译者 | 朱先忠
审校 | 重楼
简介
强化学习(RL)是机器学习的一个分支,围绕通过标量信号(奖励)的指导进行学习;这与监督学习是不同的,监督学习需要目标变量的完整标签。
我们可以通过一个直观的例子来解释强化学习。比如一所学校有两个班,连续重复两种类型的测试。第一个班完成了测试并获得了完整的正确答案(监督学习:SL)。第二个班也完成了测试,但是只得到每个问题的分数(强化学习:RL)。在第一种情况下,学生似乎更容易学习正确的答案并记住它们。在第二个班上,任务更难,因为他们只能通过反复试验来学习。然而,他们的学习将更加稳健,因为他们不仅知道什么是正确的,而且知道要避免的所有错误答案。
为了有效地使用RL进行学习,应该设计一个准确的奖励信号(成绩),这被认为是一项艰巨的任务,特别是对于现实世界的应用程序而言。例如,人类专家级的司机知道如何驾驶,但不能为“正确驾驶”技能设定奖励机制,而烹饪或绘画等领域也是如此。这就产生了对模仿学习方法(IL:imitation learning)的需求。IL是RL的一个新分支,它只关注从专家轨迹中学习,而不知道回报。当前,IL的主要应用领域是机器人和自动驾驶领域。
在下文中,我们将探讨本文参考文献中提出的一些最著名的IL方法,按其提出时间从旧到新进行排序,如下图所示。
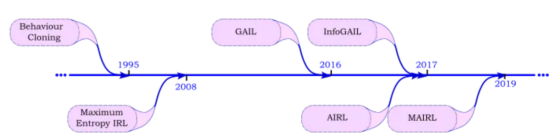
IL方法发明的时间顺序表
注意,下文中数学公式将与符号的命名一起显示。而且,这里给出的理论推导仅保持在最低限度。因此,如果您还需要更深入的了解,可以在末尾的参考文献部分查找原始参考文献。在本文随附的Github仓库中也提供了重新创建本文介绍方法的所有有关实验的完整代码。
接下来,让我们开始深入学习模仿学习,从行为克隆(BC)到信息最大化生成对抗模仿学习(InfoGAIL)。
试验环境
本文中使用的试验环境表示为一个15x15大小的网格。具体的环境状态定义如下图所示:
- 智能体:红色
- 初始智能体位置:蓝色
- 墙壁:绿色
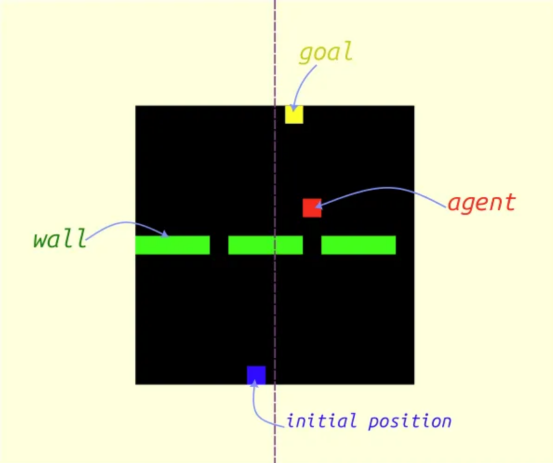
智能体的目标是通过三个窗口中的任何一个,以最短的方式到达第一行,并朝向相对于穿过网格中间的垂直轴的初始位置的对称位置。目标位置不会显示在状态网格中。
因此,初始位置只有15种可能性,目标位置也会因此而改变。
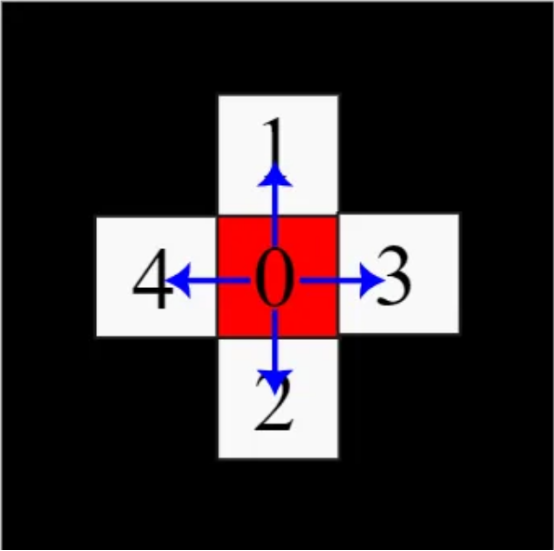
动作空间
动作空间A由0到4的离散数组成,表示四个方向的运动和停止动作,如下图所示:
奖励函数
这里的真实数据奖励R(s,a)是一个描述当前状态和动作的函数,其值等于朝向目标的位移距离:
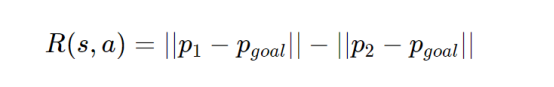
在上面公式中,p1表示旧位置,p2表示新位置。智能体将始终在最后一行初始化,但每次都在随机位置。
专家策略
用于本文中所介绍的所有方法(InfoGAIL除外)的专家策略都是为了以最短的路径实现目标。这涉及三个步骤:
- 向最近的窗口移动
- 直接朝着目标前进
- 在目标位置停止运动
此行为可由下面GIF动画来演示:

使用专家策略生成其他IL方法使用的演示轨迹(每个轨迹τ都表示为状态动作元组的有序序列)
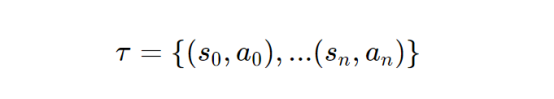
其中,专家演示集定义为D={τ0,⋯,τn}
对于每30个情节——每个情节用32步,专家级平均情节回报率为16.33±6。
正向强化学习
首先,我们将使用真实奖励值来训练一个模型,以便设置一些基准参数和调整超参数,方便后面与IL方法一起使用。
本文中使用的正向强化学习算法的实现基于Clean RL脚本(参考文献12),该脚本提供了强化方法的详细实现细节。
简介
我们将分别测试近端策略优化(PPO)(参考文献2)和深度Q网络(DQN)(参考文献1),这两种方法是目前为止最先进的同策略强化方法和众所周知的异策略强化方法。
以下介绍每种方法的训练步骤及其特征归纳。
同策略——近端策略优化(PPO)算法
此方法使用正在训练的当前策略,并在收集每个episode(情景)的推出后更新其参数。PPO算法有两个主要部分组成:评论家和演员。其中,演员代表策略,而评论家则为每个状态提供价值估计,并为其更新目标。
异策略——深度Q网络(DQN)算法
DQN算法通过使用epsilon贪婪探索在重放缓冲区中收集卷展(rollouts)来离线训练其策略。这意味着,DQN算法并不总是根据每个状态的当前策略采取最佳动作,而是选择随机动作,这使得探索不同的解决方案成为可能。在这种算法中,可以把一个额外的目标网络与更新频率较低的策略版本一起使用,以便使学习目标更加稳定。
试验结果和讨论
下图显示了上述两种方法的情景回报曲线。其中,DQN方法使用黑色显示,而PPO方法显示为橙色线。
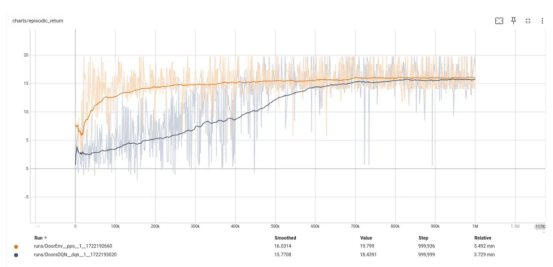
对于这个简单的例子:
- PPO和DQN都收敛,但PPO略有优势。这两种方法都没有达到16.6的专家级水平(PPO方法接近15.26)。
- DQN在相互步骤方面似乎收敛较慢;与PPO相比,这被称为样本低效。
- PPO需要更长的训练时间,这可能是由于演员-评论家训练对两个目标不同的网络进行更新的缘故。
两种方法的训练参数基本相同。如果您想更仔细地了解这些曲线是如何生成的,请查看本文附带存储库中的脚本文件ppo.py和dqn.py。
行为克隆(BC)
行为克隆首次在参考文献4中提出,是一种直接的模仿学习方法。这种方法中应用了监督学习技术,将每个状态映射到基于专家演示的动作D。这种方法将目标定义为:
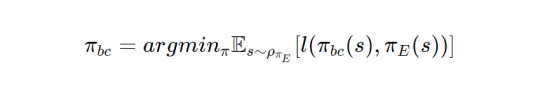
其中,πbc代表训练好的策略,πE代表专家策略,l(πbc(s),πE(s))表示专家和训练过的策略在响应相同状态时的损失函数。
BC和监督学习之间的区别在于将问题定义为一个交互式环境;在这个环境中,BC根据动态的状态(例如,机器人朝着目标移动)采取动作。相比之下,监督学习则是将输入映射到输出,如对图像进行分类或预测温度。这种区别在参考文献8中有所解释。
在此实现中,智能体的所有初始位置仅包含15种可能性。因此,只有15条轨迹可以学习,BC网络可以有效地记忆这些轨迹。为了使问题更难解决,我们将训练数据集D的大小减半(480个“状态-动作”对中只使用了240个),并对本文中后续的所有模仿学习方法都采取这种处理办法。
训练结果
在完成模型训练后(如bc.py脚本所示),我们得到的平均情景回报率为11.49,标准差为5.24。
这比以前的正向强化方法要少得多。以下GIF动画显示了训练好的BC模型的实际应用情况。

