












在日常开发中,我们经常会使用到缓存,当数据集较小时,通常将所有缓存数据保存在一台服务器上就足够了,但是当数据集较大时,我们需要将缓存数据分布在多个服务器上,这样就产生了分布式缓存。这篇文章,我们将详细探讨分布式缓存。

一、什么是分布式缓存?
分布式缓存是指分布在多个服务器上的缓存。与本地缓存不同,分布式缓存通常部署在独立的应用进程中,并与应用进程部署在不同的机器上。因此,数据读写操作需要通过网络来完成。分布式缓存的主要特点包括:
- 可扩展性:当应用程序需要处理大量数据或高并发请求时,可以通过增加服务器节点来扩展分布式缓存的容量和提高性能。
- 数据一致性:分布式缓存的数据一致性可以通过各种技术实现,如缓存同步、分布式锁等。
- 独立部署:分布式缓存通常部署在独立的应用进程中,与应用程序分离,多个应用可以直接共享缓存。
分布式缓存会以元数据服务作为服务发现:客户端会把自身监听的IP和端口汇报给元数据服务,也会从元数据服务获取同一个缓存组内的其他成员的连接方式,进而发现其它客户端,并通过节点间通信来共享缓存。

二、分布式缓存的组成部分
一个分布式缓存系统通常包括以下组成部分:
- 缓存节点:这些是存储缓存数据的各个服务器。每个节点都是整体缓存集群的一部分。
- 客户端库/缓存客户端:应用程序使用客户端库与分布式缓存通信。这个库处理连接缓存节点、分布数据和检索缓存数据的逻辑。
- 一致性哈希:这种方法将数据均匀地分布在缓存节点上。它确保添加或删除节点对系统的影响最小。
- 复制:为了使系统更可靠,一些分布式缓存会在多个节点上复制数据。如果一个节点宕机,数据仍然可以在另一个节点上获取。
- 分片:数据被分成分片,每个分片存储在不同的缓存节点上。它有助于均匀分布数据,并允许缓存水平扩展。
- 驱逐策略:缓存实现驱逐策略,如LRU(最近最少使用)、LFU(最少使用频率)或TTL(生存时间),以清除旧的或使用较少的数据,为新数据腾出空间。
- 协调和同步:协调机制,如分布式锁或一致性协议,确保缓存节点保持同步,尤其是在多个节点尝试更改相同数据时。
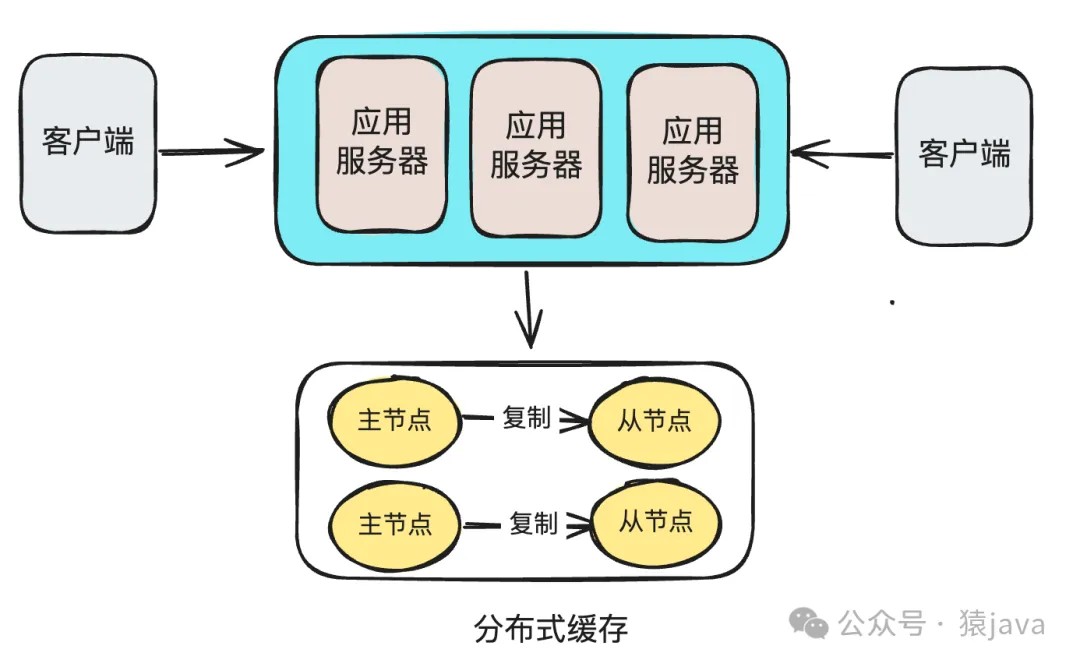
三、分布式缓存如何工作?
