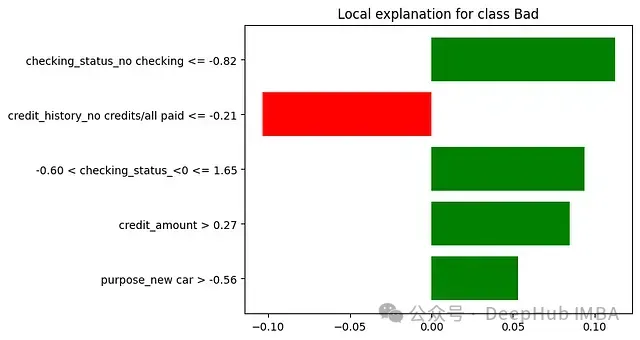

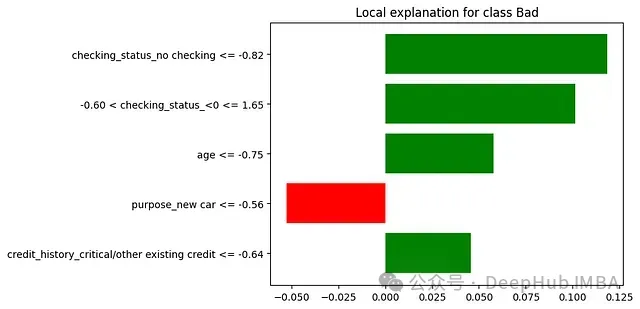
未使用LIME时:若银行使用模型判定某小企业主不符合贷款条件,贷款官员只能告知申请人AI模型认为其风险较高,而无法提供具体理由。
使用LIME时:LIME能够分析决策并提供如下解释:银行官员现可以准确地传达决策理由 — "该贷款申请被归类为高风险,主要基于以下因素:
1.债务收入比:65%(对高风险决策的贡献为+35%)
- 显著高于我们首选的36%比率
2.近期信用查询:过去6个月内7次(+25%)
- 表明频繁寻求信贷,可能构成风险因素
3.企业年限:14个月(+20%)
- 我们通常偏好运营至少24个月的企业
业务影响:
- 提高客户沟通透明度:贷款官员能向申请人提供具体、可行的反馈,有助于其改进未来的申请。
- 确保公平贷款实践:通过审查多个决策的LIME解释,银行可以验证模型决策过程中是否存在无意的偏见。
- 模型优化:信用风险团队可以验证模型是否考虑了适当的因素,并在必要时进行调整。例如,如果发现行业风险因素的权重过高,可以考虑降低其影响。
- 监管合规:在审计时,银行可以为每个贷款申请展示清晰、可解释的决策过程。
- 员工培训:可以培训贷款官员理解这些解释,提高其与AI系统协同工作的能力。
文本数据分析:酒店业客户反馈评估
场景:本例展示了LIME如何在基于文本分类的机器学习模型中提供解释。考虑一个大型连锁酒店利用AI模型分析来自各种平台的数千条客户评论,将它们分类为特定的赞扬或关注领域(如清洁度、服务、设施)。
# 导入必要的库
# 加载数据集
file_path = '/content/sample_data/Hotel_Reviews.csv'
data = pd.read_csv(file_path)
# 合并'Negative_Review'和'Positive_Review'列
negative_reviews = data[['Negative_Review']].rename(columns={'Negative_Review': 'Review'})
negative_reviews['Sentiment'] = 'negative'
positive_reviews = data[['Positive_Review']].rename(columns={'Positive_Review': 'Review'})
positive_reviews['Sentiment'] = 'positive'
# 连接正面和负面评论
reviews = pd.concat([negative_reviews, positive_reviews])
reviews = reviews[reviews['Review'].str.strip() != ''] # 移除空评论
# 将标签编码为二进制
reviews['Sentiment'] = reviews['Sentiment'].map({'positive': 1, 'negative': 0})
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(reviews['Review'], reviews['Sentiment'], test_size=0.2, random_state=42)
# 向量化文本数据并移除停用词
vectorizer = TfidfVectorizer(max_features=1000, stop_words='english')
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
# 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train_tfidf, y_train)
# 初始化LIME
explainer = lime.lime_text.LimeTextExplainer(class_names=['negative', 'positive'])
# 定义预测函数
def predict_proba(texts):
texts_transformed = vectorizer.transform(texts)
return model.predict_proba(texts_transformed)
# 遍历测试集中的多个实例
for i in range(5): # 可根据需要调整解释的实例数量
# 打印实际评论
actual_review = X_test.iloc[i]
print(f"Explanation for instance {i}:")
print(actual_review)
# 生成LIME解释
exp = explainer.explain_instance(actual_review, predict_proba, num_features=6)
# 显示LIME解释
exp.show_in_notebook()
exp.as_pyplot_figure()
plt.show()
# 提取并打印解释详情
explanation = exp.as_list()
print(f"Explanation for instance {i}:")
for phrase, weight in explanation:
print(f"{phrase}: {weight:.2f}")
print("\n")
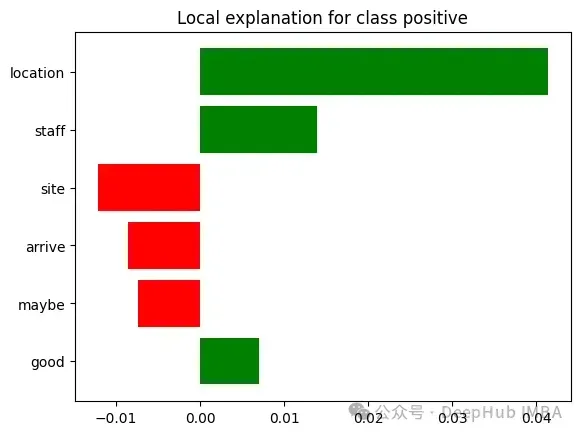

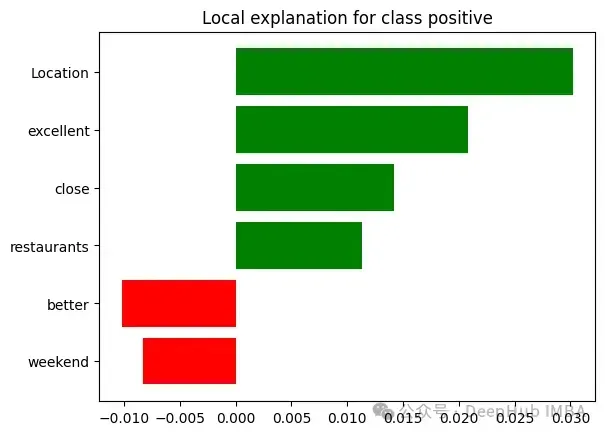
未使用LIME时:客户体验团队观察到某家酒店因"服务质量差"而被标记,但无法理解导致这一分类的具体问题。
使用LIME时:对于一条被归类为"服务质量差"的评论,LIME可能提供如下解释:"该评论被归类为'服务质量差',基于以下关键问题:
- '等待30分钟才能办理入住'(+40%影响)
- '员工对请求反应迟钝'(+30%影响)
- '客房服务订单错误'(+15%影响)
- '没有为不便道歉'(+10%影响)
- '经理不在场'(+5%影响)
值得注意的是,诸如'房间干净'和'位置很好'等正面短语对这一分类的影响微乎其微。"
业务影响:
- 精准改进:酒店管理层可以聚焦需要改进的具体领域,如缩短入住时间和提高员工响应速度。
- 培训机会:人力资源部门可以开发针对性的培训计划,解决已识别的问题,例如关于如何迅速处理客人请求的研讨会。
- 实时警报:系统可以设置为在收到含有强烈负面服务指标的评论时立即通知管理人员,允许快速响应和服务补救。
- 趋势分析:通过长期汇总LIME解释,连锁酒店可以识别不同物业或季节性的反复出现的问题,为更广泛的战略决策提供依据。
- 客户沟通:营销团队可以利用正面评论中的洞察(即使在整体负面反馈中)来突出酒店的优势。
- 模型验证:数据科学团队可以确保模型正确解释微妙或讽刺的语言,必要时进行调整。
图像数据分析:制造业质量控制
场景:本例展示了LIME如何用于解释基于图像分类的机器学习模型。
为了说明图像可解释性,我们将使用MNIST数据集,该数据集包含大量从0到9的手写数字图像。