从此GIF中可以明显看出,近三分之二的轨迹已经学会了穿过墙壁。然而,该模型陷入了最后三分之一的困境,因为它无法从前面的例子中推断出真正的策略,特别是因为它只得到了15个专家轨迹中的一半来学习。
最大熵逆强化学习(MaxENT)
除了行为克隆(BC)方法之外,MaxEnt(参考文献3)是另一种单独训练奖励模型的方法(不是迭代)。其主要思想在于基于当前的奖励函数,对专家轨迹的概率进行最大化计算。这可以表示为:
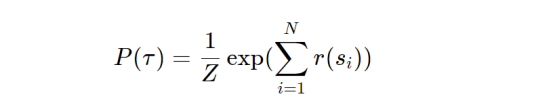
其中,N表示轨迹长度,Z表示给定策略下所有可能轨迹之和的归一化常数。
该方法基于最大熵定理(参考文献3)推断其主要目标;该定理指出,满足给定条件的最具代表性的策略就是具有最高熵H的策略。因此,MaxEnt需要使用一个额外的目标来最大化策略的熵。这就又产生了下面这样一个公式:
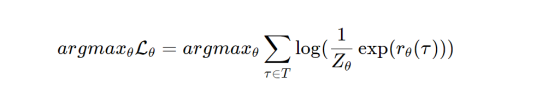
此公式中使用了导数:
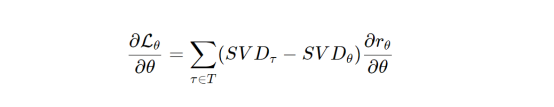
其中,SVD表示状态访问频率;在给定当前策略的情况下,可以用动态规划算法来计算这个值。
在MaxEnt方法的实现中,我们没有使用新奖励的训练,因为动态编程算法会很慢很长。相反,我们选择通过像前一个过程一样重新训练BC模型来测试最大化熵的主要思想,但在损失中增加了推断动作分布的负熵项。熵应该是负的,因为我们希望通过最小化损失来最大化它。
训练结果
在将权重为0.5的动作分布的负熵相加后(选择正确的值很重要;否则,可能会导致学习效果变差),我们看到比之前的BC模型的性能略有改善,现在的平均情景回报率为11.56(+0.07)。之所以训练结果略有改进是因为我们使用了简单的环境,此环境包含的状态数量实在有限。如果状态空间变大一些的话,熵的重要性预计会更大。
生成对抗模仿学习(GAIL)
生成对抗模仿学习(GAIL)的最初工作(参考文献5)受到了生成对抗网络(GANs)概念的启发,GANs应用对抗训练的思想来增强主模型的生成能力。同样,在GAIL中,该概念被应用于匹配训练策略和专家策略之间的状态动作分布。
这可以推导为Kullback-Leibler散度,如论文(参考文献5)所示。这篇论文最终得出这两种模型(在GAIL中称为生成器和鉴别器模型)的主要目标为:
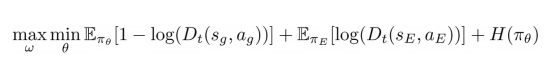
其中,Dt代表鉴别器,πθ代表生成器模型(即训练中的策略),πe代表专家策略,H(πθ)代表生成器模型的熵。
这里,鉴别器充当二进制分类器,而生成器则对应于正在训练的实际策略模型。
GAIL的主要优势
与以前的几种方法相比,GAIL方法的主要好处(以及它表现更好的原因)在于它的交互式训练过程。训练好的策略在鉴别器的奖励信号的指导下学习和探索不同的状态。
训练结果
在对GAIL模型训练160万步后,该模型收敛到比BC和MaxEnt模型更高的水平。如果继续训练的话,可以取得更好的成绩。
具体来说,训练中我们获得了平均12.8的情节奖励,考虑到只有50%的演示没有任何真正的奖励,这是值得注意的一点。
下图显示了GAIL的训练曲线(y轴上标有真实情景奖励值)。值得注意的是,由于GAIL的对抗性训练性质,来自log(D(s,a))的奖励计算结果可能会比真实奖励值更混一些。
对抗反向强化学习(AIRL)