(1) 数据分布:当数据被缓存时,客户端库通常会对与数据关联的键进行哈希,以确定哪个缓存节点将存储数据。
(2) 数据复制:为了可靠性,缓存系统会在多个节点上复制缓存数据。因此,如果一个节点(例如A)存储数据,它可能还会被复制到另一个节点(例如B)作为备份。
(3) 数据检索:为了从缓存中获取数据,应用程序提供键给客户端库。客户端库使用这个键找到并查询拥有数据的节点。如果数据存在(缓存命中),它会返回给应用程序。如果没有(缓存未命中),则从主数据存储(例如数据库)获取数据,并可以缓存以备将来使用。
(4) 缓存失效:为了使缓存数据与主数据源保持同步,需要定期使其失效或更新。缓存系统实现了基于时间的失效或基于事件的失效策略。
(5) 缓存驱逐:由于缓存空间有限,需要驱逐策略为新数据腾出空间。常见的驱逐策略包括:
- 最近最少使用(LRU):驱逐最长时间未访问的数据。
- 最少使用频率(LFU):驱逐访问次数最少的数据。
- 生存时间(TTL):驱逐在缓存中超过指定时间的数据。
四、分布式缓存的优缺点
1.优点
高性能:
- 低延迟:缓存数据通常存储在内存中,访问速度远快于从数据库或其他持久化存储中读取数据。
- 减少数据库负载:缓存频繁访问的数据,减少数据库查询次数,从而降低数据库负载,提高系统的整体性能和响应速度。
可扩展性:
- 水平扩展:通过增加或减少缓存节点,可以轻松扩展缓存容量和处理能力,满足不同规模的需求。
- 负载均衡:缓存请求可以分散到不同的节点上,避免单点瓶颈,提高系统的吞吐量。
高可用性:
- 容错能力:缓存数据分布在多个节点上,即使某些节点发生故障,系统仍能继续运行,提供高可用性。
- 数据复制:通过数据复制和自动故障转移机制,确保数据的高可用性和系统的容错能力。
灵活性:
- 多样的数据结构:支持多种数据结构(如键值对、哈希、列表、集合等),方便开发者进行灵活的数据存储和操作。
- 多种缓存策略:支持多种缓存失效策略(如LRU、LFU、FIFO等),可以根据具体需求进行配置。
实时性:
- 实时数据处理:适用于实时数据处理和事件流处理场景,能够快速响应和处理大量实时数据。
2.缺点
数据一致性:
- 一致性挑战:在分布式环境下,保证数据一致性是一个复杂的问题,尤其是在网络分区或节点故障时。需要采用一致性协议(如Paxos、Raft等)来确保数据一致性,这会增加系统的复杂性和开销。
- 缓存同步:在多节点之间同步缓存数据可能会引入延迟和一致性问题,需要仔细设计和管理。
数据持久性:
- 数据丢失风险:缓存数据主要存储在内存中,一旦节点发生故障或重启,内存中的数据可能会丢失。因此,通常需要结合持久化存储来保证数据的可靠性。
运维复杂性:
- 监控和管理:分布式缓存系统需要进行监控和管理,及时发现和解决问题,确保系统的稳定性和高性能。这增加了运维的复杂性。
- 配置和调优:需要根据具体应用场景进行配置和调优,以达到最佳性能和稳定性,这需要一定的专业知识和经验。
网络开销:
- 网络延迟:在分布式环境中,不同节点之间的通信会引入网络延迟,特别是在跨数据中心的场景下,这可能会影响系统的性能。
- 数据传输开销:在节点之间进行数据复制和同步会增加网络流量和传输开销。
成本:
- 硬件成本:需要多个节点来存储和处理缓存数据,这会增加硬件成本和资源消耗。
- 开发成本:需要额外的开发工作来集成和管理分布式缓存系统,增加了开发成本和时间。
五、常见的分布式缓存系统
1.Redis
Redis是一个开源的内存数据存储,支持存储各种数据结构,包括字符串、哈希、列表、集合、有序集合、位图、HyperLogLog和地理空间索引。
它支持数据复制和持久化,使其成为需要数据持久性和容错性的应用程序的流行选择。
使用 Redis作为分布式缓存工具对于一个 Java程序员来说,一定也不陌生!
