当你完成了编写和部署了项目,下一步就是去改进、消除瓶颈、提高执行速度和优化性能,得先了解项目现有的性能瓶颈和逻辑慢的地方。但是,没有人喜欢猜测哪些部分可能更慢的试错过程。
Node.js 提供了各种内置性能钩子函数来衡量执行速度,找出代码的哪些部分值得优化,并收集应用程序代码执行的精细视图。
在本文中,您将学习如何使用 Node.js 性能钩子函数和测量 API 来识别瓶颈并增强应用程序的性能,从而加快响应时间并提高资源效率。
Node.js的Performance API 概述
首先要了解为什么以及何时应该使用 Node 提供的 Performance API以及它提供的各种选项,考虑这样一种情况:您想要测量特定代码块的执行时间。
为此,您可能已经使用了 Date 对象,如下所示:
let start = Date.now();
for (let i = 0; i < 10000; i++) { } // stand-in for some complex calculation
let end = Date.now();
console.log(end - start);但是,如果您运行上述操作并观察,您会注意到这还不够精确。
例如,像上面这样的空循环会将 0 或 1 记录为差值,并且不会给我们足够的粒度。Date 类只能提供毫秒级的粒度,如果代码以 100 纳秒的顺序运行,这不会给我们正确的测量结果。
为此,我们可以改用 Performance API 来获得更好的测量结果:
const {performance} = require('node:perf_hooks');
let start = performance.now()
for (let i = 0; i < 10000; i++) {}
let end = performance.now()
console.log(end - start);这样,我们就可以得到一个更精细的值,在我的系统上,该值在 0.18 到 0.21 毫秒的范围内,精度高达 15-16 位小数。这是我们可以使用 Node Performance API 更好地测量执行时间的一种简单方法。
该 API 还提供了一种在程序运行期间精确标记时间点的方法。我们可以使用performance.mark方法获取高精度事件的时间戳,例如循环迭代的开始时间。
运行下面代码:
let start_mark = performance.mark("loop_start",
{detail:"starting loop of 1000 iterations"}
);
for (let i = 0; i < 10000; i++) {}
let end_mark = performance.mark("loop_end",
{detail:"ending loop of 1000 iterations"}
);
console.log( start_mark, end_mark );输出:
PerformanceMark {
name: 'loop_start',
entryType: 'mark',
startTime: 27.891528000007384,
duration: 0,
detail: 'starting loop of 1000 iterations'
}
PerformanceMark {
name: 'loop_end',
entryType: 'mark',
startTime: 28.996093000052497,
duration: 0,
detail: 'ending loop of 1000 iterations'
}mark 函数将标记的名称作为第一个参数。第二个参数对象中的detail允许提供有关该标记的额外详细信息,例如运行的迭代次数、数据库查询参数等。
然后,可以使用 mark 函数返回的对象通过 Prometheus exporter sdk 将计时数据导出到 Prometheus 之类的东西。这允许我们在应用程序外部查询和可视化耗时信息。由于 mark 是一个瞬时时间点,因此返回对象中的 duration 字段始终为零。
而不是手动调用 performance.now 并计算两个事件之间的差异,我们可以使用 marks 和 measure 函数执行相同的操作。我们可以使用上面标记的名称来测量两个标记之间的持续时间:
performance.mark("loop_start",
{detail:"starting loop of 1000 iterations"}
);
for (let i = 0; i < 10000; i++) {}
performance.mark("loop_end",
{detail:"ending loop of 1000 iterations"}
);
console.log(performance.measure("loop_time","loop_start","loop_end"));measure 的第一个参数是我们要为测量指定的名称。然后,接下来的两个参数分别指定要开始和结束测量的标记的名称。
这两个参数都是可选的 — 如果两者都没有给出,则为 performance.measure 将返回应用程序启动和测度调用之间经过的时间。如果我们只提供第一个参数,该函数将返回性能之间经过的performance.mark替换为该名称和 measure 调用。
如果两者都提供,该函数将返回它们之间的高精度时间差。对于上面的示例,我们将得到如下输出:
PerformanceMeasure {
name: 'loop_time',
entryType: 'measure',
startTime: 27.991639000130817,
duration: 1.019368999870494