GAIL的一个遗留问题是,训练好的奖励模型(鉴别器)实际上并不代表实际奖励值。相反,鉴别器被训练为专家和生成器状态动作对之间的二元分类器,其平均值为0.5。这意味着,鉴别器只能被视为替代奖励。
为了解决这个问题,参考文献6中的论文使用以下公式重新表述了鉴别器:
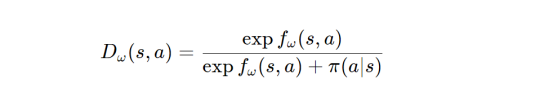
其中,fω(s,a)应收敛到实际优势函数。在这个例子中,这个值表示智能体离不可见目标有多近。注意,通过添加另一个术语以便包含已经成形的奖励值的方法,有助于找到真实奖励值;然而,对于这个实验,我们将仅限于上述优势函数。
训练结果
使用与GAIL相同的参数训练AIRL模型后,我们得到了以下训练曲线:
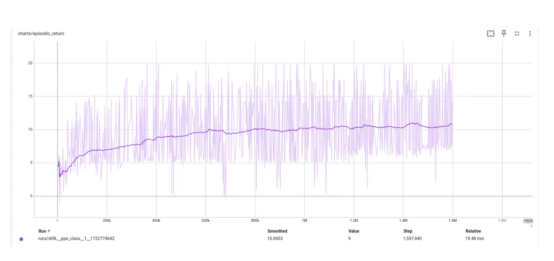
值得注意的是,在相同的训练步骤(160万步)下,由于训练鉴别器的复杂性增加,AIRL的收敛速度较慢。然而,现在我们有了一个有意义的优势函数,尽管只有10.8的情节奖励,但训练结果仍然还是相当不错的。
让我们比较一下这个优势函数和真实奖励值,以便与专家演示结果对应。为了使这些值更具可比性,我们还对学习到的优势函数fω的值进行了归一化。由此,我们得到了下图:
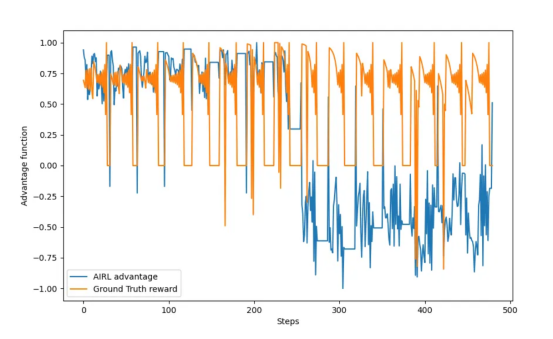
在该图中,有15个脉冲对应于智能体的15个初始状态。在图的后半部分,我们可以看到训练模型中存在更大的误差,这是由于在训练中只使用了一半的专家演示。
在图形的前半部分,我们观察到当智能体在目标处静止且奖励为零时的低状态,而在训练模型中计算结果表示为高值。在图形的后半部分,计算结果表示为较低的值。
总体来看,学习函数大致遵循了真实奖励值规律,并使用AIRL恢复了有关它的有用信息。
信息最大化GAIL(InfoGAIL)
尽管前面的几种方法取得了一些进步,但是模仿学习中仍然存在一个重要问题:多模态学习。为了将IL应用于实际问题,有必要学习多种可能的专家策略。例如,在开车或踢足球时,没有一种“真正”的做事方式;专家们的方法各不相同,IL模型应该能够始终如一地学习这些变化。
为了解决这个问题,人们又开发了InfoGAIL模型算法(参考文献7)。受InfoGAN(参考文献11)的启发,InfoGAN使用额外的风格向量来调节GAN生成的输出风格,InfoGAIL在GAIL目标的基础上增加了另一个标准:对状态-动作对和新的控制输入向量z之间的互信息进行最大化处理。这个目标可以推导成如下形式:
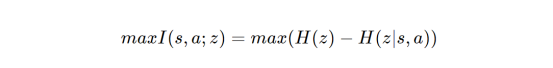
Kullback-Leibler散度
其中,估计后验p(z∣s,a)用一个新的模型Q近似,该模型以(s,a)为输入,输出z。
InfoGAIL的最终目标函数可以表示成如下形式:
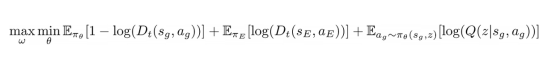
结果是,策略中包含了一个额外的输入,即z,如下图所示:
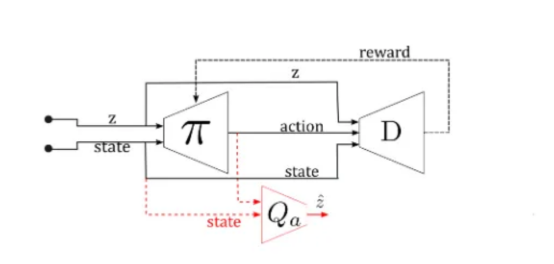
在我们的实验中,我们生成了新的多模态专家演示,每个专家只能从一个缺口(墙上的三个缺口中的一个)进入,而不管他们的目标是什么。实验中,我们使用了完整的演示集,但是没有标注是哪位专家在做动作。z变量是一个单热编码向量,表示成一个具有三个元素的专家类(例如,左门为[1 0 0])。此时,策略应该是:
- 学会朝着目标前进。
- 将随机生成的z值链接到不同模式的专家(从而通过不同的门)。
- Q模型应该能够根据每个状态下的动作方向来检测它是哪种模式。
请注意,由于对抗性训练,鉴别器、Q模型和策略模型训练结果图都表现得有些混乱。
幸运的是,我们清楚地学习了这两种模式。无论是通过策略方法还是Q模型方法都没有识别出第三种模式。以下三个GIF动画显示了在给定不同z值时从InfoGAIL学习到的专家模式情况:

z=[1,0,0]

z=[0,1,0]

z=[0,0,1]
最终,上述策略能够收敛到经过80万个训练步后大约结果为10的情节奖励。通过增加更多的训练步骤的话,应该能够获得更好的训练结果,即使本例中使用的专家方案不是最佳的。
归纳
当回顾我们上面做过的所有实验时,结论很明显,所有模仿学习方法在情景奖励标准方面都表现良好。下表总结了它们各自的表现成绩:
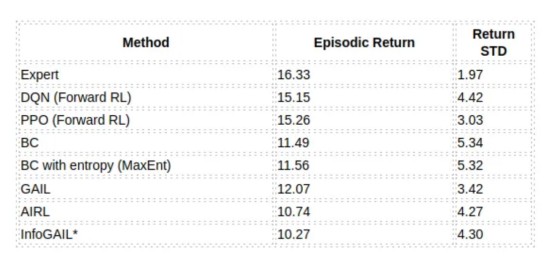
因为专家演示是基于多模态专家的,所以InfoGAIL的结果不具有可比性
该表显示,GAIL在我们给定的问题上表现最佳,而AIRL由于其引入了新的奖励公式而表现得速度较慢,导致回报率较低。另外,InfoGAIL也学得很好,但很难识别所有三种专家模式。
结论
总之,模仿学习成为当下一个具有挑战性和吸引力的领域。我们在本文中探索的方法适用于网格模拟环境,但可能无法直接转化为现实世界的应用程序。除了一些行为克隆方法外,模仿学习的实际应用仍处于起步阶段。将模拟与现实联系起来会因其性质的差异而引入新的错误。
模仿学习的另一个公开挑战是多智能体模仿学习。MAIRL(参考文献9)和MAGAIL(参考文献10)等人已经对多智能体环境进行了研究实验,但从多个专家轨迹中学习的一般理论目前仍然是一个悬而未决的问题。
最后,我在GitHub上提供的存储库(http://github.com/engyasin/ilsurvey)提供了实现本文中介绍的所有方法的基本代码实现,可以进行轻松扩展。该代码将会在未来进行更新。如果您有兴趣做出相关贡献的话,您可以提交一个问题或拉取请求,并附上您的修改结果。
【注】除非另有说明;否则,本文中所有图片均由作者本人自己提供。
参考文献
[1] Mnih, V. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
[2] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
[3] Ziebart, B. D., Maas, A. L., Bagnell, J. A., & Dey, A. K. (2008, July). Maximum entropy inverse reinforcement learning. In Aaai (Vol. 8, pp. 1433–1438).
[4] Bain, M., & Sammut, C. (1995, July). A Framework for Behavioural Cloning. In Machine Intelligence 15 (pp. 103–129).
