Sutton 等研究人员近期在《Nature》上发表的研究《Loss of Plasticity in Deep Continual Learning》揭示了一个重要发现:在持续学习环境中,标准深度学习方法的表现竟不及浅层网络。研究指出,这一现象的主要原因是 "可塑性损失"(Plasticity Loss):深度神经网络在面对非平稳的训练目标持续更新时,会逐渐丧失从新数据中学习的能力。
深度强化学习任务中的神经网络实际上面临着更为严峻的可塑性损失问题。这源于强化学习智能体必须通过与环境的持续互动来不断调整其策略,使得非平稳的数据流和优化目标成为深度强化学习范式中的固有特征。值得注意的是,即使在单任务强化学习中,在线数据收集和策略更新也会导致数据分布和优化目标持续动态变化。因此,严重的可塑性损失已然成为制约深度强化学习算法样本利用效率的关键瓶颈。
要突破视觉强化学习样本利用效率低下这一瓶颈,关键在于深入解构深度强化学习中神经网络可塑性损失的细节,从而明确问题的根源。针对这一挑战,来自清华大学、悉尼大学、华盛顿大学、京东探索研究院和南洋理工大学的研究人员展开了一项全面而深入的研究。他们选取视觉强化学习任务作为深度强化学习的典型代表,创新性地从数据、模块和训练阶段三个关键角度对神经网络的可塑性损失特征进行分析。

- 论文链接:https://arxiv.org/abs/2310.07418
- 代码链接:https://github.com/Guozheng-Ma/Adaptive-Replay-Ratio
这项研究不仅解释了视觉强化学习中一些此前难以理解的反常现象,还揭示了一系列与直觉相悖的有趣结论。该研究成果已在 ICLR 2024 上发表,本文将对其中一系列引人深思的发现进行进一步梳理和总结。其中最核心的要点可概括如下:
1. 揭示了数据增强的作用机制:简单的数据增强能够显著提升视觉强化学习的样本利用效率,其效果令人瞩目。在自动驾驶任务 CARLA 中,引入数据增强将性能提高至基准的 235%。更令人惊讶的是,在 DeepMind Control suite 的 9 种机器人控制任务中,数据增强平均将性能提升至基准的 431%。然而,尽管这些惊人的效果早已被观察到,但数据增强为何能带来如此显著的性能提升一直是一个未解之谜。该研究的突破性发现揭示了视觉强化学习中数据增强背后的作用机制:它能直接有效地缓解训练过程中的可塑性损失。
2. 明确了样本利用效率的关键瓶颈:过去多年,学界普遍认为导致视觉强化学习样本利用效率低下的主要瓶颈在于训练视觉表征器的难度。然而,这项研究通过一系列巧妙的实验,颠覆了这一长期以来的观点。研究结果表明,目前限制视觉强化学习样本利用效率的关键因素并非编码器(Encoder)的视觉表征能力,而是评价者网络(Critic)的可塑性损失。
3. 突出了训练早期干预的重要性:可塑性损失指的是模型的学习能力随着训练不断减弱的现象。然而,不同训练阶段对于避免灾难性可塑性损失的作用是否有所不同,这一问题此前一直未被深入探索。该研究填补了这一空白,揭示了一个关键发现:训练早期对 Critic 网络可塑性的干预极为重要:若未能在训练早期及时将网络可塑性恢复到高水平,将会导致训练后期难以逆转的灾难性可塑性损失。
从视觉强化学习中的数据增强开始

