译者 | 布加迪
审校 | 重楼
深度学习大大提高了医疗图像分割的准确度和效率,本文将探讨常用技术及其应用。
采用深度学习技术已经使医疗成像发生了革命性的变化。使用机器学习的这一分支开创了医疗图像分割精度和高效的新时代,而医疗图像分割是现代医疗保健诊断和治疗计划的一个核心分析过程。通过利用神经网络,深度学习算法能够以前所未有的精度检测医疗图像中的异常。
这项技术突破有助于重塑我们对待医疗图像分析的范式。从改善早期疾病检测到促进个性化治疗策略,医疗图像分割中的深度学习正在为更有针对性、更有效的患者护理铺平道路。我们在本文中将深入研究深度学习为医疗图像分割领域带来的变革性方法,探索这些先进的算法如何推动医疗成像发展、乃至推动医疗领域本身发展。
医疗图像分割简介
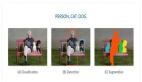
医疗图像分割指将图像分割成不同的区域。每个区域代表一个特定的结构或特征,比如器官或肿瘤。这个过程对于解读和分析医疗图像很重要。它可以帮助医生更准确地诊断疾病。分割有助于规划治疗和跟踪病人的病情变化。
用于图像分割的常见深度学习架构
不妨先看看将深度学习用于图像分割的几种常见架构:
1.U-Net
U-Net有一个U形,有用于上下文的编码器和用于精确定位的解码器。U-Net中的跳过连接保留了编码器层和解码器层的重要细节。U-Net有助于在MRI和CT扫描图中分割器官、脑肿瘤、肺结节及其他关键结构。

2.全卷积网络(FCN)
FCN在整个网络中使用卷积层,而不是使用完全连接的层。这使模型能够生成密集的分割图。FCN借助上采样技术保持输入图像的空间维度。它们有助于对每个像素单独进行分类。比如说,它们有助于在MRI扫描图中发现脑肿瘤,并在CT图像中显示肝脏的位置。

3.SegNet
SegNet兼顾了性能和计算效率。其编码器-解码器设计先减小图像尺寸,然后再将其放大以创建详细的分割图。SegNet在编码期间存储最大池索引,并在解码期间重用它们以提高准确性。它被用于分割视网膜血管、X光下的肺叶及效率很重要的其他结构。

4.DeepLab
DeepLab在保持空间分辨率的同时,使用空洞卷积来扩展接受域。ASPP模块捕获不同尺度的特征。这有助于模型处理分辨率各异的图像。DeepLab用于处理发现MRI扫描图中的脑肿瘤、肝脏病变和心脏细节等任务。

示例:U-Net肺肿瘤分割
现在不妨看一个使用U-Net模型逐步分割肺肿瘤的例子。
1.挂载Google Drive
首先我们将挂载Google Drive,以访问存储在其中的文件。
2.定义文件夹路径
现在我们为Google Drive中含有图像和标签的文件夹设置路径。
3.收集PNG文件
接下来,定义一个函数来收集和排序指定文件夹中的所有PNG文件路径。
4.加载和预处理数据集
接下来我们将定义一个函数,从各自的文件夹中加载和预处理图像和标签。该函数确保图像和标签正确匹配并调整大小。
5.显示图像和标签
现在我们将定义一个函数,并排显示指定数量的图像及其相应的标签。使用前面定义的函数来加载图像和标签,然后显示几个示例以进行可视化。蓝色点代表肿瘤标记。

6.定义U-Net模型
现在是时候定义U-Net模型了。U-Net架构使用Adam优化器。它采用分类交叉熵作为损耗函数。准确度被用作评估指标。
7.训练U-Net模型
这里我们将训练U-Net模型,并将其保存到一个文件中。训练和验证在轮次期间的准确性和损失被绘制成图,以直观显示模型的性能。该模型可用于对新数据进行测试。


医疗图像分割中深度学习的优点
深度学习在医疗分割中的优点有很多。以下是其中几个重要的优点:
提高准确性:深度学习模型非常擅长准确地分割医疗图像。它们可以发现并描绘使用旧方法可能遗漏的细小的或棘手的细节。
效率和速度:这种模型可以快速处理和分析许多图像。它们使分割过程更快,减少了对人力工作的需求。
处理复杂数据:深度学习模型可以处理来自CT或MRI扫描图的复杂3D图像。它们可以处理不同类型的图像,并适应各种成像技术。
医疗图像分割中深度学习的挑战
正如有优点一样,我们也必须牢记使用这项技术面临的挑战。
有限的数据:始终没有足够的已标记医疗图像来训练深度学习模型。创建这些标签很耗时,需要熟练的专家。这使得获得足够的数据用于训练变得困难。
隐私问题:医疗图像含有敏感的患者信息,因此要有严格的规定来保护这些数据的私密性。这意味着可能没有那么多的数据用于研究和训练。
可解释性:深度学习模型可能很难理解,因此很难信任和验证它们的结果。
结语
综上所述,深度学习使医疗图像分割变得更好。卷积神经网络和Transformers等方法改进了我们分析图像的方式,从而带来了更准确的诊断和更好的病人护理。
原文标题:Deep Learning Approaches in Medical Image Segmentation,作者:Jayita Gulati