2.Memcached
Memcached是另一个开源的内存缓存系统,设计用于速度和简洁。它广泛用于缓存小块数据,如数据库查询结果、API调用或页面渲染。
Memcached是一个纯内存缓存,没有持久层。这使得它非常适用于不需要永久存储数据的用例,如缓存数据库查询结果。
3.Ehcache
Ehcache是一种广泛使用的开源Java缓存库,旨在提高应用程序的性能。它支持多种缓存策略和配置,能够缓存数据到内存或磁盘,并能与其他分布式缓存解决方案集成。Ehcache主要用于Java应用中,以减少数据库查询次数、提高数据访问速度和改善整体系统性能。
Ehcache的主要特点如下:
- 简单易用:提供简洁的API和配置方式,易于集成到Java应用中。
- 多级缓存:支持内存缓存和磁盘缓存,可以将不常用的数据移到磁盘,节省内存。
- 缓存策略:支持多种缓存失效策略,如LRU(Least Recently Used)、LFU(Least Frequently Used)和FIFO(First In, First Out)。
- 持久化:可以将缓存数据持久化到磁盘,保证在应用重启后数据仍然可用。
- 分布式缓存:通过与Terracotta等分布式缓存框架集成,支持缓存数据在多个节点之间分布和同步。
- 事务支持:支持缓存事务,确保缓存操作的一致性和原子性。
- 监控和管理:提供丰富的监控和管理功能,可以通过JMX(Java Management Extensions)进行监控和管理。
4.Hazelcast
Hazelcast是一种开源的内存数据网格(In-Memory Data Grid,IMDG)解决方案,旨在提供高性能、分布式的数据存储和计算能力。它将数据分布在多个节点上,并在内存中进行存储和处理,从而实现快速的数据访问和高可用性。Hazelcast适用于各种分布式应用场景,如缓存、会话管理、分布式计算和事件流处理。
Hazelcast的主要特点如下:
- 分布式数据结构:支持多种分布式数据结构,如Map、Queue、Set、List、MultiMap等,方便开发者进行分布式数据存储和操作。
- 高可用性:通过数据复制和自动故障转移机制,确保数据的高可用性和系统的容错能力。
- 可扩展性:可以动态添加或移除节点,实现线性扩展,满足不同规模的需求。
- 内存存储:数据存储在内存中,提供极高的数据访问速度。
- 分布式计算:支持分布式任务执行、MapReduce等计算框架,能够在多个节点上并行处理数据。
- 事件处理:支持事件监听和处理,适用于实时数据处理和事件驱动的应用程序。
- 持久化:提供持久化选项,可以将数据保存到磁盘或数据库中,以确保数据的持久性。
- 集成与兼容性:与多种技术和框架(如Spring、Hibernate、JCache等)集成,方便在现有项目中使用。
六、分布式缓存使用场景
分布式缓存在现代计算系统中有着广泛的应用,特别是在需要高性能、高可用性和可扩展性的场景中。以下是一些常见的分布式缓存使用场景:
1.Web应用加速
分布式缓存可以显著提升Web应用的响应速度,通过缓存频繁访问的数据(如用户信息、产品详情、页面内容等),减少数据库查询次数,从而降低数据库负载,提高系统的吞吐量。
2.会话管理
在分布式系统中,用户会话数据需要在多个服务器之间共享。分布式缓存可以存储会话数据,确保用户无论访问哪个服务器,都能获得一致的会话状态。这对于负载均衡和高可用性尤为重要。
3.配置管理
对于配置数据较多且频繁读取的应用,可以将配置数据存储在分布式缓存中。这样可以减少配置文件的读取次数,提高配置数据的访问速度。
4.数据分析
在大数据分析场景中,分布式缓存可以存储中间计算结果或频繁访问的数据,减少重复计算,提高数据处理效率。例如,在机器学习和数据挖掘任务中,分布式缓存可以加速模型训练和预测过程。
5.实时数据处理
在实时数据处理场景中,如物联网数据处理、金融交易处理、监控和报警系统等,分布式缓存可以存储实时数据和事件流,提供快速的数据读取和写入能力,确保系统的实时性和高性能。
6.分布式计算
在分布式计算框架中(如MapReduce、Spark等),分布式缓存可以用于存储任务的中间结果,减少数据传输和重复计算,提高计算效率。
7.CDN
在CDN(内容分发网络)系统中,分布式缓存用于存储和分发静态内容(如图片、视频、文件等),提高内容分发速度,减少服务器负载。
8.搜索引擎
搜索引擎需要快速响应用户的查询请求,分布式缓存可以存储索引数据和查询结果,加速搜索过程,提高用户体验。
9.购物车
在电商平台中,用户的购物车数据需要在多个服务器之间共享和同步。分布式缓存可以存储购物车数据,确保用户在不同设备和浏览器中看到一致的购物车状态。
10.推荐系统
推荐系统需要快速访问用户行为数据和推荐结果。分布式缓存可以存储用户的历史行为数据和推荐结果,提供快速的推荐服务。
七、总结
分布式缓存是一种数据缓存技术,通过将数据分布在多个节点上,提高系统的性能、可扩展性和高可用性。其主要优点包括低延迟、高性能、水平扩展能力和容错能力,适用于Web应用加速、会话管理、数据分析和实时数据处理等场景。然而,分布式缓存也面临数据一致性挑战、数据持久性问题、运维复杂性和网络开销等缺点。合理使用分布式缓存需要权衡这些优缺点,并进行适当的配置和管理,以满足具体应用的需求。