数据增强已成为实现高样本利用效率的视觉强化学习算法中不可或缺的组件。与监督学习中数据增强仅带来渐进式改进不同,在多种视觉强化学习任务中,数据增强对算法效果起到了决定性作用。如上图所示,在不使用数据增强的情况下,算法几乎无法训练出有效的策略。相反,仅仅引入对输入观察图像的简单数据增强,就能在不修改算法其他部分的前提下,实现一个具有高渐进效果和样本效率的视觉强化学习算法。
这种显著的提升显然无法用传统视觉任务中数据增强的作用机理来解释。更可能的是,数据增强有效缓解或解决了强化学习中的一个关键瓶颈。在没有数据增强的情况下,智能体的性能在短暂上升后几乎停滞,这一现象与智能体遭受可塑性损失,无法从新收集的数据中学习的后果非常吻合。基于这一观察,该研究设计了巧妙的实验,旨在验证数据增强的背后作用机制是否确实在于有效缓解了灾难性的可塑性损失。
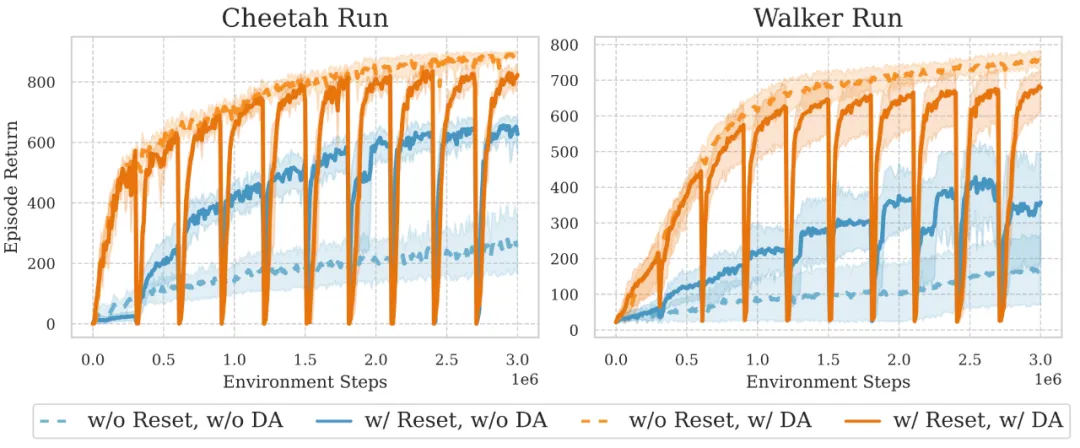
Reset 是一种简单而直接的方法,通过周期性地重新初始化智能体网络最后几层全连接层来恢复神经网络的可塑性。在这项研究中,研究人员巧妙地将 Reset 作为一种诊断工具,用来判断使用与不使用数据增强时网络的可塑性损失情况。实验结果揭示了以下关键发现:
- 在不使用数据增强的情况下,实施 Reset 均能够带来显著的性能提升。这明确地表明,在缺乏数据增强的训练过程中,网络确实经历了严重的可塑性损失。
- 但当引入数据增强后,Reset 的实施只带来轻微的改善,有时甚至会导致性能下降。这一结果表明,只通过数据增强就能有效提升智能体的可塑性。
这一巧妙的实验证明数据增强能够非常显著地缓解视觉强化学习训练过程中的可塑性损失,从而解释了为什么数据增强对于提高样本利用效率如此关键。通过有效维持神经网络的可塑性,数据增强实际上延长了神经网络的有效学习期,使其能够更充分地利用每一个训练样本。

研究还对比了数据增强和其他先前提出的用来缓解可塑性损失的方法。实验结果再次证明,作为一种从数据角度出发(data-centric)的方法,数据增强在缓解可塑性损失方面展现出卓越的效果,相对于目前已有的其他方案具有明显优势。
解构视觉强化学习不同模块中可塑性损失的不同影响

相较于基于状态向量的强化学习任务,视觉强化学习一直面临着样本利用效率严重低下的困扰。近年来,缩小基于图像和基于状态向量的强化学习在样本利用效率上的差距已成为整个视觉强化学习社区关注的重点。这两种学习范式的关键区别在于:视觉强化学习需要在进行策略优化的同时进行表征学习。基于这一认识,大量研究致力于通过改进视觉表征学习来提升视觉强化学习的样本利用效率。常见的方法包括添加额外的辅助表征任务,或使用预训练的视觉编码器(Encoder)。但是,高维视觉表征真的是影响视觉强化学习样本利用效率的关键瓶颈吗?

该研究通过一个巧妙的实验回答了这个问题。研究者采用了 PIE-G 提出的预训练编码器方案,并测试了数据增强对训练过程的影响。这个实验设计有两个关键点:
- 使用在 ImageNet 上预训练的编码器,确保了足够的视觉表征能力。
- 在整个训练过程中保持编码器不变,排除了数据增强对编码器的直接影响。
研究假设:如果表征学习是当前限制样本利用效率的关键,或者可塑性损失主要发生在编码器,那么数据增强的使用与否不应显著影响算法的训练过程。

然而,实验结果令人惊讶:
- 数据增强对基于预训练编码器的视觉强化学习的样本利用效率产生了显著影响。
- 在不使用数据增强的情况下,即使是简单的 Walker Walk 任务,智能体的性能在训练后期也明显停滞,表现出严重的可塑性损失。
这一发现具有重要意义:即使有了良好的视觉表征,视觉强化学习仍然存在严重的可塑性损失。这表明对于当前的视觉强化学习算法,高维视觉的表征已经不构成影响样本利用效率的关键瓶颈。更为关键的是,该实验证明了严重的可塑性损失并非发生在编码器模块,而应该是存在于 Actor 或 Critic 中。
研究者进一步使用可塑性注入(Plasticity Injection)作为可靠的诊断工具来最终判定灾难性的可塑性损失究竟发生在 Actor 还是 Critic 中。不同于 Reset,可塑性注入在恢复网络可塑性的同时不会破坏网络现有知识,因此不会出现明显的性能波动。这使得可塑性注入更适合用来作为判断特定网络模块是否发生灾难性可塑性损失的诊断工具。

