在数据处理领域,Python凭借其丰富的库和简洁的语法成为众多开发者的首选语言。无论是数据清洗、统计分析还是复杂的数据处理任务,Python都能提供高效的解决方案。本文将介绍九个实用的Python技巧,帮助你简化日常的数据处理工作。

1. 使用列表推导式快速处理数据
列表推导式是Python中一种非常强大的工具,它允许我们以简洁的方式创建新的列表。相比于传统的循环结构,列表推导式的语法更加简洁,同时执行效率也更高。
示例:假设我们需要从一个数字列表中筛选出所有的偶数。
这里的[num for num in numbers if num % 2 == 0]就是列表推导式的语法结构,它可以读作“从numbers中选择所有能够被2整除的元素,并将它们放入新列表中”。
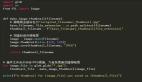
2. 利用Pandas库进行高效的数据清洗
Pandas是一个非常流行的Python数据分析库,它提供了大量用于操作表格数据的功能。当涉及到数据清洗时,Pandas简直是神器般的存在。
示例:去除DataFrame中的重复行。
运行上述代码后,你会得到一个没有重复记录的新DataFrame:
3. 使用NumPy进行高效的数组运算
NumPy是Python科学计算的基础包之一,它支持大量的多维数组(矩阵)和向量代数运算。对于那些需要频繁处理数值型数据的朋友来说,NumPy绝对是不二之选。
示例:计算两个数组之间的欧几里得距离。
这里,np.linalg.norm()函数计算了两个向量之间的欧氏距离。这个距离可以用来衡量两组数据之间的相似度。
4. 字典推导式轻松完成数据映射
除了列表推导式之外,Python还支持字典推导式,这使得我们可以非常方便地创建或修改字典。
示例:根据给定的键值对创建一个新的字典。
{key: value for key, value in zip(keys, values)}就是字典推导式的语法形式,它表示“将keys和values中的对应元素作为键值对添加到新字典中”。
5. 运用集合(set)快速找出两组数据的交集
集合是Python内置的一种数据类型,它不允许包含重复元素,并且支持一些数学上的集合操作,如并集、交集等。
示例:找出两个列表的公共元素。
通过调用set().intersection()方法,我们轻松地找到了两个列表中的共有项。这种方法比传统的双重循环检查方式要高效得多。
6. 使用生成器表达式节省内存
生成器表达式类似于列表推导式,但它返回的是一个生成器对象,而不是一个列表。这意味着生成器表达式只会在需要的时候生成数据,从而大大节省内存。
示例:创建一个生成器表达式来计算平方数。
输出:
在这个例子中,(x ** 2 for x in range(10))是一个生成器表达式。它会按需生成每个平方数,而不是一次性生成整个列表。这样可以显著减少内存消耗。
7. 使用正则表达式进行复杂的字符串匹配
正则表达式是一种强大的文本处理工具,可以用来搜索、替换和解析字符串。Python中的re模块提供了丰富的正则表达式功能。
示例:提取字符串中的电子邮件地址。
这里,re.findall()函数用于查找所有匹配指定模式的子串。r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b' 是一个正则表达式,用于匹配电子邮件地址。同样,r'\+\d{10}' 用于匹配电话号码。
8. 使用字典的方法进行高效的数据统计
字典提供了许多有用的方法,可以帮助我们快速完成数据统计任务。例如,collections.Counter类可以方便地统计元素出现的次数。
示例:统计列表中各个元素出现的次数。
Counter(fruits) 创建了一个计数器对象,其中包含了每个元素及其出现的次数。这种方法比手动编写循环统计要简单得多。
9. 使用Pandas进行数据聚合与分组
Pandas不仅支持基本的数据清洗,还可以进行复杂的数据聚合和分组操作。这对于分析大规模数据集非常有帮助。
示例:根据性别分组计算平均年龄。
输出:
这里,df.groupby('Gender')['Age'].mean() 将数据按照性别分组,并计算每个性别下的平均年龄。这种方法非常适合进行数据分析和报告生成。
总结
本文介绍了九个实用的Python技巧,涵盖了列表推导式、Pandas库、NumPy、字典推导式、集合操作、生成器表达式、正则表达式、字典统计以及Pandas的数据聚合。通过这些技巧的应用,你可以更高效地处理各种数据问题。希望这些内容能帮助你在日常工作中提升效率。