













大家好,我是小寒
今天给大家介绍一个强大的算法模型,卷积神经网络算法
卷积神经网络( CNN)是一种用于图像识别和处理的深度学习模型,其核心思想是通过卷积运算自动提取图像中的局部特征,从而实现对图像的高效处理和分类。
CNN 的设计灵感来源于生物学中的视觉皮层,能够有效地捕捉图像的空间和局部特征,具有较好的平移、缩放不变性。
 图片
图片
神经网络的基本结构
卷积神经网络由若干层组成,通常包括:
- 输入层:负责接收原始输入数据,例如图像。
- 卷积层:通过卷积核(过滤器)进行局部感知,提取特征。每个卷积核扫描输入图像的不同区域,生成特征映射。
- 非线性激活层:通常使用 ReLU 激活函数,添加非线性能力。
- 池化层:也称为下采样层,通常使用最大池化(Max Pooling)或平均池化(Average Pooling),用于减少特征图的尺寸,降低计算复杂度。
- 全连接层:类似于传统的神经网络层,用于将提取到的特征映射到输出空间。
- 输出层:根据任务类型选择输出函数,分类任务中常用 Softmax 函数输出类别概率。
1.输入层
输入层的主要功能是接收来自外部的数据,通常为图像数据。
在图像处理中,输入层接收的图像通常是三维张量,包括宽度、高度和颜色通道。
例如,一个 28x28 的灰度图像在输入层表示为形状为 (28, 28, 1) 的三维张量,其中 28 表示宽度和高度,1 表示通道数。对于 RGB 彩色图像,通道数为 3,形状为 (28, 28, 3)。
2.卷积层
卷积层是 CNN 中最重要的层,用于从输入数据中提取特征。
卷积层的核心是卷积核(filter,也叫 kernel),它是一个小的矩阵(通常为 3x3 或 5x5),通过在输入数据上滑动(移动窗口),计算局部区域的加权和,生成特征图(feature map)。
这些卷积核在整个输入数据上共享参数,这使得卷积层能够有效提取局部模式(如边缘、角点和纹理),并且参数数量较少。
 图片
图片
工作原理
卷积操作的工作过程如下。
- 卷积核从输入图像的左上角开始,对输入图像的局部区域进行加权求和。
- 卷积核以步长(stride)的形式滑动,通过滑动窗口逐一计算每个局部区域的加权和,生成一个新的输出特征图。
- 每个卷积核负责提取不同的特征,一个卷积层通常有多个卷积核,生成多个不同的特征图。

超参数
- 卷积核大小:卷积核的大小决定了感受野的大小,常见的尺寸为 3x3 或 5x5。
- 步长(Stride):步长决定了卷积核在输入数据上移动的步幅,步长越大,输出特征图的尺寸越小。
- 填充(Padding):为了保持输出特征图的大小,通常在输入图像边界处填充0。这可以控制输出的尺寸,并避免输入尺寸缩小过快。
如下图所示,对于大小为 7x7x3 的输入,应用两个卷积核,步长(Stride)为1并且使用了填充。
 图片
图片
3.非线性激活层
卷积层提取了局部特征,但卷积本质上是线性运算。为了增强模型的表达能力,CNN 在每个卷积层后通常会加入非线性激活函数,允许模型学习和表示更复杂的特征。
常用的激活函数包括 ReLU、Sigmoid 和 Tanh,其中 ReLU 是最常见的激活函数。
ReLU 的公式为:
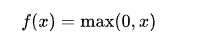
它的作用是将所有负值置为 0,而正值保持不变。这种简单的非线性函数在实践中表现出良好的收敛性,且能够缓解梯度消失问题。
4.池化层
池化层(也称为下采样层)用于对卷积层的输出特征图进行降采样,从而减少特征图的大小,降低计算量和参数量。同时池化层保留了最重要的特征,提高模型对平移、缩放等变换的鲁棒性。
常见的池化方法有最大池化和平均池化。
- 最大池化(Max Pooling)
最常用的池化方法。在局部区域内取最大值作为该区域的输出。
例如,对于一个 2x2 的局部区域,最大池化会输出这四个值中的最大值。 - 平均池化(Average Pooling)
在局部区域内取平均值作为输出。
 图片
图片
5.全连接层
全连接层与传统的神经网络层相似,所有输入节点与输出节点之间是全连接的。
全连接层位于卷积层和池化层之后,通常用于将提取到的高维特征映射到分类空间。
例如,经过多次卷积和池化操作后,特征图被展平(Flatten)为一维向量,传递给全连接层进行分类或回归任务。
 图片
图片
6.输出层
输出层是网络的最后一层,根据任务的不同,输出层的设计也会有所不同。
在分类任务中,输出层通常使用 Softmax 激活函数,它将全连接层的输出转换为每个类别的概率分布。
Softmax 的输出值在 0 到 1 之间,并且所有类别的概率和为 1。
案例分享
以下是一个使用 PyTorch 实现的卷积神经网络进行 Fashion-MNIST 数据集分类的示例代码。
Fashion-MNIST 是一个图像分类数据集,包含 10 个类别的时尚物品图片,每张图片是 28x28 的灰度图像。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
# 定义卷积神经网络模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 第一层卷积,输入1通道(灰度图像),输出32通道,卷积核大小3x3
self.conv1 = nn.Conv2d(1, 32, 3, 1)
# 第二层卷积,输入32通道,输出64通道,卷积核大小3x3
self.conv2 = nn.Conv2d(32, 64, 3, 1)
# 池化层,窗口大小2x2
self.pool = nn.MaxPool2d(2)
# 全连接层,将池化后的特征展平后,输入为64*12*12,输出为128
self.fc1 = nn.Linear(64 * 12 * 12, 128)
# 全连接层,输出10个类别
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.pool(x)
x = x.view(-1, 64 * 12 * 12)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载 Fashion-MNIST 数据集
train_dataset = datasets.FashionMNIST('.', train=True, download=True, transform=transform)
test_dataset = datasets.FashionMNIST('.', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}]\tLoss: {loss.item():.6f}')
# 测试函数
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
# 训练模型
epochs = 10
for epoch in range(1, epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)




























