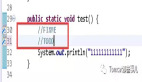
秘籍一:自动化文件操作
处理大量的文件时,手动操作不仅耗时还容易出错。Python可以帮你自动完成这些任务。
示例:批量重命名文件
代码解释:这段代码定义了一个rename_files函数,它接收两个参数——文件夹路径和新的文件名前缀。函数首先获取指定目录下所有文件的列表,然后遍历每个文件,生成一个新的文件名,并使用os.rename()函数重命名文件。
秘籍二:高效的数据处理
Python中的Pandas库是处理表格数据的强大工具。学会使用它,能极大提高数据分析效率。
示例:清洗和分析CSV数据
输出结果:
代码解释:这里我们使用Pandas库读取了一个CSV文件,并删除了其中含有空值的行。接着打印了数据框的前几行以及描述性统计信息,帮助我们快速了解数据的基本情况。
秘籍三:文本处理利器 —— 正则表达式
正则表达式(Regular Expression)是一种强大的文本匹配工具,可以帮助我们快速处理文本数据。无论是查找特定模式的字符串,还是替换某些内容,正则表达式都是一个不可或缺的工具。
示例:提取邮箱地址
输出结果:
代码解释:这段代码定义了一个extract_emails函数,用于从给定文本中提取所有符合邮箱格式的字符串。我们使用了正则表达式r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'来匹配邮箱地址,并通过re.findall()函数返回所有匹配的结果。
秘籍四:自动化Excel操作
在工作中,我们经常需要处理Excel表格。使用Python的openpyxl库,我们可以轻松地读取、修改和创建Excel文件。
示例:读取并修改Excel表格
代码解释:这段代码定义了一个modify_excel函数,用于读取并修改Excel文件。我们首先使用load_workbook()函数加载指定路径的Excel文件,然后选择第一个工作表(默认为活动工作表),修改A1单元格的内容,并将修改后的工作簿保存回原文件。
秘籍五:Web自动化爬虫
很多时候我们需要从网页上抓取数据。Python的requests和BeautifulSoup库可以帮助我们轻松实现这一目标。
示例:爬取网页内容
输出结果:
代码解释:这段代码定义了一个web_scraping函数,用于爬取指定URL的网页内容。我们使用requests.get()发送HTTP请求,然后使用BeautifulSoup解析返回的HTML内容。最后提取页面的标题并返回。
秘籍六:自动化邮件发送
在工作中,我们常常需要发送一些报告或通知。Python的smtplib库可以让我们轻松实现自动化邮件发送。
示例:发送邮件
代码解释:这段代码定义了一个send_email函数,用于发送邮件。我们首先创建一个SMTP连接,并使用starttls()和login()方法进行安全认证。接着创建一个邮件对象,设置邮件的主题、发件人和收件人,最后使用sendmail()方法发送邮件,并关闭连接。
以上就是今天的六个秘籍。通过这些技巧,我们可以看到Python在提高工作效率方面的巨大潜力。希望这些方法能够帮助你在日常工作中更加高效地完成任务。敬请期待更多实用技巧!