# 导入必要的库
# 加载MNIST数据集(用作制造组件图像的代理)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 预处理数据
X_train = X_train.reshape(-1, 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(-1, 28, 28, 1).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 训练一个简单的CNN模型
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 3)),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train_rgb, y_train, epochs=5, batch_size=200, verbose=1, validation_data=(X_test_rgb, y_test))
# 初始化LIME
explainer = lime.lime_image.LimeImageExplainer()
# 定义预测函数
def predict_proba(images):
return model.predict(images)
# 选择实例进行解释
for i in range(5): # 可根据需要调整解释的实例数量
# 获取一个实例进行解释
image = X_test_rgb[i]
explanation = explainer.explain_instance(image, predict_proba, top_labels=1, hide_color=0, num_samples=1000)
# 获取顶级标签的解释
temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=False)
# 显示带有解释的图像
plt.imshow(mark_boundaries(temp, mask))
plt.title(f"Explanation for instance {i}")
plt.show()
# 打印详细解释
print(f"Explanation for instance {i}:")
print(explanation.local_exp[explanation.top_labels[0]])
print("\n")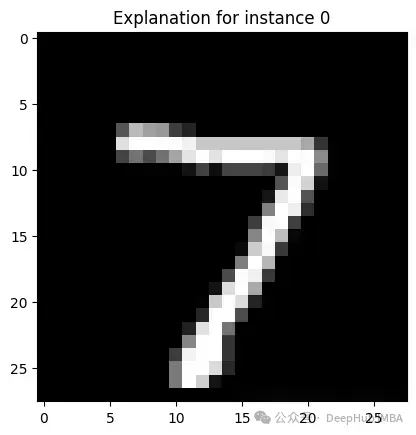
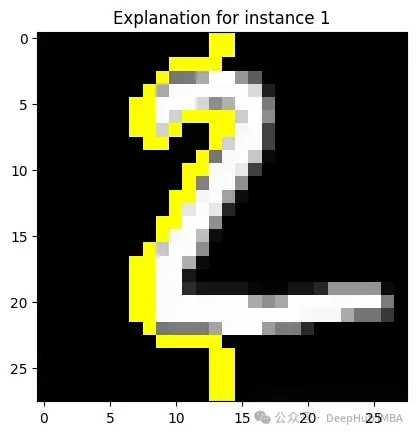
未使用LIME时:类似于前面使用MNIST的例子 - 我们已经看到数字被识别,但无法确定AI系统如何进行判断
使用LIME时:对于一个被标记为有图像,LIME可能提供一个热图叠加层,突出显示模型是如何识别这个数字的,这对于研究模型的原理十分重要
LIME的优势与局限性
尽管LIME已被证明是解释AI决策的有力工具,但企业在应用时需要充分了解其优势和局限性。这种平衡的认识有助于组织有效地使用LIME,同时意识到其潜在的不足。
LIME的优势
- 模型无关性:LIME可以解释任何机器学习模型的预测,无论其复杂程度如何。这种通用性使其在各种商业环境中都具有价值。
- 解释直观性:LIME以原始特征的形式提供解释,使非技术背景的利益相关者也能轻松理解。
- 局部保真度:通过专注于解释个别预测,LIME能为特定实例提供高度准确的解释,即使模型的全局行为复杂。
- 可定制性:该方法允许在解释类型(如决策树、线性模型)和解释中包含的特征数量方面进行定制。
- 视觉表现力:LIME可以提供视觉解释,对图像和文本数据特别有效,增强了可解释性。