}这可以再次与 Prometheus exporter 一起使用,以便导出自定义测量指标。如果您的设置执行蓝绿或 Canary 部署,则可以比较旧版本和新版本的性能,以查看您的优化是否按预期工作。
最后,需要注意的一点是,Performance API 在内部使用固定大小的缓冲区来存储标记和度量,因此我们需要在使用完它们后对其进行清理。这可以使用以下方法完成:
performance.clearMarks("mark_name");或者:
performance.clearMeasures("measure_name");这些函数将从相应的缓冲区中删除具有给定名称的标记/度量。如果在不提供任何参数的情况下调用这些函数,它们将清除缓冲区中存在的所有标记/度量,因此在没有任何参数的情况下调用这些函数时要小心。
使用 Performance钩子优化您的应用
现在让我们看看如何使用这个 API 来优化我们的应用程序。在我们的示例中,我们将考虑从数据库中获取一些数据,然后手动排序并将其返回给用户的情况。
我们想了解每个操作需要多少时间,以及首先优化的最佳位置是什么。为此,我们将首先测量发生的各种事件:
async function main(){
const querySize = 10; // ideally this will come from user's request
performance.mark("db_query_start",{detail:`query size ${querySize}`});
const data = fetchData(querySize);
performance.mark("db_query_end",{detail:`query size ${querySize}`});
performance.mark("sort_start",{detail:`sort size ${querySize}`});
const sorted = sortData(data);
performance.mark("sort_end",{detail:`sort size ${querySize}`});
console.log(performance.measure("db_time","db_query_start","db_query_end"));
console.log(performance.measure("sort_time","sort_start","sort_end"));
// clear the marks...
}我们首先声明查询大小,在实际应用程序中,它可能来自用户的请求。
然后我们使用performance.mark 函数来标记数据库获取和排序操作的开始和结束。最后,我们使用 performance 输出这些事件之间的持续时间。量功能。我们得到这样的输出:
PerformanceMeasure {
name: 'db_time',
entryType: 'measure',
startTime: 27.811830999795347,
duration: 1.482880000025034
}
PerformanceMeasure {
name: 'sort_time',
entryType: 'measure',
startTime: 29.31366699980572,
duration: 0.09800400026142597
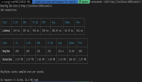
}要查看这两个操作在查询大小增加时的表现,我们将更改查询大小值并记下度量值。在我的系统上,我得到以下内容:
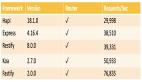
正如我们在这里看到的,随着查询大小的增加,排序时间会迅速增加,首先优化它可能更有益。通过使用一些不同的排序算法,我们得到以下内容:
虽然对于非常小的查询大小,排序时间略短,但与原始测量值相比,时间增长缓慢。因此,如果我们期望经常处理大型查询,那么在此处更改排序算法将是有益的。
同样,我们可以测量在查询字段上创建索引之前和之后数据库获取时间的差异。然后我们可以决定索引创建是否有用,或者哪些字段在用于索引时提供更多好处。
使用后台工作程序卸载任务
在创建基于 UI 的应用程序时,我们需要 UI 能够响应,即使正在进行一些繁重的处理任务也是如此。如果在处理大数据时 UI 冻结,则处理起来将是一种糟糕的用户体验。在网站上,这可以使用 Web Worker 来完成。
对于直接使用 Node 运行的应用程序,我们可以使用 Node 的 worker_threads 模块将计算密集型任务卸载到后台线程。
请注意,仅当任务是 CPU 密集型任务(例如排序或解析数据)时,这才有用。如果任务依赖于 I/O,例如读取文件或获取网络资源,则使用 Node 的 async-await 比使用 worker 更有效。
我们可以按如下方式创建和使用 worker:
const { Worker, isMainThread, parentPort, workerData, } =
require("node:worker_threads");
async function main() {
const data = await fetchData(10);
let sorted = await new Promise((resolve, reject) => {
const worker = new Worker(__filename, {
workerData: data,
});
worker.on("message", resolve);
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0)
