前言
最近我有位小伙伴问我,在实际工作中,批量更新的代码要怎么写。
这个问题挺有代表性的,今天拿出来给大家一起分享一下,希望对你会有所帮助。
1.案发现场
有一天上午,在我的知识星球群里,有位小伙伴问了我一个问题:批量更新你们一般是使用when case吗?还是有其他的批量更新方法?
我的回答是:咱们星球的商城项目中,有批量更新的代码可以参考一下,这个项目中很多代码,大家平时可以多看看。
然后我将关键代码发到群里了,这是批量重置用户密码的业务场景:
有小伙伴说,第一次见到这种写法,涨知识了。
还有小伙伴问,上面这种写法,跟直接for循环中update有什么区别?
直接for循环需要多次请求数据库,网络有一定的开销,很显然没有批量一次请求数据库的好。
2.其他的批量更新写法
有小伙说,他之前一直都是用的case when的写法。
类似下面这样的:
但这种写法显然需要拼接很多条件,有点复杂,而且性能也不太好。
还有些文章中介绍,可以使用在insert的时候,可以在语句最后加上ON DUPLICATE KEY UPDATE关键字。
在插入数据时,数据库会先判断数据是否存在,如果不存在,则执行插入操作。如果存在,则执行更新操作。
这种方式我之前也用过,一般需要创建唯一索引。
因为很多时候主键id,是自动增长的或者根据雪花算法生成的,每次都不一样,没法区分多次相同业务参数请求的唯一性。
因此,建议创建一个唯一索引,来保证业务数据的唯一性。
比如:给username创建唯一索引,在insert的时候,发现username已存在,则执行update操作,更新password。
这种方式批量更新数据,性能比较好,但一般的大公司很少会用,因为非常容易出现死锁的问题。
因此,目前批量更新数据最好的选择,还是我在文章开头介绍的第一种方法。
3.发现了一个问题
群里另外一位小伙伴,按照我的建议,在自己的项目中尝试了一下foreach的这种批量更新操作,但代码报了一个异常:
这个异常是阿里巴巴druid包的WallFilter中报出来了。
它里面有个checkInternal方法,会对sql语句做一些校验,如果不满足条件,就会抛异常:

而druid默认不支持一条sql语句中包含多个statement语句,例如:我们的批量update数据的场景。
此外,MySQL默认也是关闭批量更新数据的,不过我们可以在jdbc的url要上,添加字符串参数:&allowMultiQueries=true,开启批量更新操作。
比如:
这个改动非常简单。
但WallFilter中的校验问题如何解决呢?
于是,我上网查了一下,可以通过参数调整druid中的filter的判断逻辑,比如:
通过设置filter中的multi-statement-allow和none-base-statement-allow为true,这样就能开启批量更新的功能。
4.一直不生效
普通使用druid的datasource配置,通过上面这样调整是OK的。
但有些小伙伴发现,咱们的商城项目中,通过上面的两个地方的修改,还是一直报下面的异常:
这是怎么回事呢?
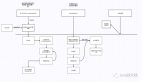
答:咱们商城项目中的订单表,使用shardingsphere做了分库分表,并且使用baomidou实现多个数据源动态切换的功能:
我们是使用了baomidou包下的数据源配置,这个配置在DynamicDataSourceProperties类中:
这个类是数据库的配置类,我们可以看到master和druid的配置是在同一层级的,于是,将application.yml文件中的配置改成下面这样的:
这样改动之后,商城项目中使用foreach这种批量更新数据的功能OK了。
5.最后
本文由一位球友的问题开始,讨论了批量更新的四种常见方式:
- for循环中一条条更新。
- foreach拼接update语句后批量更新。
- 使用case when的方式做判断。
- 使用insert into on duplicate key update语法,批量插入或者批量更新。
虽说有很多种方式,但我个人认为批量update的最佳方式是第2种方式。
但需要需要的地方是,使用foreach做批量更新的时候,一次性更新的数据不宜太多,尽量控制在1000以内,这样更新的性能还是不错的。
如果需要更新的数据超过了1000,则需要分成多批更新。
此外,如果大家遇到执行批量update操作,不支持批量更新问题时:
首先要在数据库连接的url后面增加&allowMultiQueries=true参数,开启数据的批量更新操作。
如果使用了druid数据库驱动的,可以在配置文件中调整filter的参数。
主要是multi-statement-allow设置成true。
如果你还使用了其他第三方的数据库中间件,比如我使用了baomidou实现多个数据源动态切换的功能。
这时候,需要查看它的源码,确认它multi-statement-allow的配置参数是怎么配置的,有可能跟druid不一样。