- 增进信任:通过提供清晰的解释,LIME有助于在用户、客户和监管机构中建立对AI系统的信任。
- 辅助调试:LIME可以通过揭示意外的决策因素,帮助数据科学家识别模型中的偏见或错误。
LIME的局限性和挑战
- 局部vs全局解释:LIME专注于局部解释,可能无法准确表示模型的整体行为。如果用户试图从这些局部解释中概括,可能导致误解。
- 稳定性问题:由于其基于采样的方法,LIME有时会在多次运行中为同一预测产生不同的解释。这种不稳定性在高风险决策环境中可能产生问题。
- 特征独立性假设:LIME在创建解释时假设特征独立,这可能不适用于许多具有相关特征的真实世界数据集。
- 计算开销:生成LIME解释在计算上可能较为昂贵,特别是对于大型数据集或实时应用。
- 核宽度敏感性:LIME中核宽度的选择可能显著影响结果解释。选择适当的宽度可能具有挑战性,可能需要领域专业知识。
- 非线性关系处理:LIME使用的线性模型来近似局部行为可能无法准确捕捉复杂的非线性关系。
- 对抗性攻击风险:研究表明,可以创建行为与其LIME解释不一致的模型,可能误导用户。
- 因果关系洞察不足:LIME提供相关性解释而非因果性解释,这可能限制其在理解模型真实决策过程方面的应用。
- 高维数据挑战:随着特征数量的增加,LIME解释的质量可能会降低,使其对非常高维的数据集效果较差。
- 解释偏见:LIME解释的呈现方式可能影响其解读,可能引入人为偏见。
未来发展方向和新兴趋势
随着企业持续应对可解释AI的需求,以下几个发展方向值得关注:
- 技术融合:将LIME与其他解释方法(如SHAP,SHapley Additive exPlanations)结合,以获得更全面的洞察。
- 自动决策支持:开发不仅能解释AI决策,还能基于这些解释提供潜在行动建议的系统。
- 实时解释引擎:研发更快、更高效的LIME实现,以支持高容量应用的实时解释需求。
- 个性化解释:为不同的利益相关者(如技术vs非技术人员,客户vs监管机构)定制解释内容和形式。
- 非结构化数据解释:推进在解释复杂数据类型(如视频或音频)的AI决策方面的技术。
- 联邦可解释性:发展在不损害数据隐私的前提下解释分布式数据集上训练的模型的技术。
- 因果解释:超越相关性,为AI决策提供因果解释的方法。
总结:在AI时代拥抱透明度
LIME代表了可解释AI领域的重大进展,为企业提供了一个强大的工具来洞察其AI模型的决策过程。自2016年Marco Ribeiro及其同事引入以来,LIME已成为数据科学家工具箱中不可或缺的技术,帮助缩小复杂AI系统和人类理解之间的鸿沟。
LIME的优势 - 其模型无关性、直观解释和提供局部洞察的能力 - 使其成为寻求建立信任、确保合规性和改进AI系统的企业的宝贵资产。然而,重要的是要认识到LIME的局限性,包括其对局部解释的关注、潜在的不稳定性以及在处理高维或高度相关数据时的挑战。
随着AI继续发展并渗透到业务运营的各个方面,像LIME这样的技术将扮演越来越重要的角色。它们不仅代表技术解决方案,还象征着向更透明、负责任和以人为中心的AI方法转变。
展望未来,我们可以期待看到可解释AI的进一步发展,以LIME奠定的基础为起点。这可能包括更稳定和高效的解释方法、能够提供因果洞察的技术,以及能够更好地处理真实世界数据复杂性的方法。
对于企业而言,拥抱可解释AI不仅关乎技术合规或模型改进。它是关于培养透明文化,与利益相关者建立信任,并确保AI系统以可解释、道德和符合人类价值观的方式增强人类智能。
在这个AI时代,我们的目标不仅仅是创造更强大的AI系统,而是开发我们可以理解、信任和有效使用以做出更明智决策的AI。LIME和其他可解释AI技术是这一旅程的关键步骤,帮助我们揭示AI的黑盒子,充分发挥其对业务和社会的潜力。