实验结果揭示了两个关键发现:
- 在使用数据增强的情况下,对 Actor 或者 Critic 实施可塑性注入都不会明显影响智能体的训练过程。这表明在 Walker Run 任务中,仅仅通过使用数据增强就足以维持训练所需的网络可塑性。
- 在初始 100 万步训练中不使用数据增强的情况下,对 Critic 实施可塑性注入会导致性能显著提升。相反,对 Actor 进行可塑性注入也并不能使智能体恢复正常训练。这一结果充分证明,Critic 严重的可塑性损失是造成视觉强化学习样本利用效率严重低下的关键原因。

分析视觉强化学习不同训练阶段中可塑性损失的不同性质

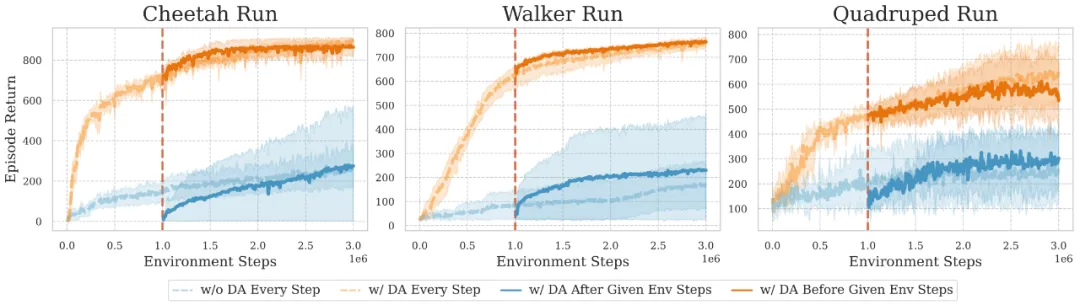
最后,该研究设计了一个巧妙的实验,通过在训练过程中的不同时间点开启或关闭数据增强,来探究数据增强在不同训练阶段对解决可塑性损失的影响。具体来说,他们在训练进行到三分之一时改变数据增强的使用状态,观察其对训练效果的影响。这个实验揭示了两个重要发现:
- 在 Critic 的可塑性已经恢复后停止使用数据增强,并不会明显影响训练效率。这表明在训练的后期,不需要采取特定干预来维持可塑性。
- 当可塑性已经显著丧失,且未能在早期阶段及时干预的情况下,后期引入数据增强也无法使智能体恢复正常的训练。这一观察强调了在训练早期维持可塑性的至关重要性,否则,这种损失将变得无法挽回。
这一实验不仅证实了数据增强在训练早期阶段的关键作用,更重要的是,它揭示了可塑性损失的不可逆特性。实验结果表明,如果在训练早期没有通过有效干预(如数据增强)使 Critic 网络的可塑性恢复到较高水平,就会导致不可逆的灾难性可塑性损失。

在训练的初始阶段,由于收集到的经验数据质量低且数量有限,通过自举学习所得出的训练目标(Target Q Value)表现出高度的非平稳性,并显著偏离真实的 Q 值。这种严重的非平稳性导致 Critic 的可塑性迅速下降,使其失去从新收集数据中继续优化策略的能力。随之,智能体持续收集低质量的数据,形成了一个恶性循环。这一连锁反应最终阻碍了智能体获得有效策略,导致训练早期阶段出现灾难性的可塑性损失。
然而,训练过程的后期呈现出不同的特征:尽管 Critic 的可塑性在训练早期恢复到高水平后仍然会缓慢下降,但这种下降可以被理解为逐步逼近当前任务最优值函数的过程。对于不需要智能体保持持续学习能力的单任务视觉强化学习而言,这种后期的可塑性损失被视为良性的。
这种在训练不同阶段所观察到的可塑性变化差异,为解决视觉强化学习中的可塑性损失挑战提供了新的视角,暗示了针对训练不同阶段采取差异化策略的可能性。
基于对视觉强化学习中可塑性损失的深入分析,该研究最终提出了一种创新的训练方法 —— 自适应回放比例。这种方法巧妙地根据 Critic 网络的可塑性水平动态调整回放比例(Replay Ratio),成功破解了视觉强化学习算法难以使用高回放比例的长期困境。对该方法的技术细节感兴趣的读者,可以前往论文原文深入了解。