前言
大家好,我是田螺。
分享一道大厂面试真题:说说redis主从的脑裂?
我们可以按照这几个维度来回答:
- 什么是脑裂行为
- 主从集群中为什么会发生脑裂?
- 脑裂为什么又会导致数据丢失呢?
- 我们该如何避免和应对脑裂的发生呢?
1. 什么是脑裂
什么是脑裂行为?
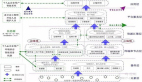
- 脑裂(Split-Brain)是指在分布式系统中,网络分区导致多个节点之间失去联系,形成了两个或多个独立的“脑”,每个脑都认为自己是主节点,导致数据写入的冲突和不一致。
 图片
图片
- 在 Redis 的主从架构中,如果主节点和从节点因网络故障或其他原因失去联系,哨兵开始选举了新的主节点,而旧的主节点恢复过来继续接受写请求,也就是存在两个redis主节点了,这就是redis的脑裂行为。
2. 主从集群中为什么会发生脑裂?
脑裂行为在Redis主从集群中可能发生的原因,主要包括以下几点:
 图片
图片
- 网络故障:在网络故障或不稳定的情况下,主节点与哨兵或从节点之间的通信可能会中断。这时,哨兵可能会误认为主节点已宕机。
- 哨兵的选举机制:当哨兵无法与主节点通信时,会启动选举过程,从现有的从节点中选出一个新的主节点。如果此时网络恢复,主节点仍在运行,就会导致出现两个主节点。
- 假故障: 哨兵的故障转移策略在网络异常时会过于敏感,容易在错误的情况下进行主节点的选举。也就是因为假故障导致又多选一个主节点出来。
3. 脑裂为什么又会导致数据丢失呢?
Redis的主从切换后,一旦从库被提升为新的主库,哨兵会指示原主库去执行主从复制命令,以便与新主库进行全量同步数据。最后在全量同步的阶段的话,原主库需要清除本地数据,加载来自新主库的RDB文件(我们知道,redis主从同步是基于rdb文件的)。这就会导致在主从切换期间,原主库接收的新写数据会丢失啦。
还是上个简单的图,方便大家理解吧:
 图片
图片
上图,大家可以发现:
- 当旧的主库因为假死(假故障) 的原因,导致哨兵开始选举新的主库。在选举新主库期间,旧的主库莫名奇妙又好了,它可以继续接受写入的请求了。
- 然后新主库选好了,就有两个主库在同时处理写请求啦。等到新主库选好之后,旧的主库就变成从库了,它需要从新的主库那里同步数据过来,这样一来,在切换期间,旧主库保存的数据就丢失啦。
4. 我们该如何避免/应对脑裂的发生呢?
为了避免脑裂的发生,我们尝试这些方法:
 图片
图片
- 使用 Quorum 配置:确保哨兵数量为奇数,并设定适当的投票规则,以减少误判的可能性。
- 合理设置超时参数:调整哨兵的 down-after-milliseconds 和 failover-timeout 参数,以适应实际网络环境,减少误判。
- 网络隔离与监控:确保网络稳定,监控网络状态和延迟,以便在问题出现时及时处理。
- 引入代理层:使用代理(如 Codis)来管理客户端与 Redis 的连接,避免直接连接导致的脑裂。
还有个比较推荐的方式,那就是min-slaves-to-write 和 min-slaves-max-lag 这两个参数,可以有效减少 Redis 脑裂的风险
- min-slaves-to-write:该参数设置在执行写操作时,至少需要有多少个从节点在线并且处于同步状态。如果在线的从节点数量低于此值,主节点将拒绝写入请求,从而避免在不一致的情况下进行写操作。
- min-slaves-max-lag:这个参数定义了允许的最大复制延迟(以秒为单位)。如果从节点的复制延迟超过此阈值,主节点将不会考虑这些从节点为有效,从而减少因落后节点引起的数据不一致问题。