[5] Ho, J., & Ermon, S. (2016). Generative adversarial imitation learning. Advances in neural information processing systems, 29.
[6] Fu, J., Luo, K., & Levine, S. (2017). Learning robust rewards with adversarial inverse reinforcement learning. arXiv preprint arXiv:1710.11248.
[7] Li, Y., Song, J., & Ermon, S. (2017). Infogail: Interpretable imitation learning from visual demonstrations. Advances in neural information processing systems, 30.
[8] Osa, T., Pajarinen, J., Neumann, G., Bagnell, J. A., Abbeel, P., & Peters, J. (2018). An algorithmic perspective on imitation learning. Foundations and Trends® in Robotics, 7(1–2), 1–179.
[9] Yu, L., Song, J., & Ermon, S. (2019, May). Multi-agent adversarial inverse reinforcement learning. In International Conference on Machine Learning (pp. 7194–7201). PMLR.
[10] Song, J., Ren, H., Sadigh, D., & Ermon, S. (2018). Multi-agent generative adversarial imitation learning. Advances in neural information processing systems, 31.
[11] Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Advances in neural information processing systems, 29.
[12] Huang, S., Dossa, R. F. J., Ye, C., Braga, J., Chakraborty, D., Mehta, K., & AraÚjo, J. G. (2022). Cleanrl: High-quality single-file implementations of deep reinforcement learning algorithms. Journal of Machine Learning Research, 23(274), 1–18.
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Hands-On Imitation Learning: From Behavior Cloning to Multi-Modal Imitation Learning,作者:Yasin Yousif