reject(new Error(`Worker stopped with exit code ${code}`));
});
});
}
function worker() {
const data = workerData;
sortData(data);
parentPort.postMessage(data);
}
if (isMainThread) {
// we are in the main thread of our application
main().then(() => {
console.log("done");
});
} else {
// we are in the background thread spawned by the main thread
worker();
}我们首先从 worker_threads 模块导入所需的函数和变量声明。然后我们定义两个函数 —main(将在主线程中运行)和 worker (将在 worker 线程中运行)。
然后,我们检查脚本是作为主线程还是作为 worker 线程执行,并相应地调用 main/worker 函数。为了简单起见,我们在一个文件中定义了所有这些函数,但我们也可以在它们自己的文件中分离出 main 和 worker 函数。
在 main 函数中,我们像以前一样获取数据。然后我们创建一个 Promise,并在其中创建一个新的 worker。Worker 构造函数需要一个文件路径,该路径将作为Worker线程运行。
这里我们使用 __filename builtin 给它相同的文件。在第二个参数中,我们将要排序的数据作为 workerData 传递。此 workerData 将由 Node 运行时提供给 worker 线程。
最后,我们监听来自 worker 的事件 — 收到消息时,我们解决 promise,如果出现错误或非零退出代码,我们拒绝 promise。
在 worker 线程中,我们从变量 workerData 中获取从主线程传递的数据,该变量是从 worker_threads 模块导入的。在这里,我们对它进行排序,并将一条消息发布到包含排序数据的主线程。
在主线程中,我们可以将其保存在队列中或定期检查它,而不是立即等待 promise。这样,当worker线程进行排序计算时,我们可以保持主线程的响应性。我们还可以从 worker 线程发送中间消息,指示排序进度。
优化 Node 应用程序的常见提示
虽然每个应用程序都有自己的性能优化方法,但Node.js应用程序有一些常见的起点。
优化前观察
在开始优化应用程序之前,您必须检测和测量应用程序的性能,以便您可以准确了解哪些函数或 API/DB 调用需要优化。
尝试进行盲目优化可能会降低性能,这就是为什么使用 Node 提供的性能钩子和 API 进行测量是一个很好的起点。
有一种简单的方法来重复测量
要确定您的优化是否有效,您应该有一种方便的方法来衡量之前和之后的性能。
这可以通过拥有两个构建来完成 —--- 一个有更改,一个没有更改,有一个运行测试和测量的脚本,以及可以为您提供比较的东西。为更改提供明确的前后性能值可以帮助您确定这些更改是否值得。
尝试为数据库编制索引并缓存请求/响应
如果您的应用程序使用数据库并频繁查询,则应考虑在查询的参数上创建索引,以提高检索性能。
这将以可能增加存储大小和可能增加插入/更新查询时间为代价,因此您应该仔细衡量使用案例中的前后,并确定权衡是否良好。
提高性能的另一种方法是使用一些缓存方案,以便快速响应数据库或 API 查询。如果您可以使用查询参数缓存 API 响应,然后使用此缓存响应以后的请求,则可以有效地使用它。
请注意,缓存是一把双刃剑。您需要仔细评估保留缓存条目的时间、逐出条目的依据以及何时使缓存失效。错误地执行此操作不仅会降低您的性能,而且还有可能在用户之间发送不正确的数据或泄露的数据。
减少依赖性
如果您曾经查看 node_modules 或检查过node_modules 所占用的磁盘大小,您就会知道 Node 项目中的依赖关系有多严重。
添加新的依赖项时需要小心,因为它们可能会添加更多的传递依赖项,而解析所有这些依赖项可能会影响应用程序的启动性能。您可以尝试通过以下方法缓解此问题:
- 删除未使用的软件包 — 有时软件包中有多个软件包。JSON 格式这些 ID 不再在应用程序中使用,可以删除。这对于缩小依赖项的数量和软件包的构建大小非常有用
- 使用打包器对
tree-shaking并从最终构建中删除未使用的模块 — 在捆绑和打包应用程序时,您可以使用捆绑器提供的功能从依赖项中删除未使用的模块。您只保留代码使用的依赖项部分,而不将其余部分包含在最终构建中 - 从依赖项中提供所需的特定代码 — 当您只需要代码的一小部分时,而不是将整个包添加为依赖项,而是提供代码的特定部分。执行此操作时,请务必检查并遵守原始代码的许可证
- 延迟加载依赖项 — 您可以延迟加载依赖项以提高启动性能,并在不需要该依赖项的情况下减少内存使用量
结论
Node 提供的Performance API 不仅可以帮助确定哪些部分速度较慢,还可以帮助确定它们需要多少时间。您可以通过将这些数据作为跟踪或指标导出到Jaeger或 Prometheus 之类的内容来进一步探索这些数据。
请记住 — 拥有大量数据只会使其更难探索,因此一个好的策略是首先只测量粗略事件的时间,例如函数调用甚至请求的端到端处理,然后为花费最多时间的函数添加越来越多的细粒度测量。
原文地址:https://blog.logrocket.com/node-js-performance-hooks-measurement-apis-optimize-applications/
原文作者:Yashodhan Joshi
本文译者:一川