













大家好,我是小寒
今天给大家分享神经网络中常用的正则化技术。
神经网络中的正则化技术是用于防止模型过拟合的一系列方法。
过拟合通常发生在模型在训练数据上表现得很好,但在测试数据上表现不佳,这意味着模型在训练过程中学习到了数据中的噪声或细节,而非通用的模式。
神经网络中常用的正则化技术包括
- 早停法
- L1 和 L2 正则化
- Dropout
- 数据增强
- 添加噪声
- Batch Normalization
早停法
早停法是一种简单但非常有效的正则化技术。
模型在训练过程中会定期在验证集上进行评估,如果验证集上的损失开始增大(即验证集的性能变差),则认为模型可能已经过拟合。
早停法会在验证损失不再下降时停止训练,以防止模型继续在训练集上过度拟合。

import tensorflow as tf
# Creating a simple neural network model
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activatinotallow='relu', input_shape=(100,)),
tf.keras.layers.Dense(32, activatinotallow='relu'),
tf.keras.layers.Dense(1, activatinotallow='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Using EarlyStopping callback
early_stopping = tf.keras.callbacks.EarlyStopping(
mnotallow='val_loss', # Monitoring validation loss
patience=5, # Number of epochs with no improvement to wait before stopping
restore_best_weights=True # Restores the weights of the best epoch
)
# Train the model with early stopping
model.fit(X_train, y_train, validation_split=0.2, epochs=100, callbacks=[early_stopping])L1 和 L2 正则化
L1正则化

import tensorflow as tf
from tensorflow.keras import regularizers
# Creating a simple neural network model with L1 regularization
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(100,),
kernel_regularizer=regularizers.l1(0.01)), # L1 Regularization
tf.keras.layers.Dense(32, activation='relu',
kernel_regularizer=regularizers.l1(0.01)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Summary of the model
model.summary()L2正则化
L2 正则化则在损失函数中加入权重平方和作为惩罚项,其公式为
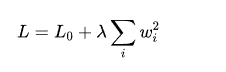
正则化通过惩罚大权重的参数,迫使权重的分布更加均匀,防止模型对训练数据中的特定特征过于敏感。
它不会像L1那样产生稀疏解,但可以有效控制模型的复杂度。
import tensorflow as tf
from tensorflow.keras import regularizers
# Creating a neural network model with L2 regularization
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(100,),
kernel_regularizer=regularizers.l2(0.01)), # L2 Regularization
tf.keras.layers.Dense(32, activation='relu',
kernel_regularizer=regularizers.l2(0.01)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Summary of the model
model.summary()Dropout
Dropout 是一种非常流行的正则化方法,尤其在深度神经网络中。
训练过程中,Dropout 随机地“关闭”一部分神经元及其连接,使得网络在每次训练迭代中只使用部分神经元进行前向传播和反向传播。
Dropout 可以防止神经元之间的共适应性,提高网络的泛化能力。
 图片
图片
import tensorflow as tf
# Creating a neural network model with Dropout
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activatinotallow='relu', input_shape=(100,)),
tf.keras.layers.Dropout(0.5), # 50% Dropout
tf.keras.layers.Dense(64, activatinotallow='relu'),
tf.keras.layers.Dropout(0.5), # 50% Dropout
tf.keras.layers.Dense(10, activatinotallow='softmax')
])
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Summary of the model
model.summary()数据增强
数据增强是通过对训练数据进行一些随机变换(如旋转、翻转、缩放、裁剪等),人为地扩充数据集的规模,使模型能够看到更多的“不同”的数据,从而减少过拟合。
这些变换不会改变数据的标签,但会增加训练数据的多样性,迫使模型对不同的输入具有更强的鲁棒性。
 图片
图片
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Create an ImageDataGenerator with augmentation
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# Example of applying the augmentation to an image
# Assuming 'images' is a numpy array of images
augmented_images = datagen.flow(images, batch_size=32)
# Use the augmented data for training
model.fit(augmented_images, epochs=10)添加噪声
在训练过程中,向输入或隐藏层的神经元加入随机噪声,以增强模型的鲁棒性。
例如,可以向输入数据中加入高斯噪声或其他分布的噪声。
这样模型可以在面对真实数据中的扰动或噪声时表现得更好,从而提升泛化能力。
 图片
图片
Batch Normalization
批归一化(Batch Normalization)也是一种广泛使用的正则化技术,它的主要目的是解决训练过程中的“内部协变量偏移”,即网络的每一层输入分布在训练过程中不断变化的问题。
BN 将每一批数据的输入进行归一化,使得输入数据的均值为0,方差为1,然后再对其进行缩放和平移:































