译者 | 朱先忠
译者 | 重楼
要理解本文中的内容,你需要掌握Jaccard相似性和向量搜索等预备知识。本文算法的实现已在GitHub(https://github.com/atlantis-nova/simtag)上发布,并且是完全开源的。
简介
多年来,我们已经发现了如何从诸如数字、原始文本、图像和标签等不同类型的模式数据中检索信息。
随着应用程序定制用户接口的日益普及,标签搜索系统已成为一种方便、准确的信息过滤方式。通常,使用标签搜索的一些代表性场景包括检索社交媒体帖子、文章、游戏、电影,甚至简历等领域。
然而,传统的标签搜索缺乏灵活性。如果我们要过滤完全包含给定标签的样本,可能会出现以下情况,特别是对于仅包含几千个样本的数据库,可能没有任何(或只有少数)与我们的查询匹配的样本。
缺乏有关信息时两种搜索方案的搜索结果差异(作者本人提供图片)
通过下面的内容,我将介绍几种新的搜索算法。就我所知,目前我还没有在网络上找到与此相同的算法。
传统标签搜索是如何工作的?
传统系统采用一种称为Jaccard相似度的算法(通常通过Minhash算法执行),该算法能够计算两组元素之间的相似度(在我们的例子中,这些元素是标签)。如前所述,这样的搜索根本不灵活(无论集合中包含或是不包含查询的标签)。
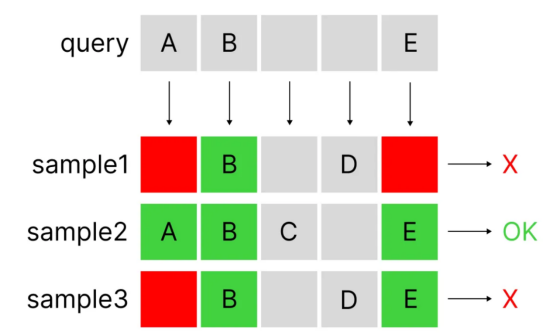
一个简单的AND位操作示例(尽管这里给出的并非是Jaccard相似性,但是能够展示过滤方法的大致概念)(作者本人提供图片)
我们能做得更好吗?
如果我们不只是从匹配的标签中过滤样本,而是考虑样本中所有其他不相同但与我们选择的标签相似的标签,那么情况会怎么样呢?我们可以使算法更加灵活,将结果扩展到非完美匹配,但仍然是良好的匹配。我们的思路是:直接将语义相似性应用于标签,而不是文本。
语义标签搜索算法
正如文章开头提到的那样,这种新方法试图将语义搜索的功能与标签过滤系统相结合。为了构建这个算法,我们只需要做一件事:
- 创建一个标记样本的数据库
在本文示例项目中,我将使用的参考数据是Steam游戏库的开源集合(可从Kaggle下载:https://www.kaggle.com/datasets/fronkongames/steam-games-dataset,遵循MIT许可证)——大约有40000个样本,这是用于测试我们算法的不错的样本。正如我们从显示的数据帧中看到的,每个游戏都对应几个已分配的标签,我们的数据库中共有400多个唯一的标签。
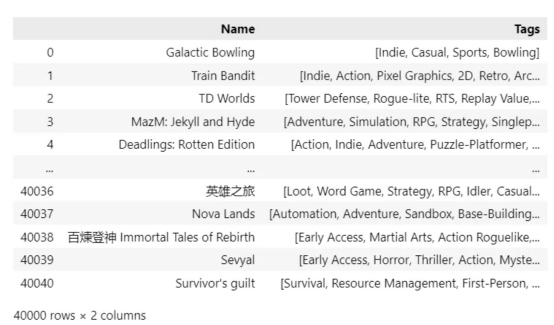
示例源文件中提供的Steam数据帧截图(作者本人提供图片)
现在,我们已经准备好了初始数据,就可以继续接下来的工作了。
我们的算法将通过以下步骤进行阐述:
- 提取标签关系
- 对查询和样本进行编码
- 使用向量检索执行语义标签搜索
- 验证
在本文中,我将只分析这种新方法背后的数学原理(有关代码的深入解释和工作演示,请参阅本文示例工程源码:https://github.com/atlantis-nova/simtag/blob/main/notebooks/steam_example.ipynb。有关如何使用simtag的说明,请参阅源码工程根目录下的README.md文件)。
1.提取标签关系
首先想到的问题是,我们如何找到标签之间的关系。请注意,目前已经存在几种算法可用于获得相同的结果:
- 使用统计方法
我们可以用来提取标签关系的最简单的方法称为共现矩阵(co-occurrence matrix),这是我将在本文中使用的格式(出于其有效性和简单性)。
- 使用深度学习
最先进的都是基于嵌入神经网络(如过去使用的Word2Vec;现在通常使用转换器,如LLM),可以提取样本之间的语义关系。创建一个神经网络来提取标签关系(以自动编码器的形式)是可能的,而且在面对某些情况时通常也是明智的方案。
- 使用预训练模型
因为标签是使用人类语言定义的,所以可以使用现有的预训练模型来计算已经存在的相似性。这可能会更快,而且减少了麻烦。然而,每个数据集都有其独特性。不足的一点是,使用预先训练的模型将忽略客户行为。
例如,我们稍后将看到2D与Fantasy有着密切的关系:但是,使用预先训练的模型永远不会发现这样的匹配对。
算法的选择可能取决于许多因素,特别是当我们必须处理庞大的数据池或有可扩展性问题时(如果我们拥有太多的标签,那么我们需要使用机器学习来解决这个问题)。
a.使用Michelangiolo相似性构建共现矩阵
如前所述,我将使用共现矩阵作为提取这些关系的手段。我的目标是找到每对标签之间的关系。为此,我将使用IoU(联合上的交集)对所有样本集(S)应用以下计数:
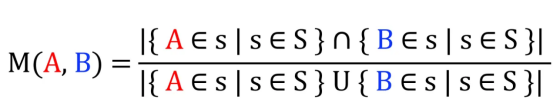
计算一对标签之间相似度的公式(作者本人提供图片)
该算法与Jaccard相似度非常相似。虽然这种算法针对样本进行操作(而我介绍的那种算法针对元素进行操作),但是由于(据我所知)这个特定的应用程序尚未被编程实现过;因此,我们可以将其命名为Michelangiolo相似性。(公平地说,这个算法的使用以前在StackOverflow问题中已经提到过,但从未被编程实现过)。
Jaccard相似性和Michelangiolo相似性的差异(作者本人提供图片)
对于40000个样本,提取相似性矩阵大约需要一个小时,结果如下:
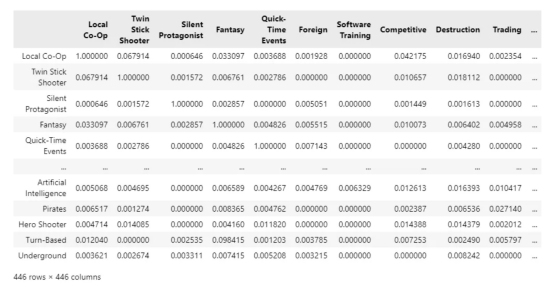
样本列表S中所有唯一标签的共现矩阵(作者本人提供图片)
接下来,让我们手动检查前10个样本中一些比较常见的标签,看看结果是否有意义:
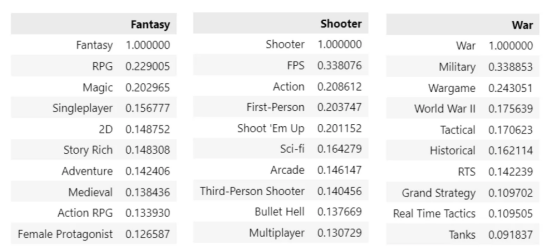
从共现矩阵中提取的样本关系(作者本人提供图片)
结果看起来很有希望!我们从简单的分类数据(只能转换为0和1)开始,但我们提取了标签之间的语义关系(甚至没有使用神经网络)。
b.使用预训练的神经网络
同样,我们可以使用预训练的编码器(https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)提取样本之间的现有关系。然而,这种解决方案忽略了只能从我们的数据中提取的关系,只关注人类语言的现有语义关系。注意,这种算法可能不是一个非常适合基于零售数据的工作解决方案。
另一方面,通过使用神经网络,我们不再需要构建关系矩阵。因此,当关注可扩展性时,这是一种比较适当的解决方案。例如,如果我们必须分析大量的推特数据,我们会得到53.300个标签。根据这个数量的标签计算共现矩阵将得到大小为2500000000的稀疏矩阵(这是一个非常不切实际的壮举)。相反,通过使用输出向量长度为384的标准编码器,得到的矩阵的总大小将为19200200。
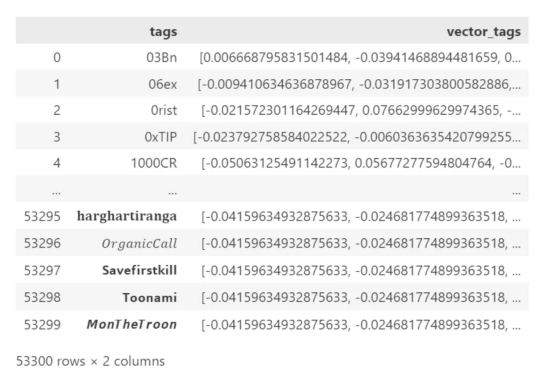
使用预训练编码器对一组标签进行编码的快照数据
2.对查询和样本进行编码
我们的目标是构建一个能够支持语义标签搜索的搜索引擎:根据我们一直在构建的格式,唯一能够支持这种方案的技术是使用向量搜索。因此,我们需要找到一个合适的编码算法,将样本和查询转换为向量。
在大多数编码算法中,我们都会使用相同的算法对查询和样本进行编码。然而,每个样本都包含多个标签,而每个标签都由一组不同的关系表示;因此,我们需要在单个向量中捕获这些关系。

协变量编码(作者本人提供图片)
此外,我们需要解决上述可扩展性问题,我们将通过使用PCA模块来实现(当我们使用共现矩阵时,我们可以跳过PCA,因为不需要压缩我们的向量)。
当标签的数量变得太大时,我们需要放弃计算共现矩阵的可能性,因为它以平方速率缩放。因此,我们可以使用预训练的神经网络提取每个现有标签的向量(PCA模块的第一步)。例如,all-MiniLM-L6-v2模型将每个标签转换为长度为384的向量。
然后,我们可以转置获得的矩阵,并对其进行压缩:我们最初将使用1和0对可用标签索引对查询/样本进行编码,从而得到与初始矩阵(53300)长度相同的初始向量。此时,我们可以使用预先计算的PCA实例在大小为384的维度中压缩相同的稀疏向量。
编码样本
就我们的样本而言,该过程在PCA压缩(激活时)后立即结束。
编码查询:协变量编码
我们的查询需要以不同的方式编码:我们需要考虑与每个现有标签相关的关系。这个过程是通过首先将压缩向量与压缩矩阵(所有现有关系的总和)相加来执行的。现在,我们已经获得了一个矩阵(384x384),我们需要对其进行平均计算,从而获得我们的查询向量。
因为我们将使用欧几里德搜索,它将首先优先搜索得分最高的特征(理想情况下,我们使用数字1激活的特征),但它也会考虑额外的次要得分情况。
加权搜索
因为我们将向量平均在一起,所以我们甚至可以对此计算应用权重,向量将受到与查询标签不同的影响。
3.使用向量检索执行语义标签搜索
你可能会问这样的问题:为什么我们要经历这个复杂的编码过程,而不仅仅是将这对标签输入到函数f(query, sample)中并获得一个分值?
如果你熟悉基于向量的搜索引擎,你已经知道答案了。通过成对执行计算,在只有40000个样本的情况下,所需的计算能力是巨大的(单个查询可能需要长达10秒):这不是一种可扩展的做法。然而,如果我们选择对40000个样本进行向量检索,搜索将在0.1秒内完成:这是一种高度可扩展的做法,在我们的应用情况下这是非常完美的办法。
4.验证
为了使算法有效,需要对其进行验证。目前,我们缺乏适当的数学验证(乍一看,对M的相似性得分进行平均已经显示出非常有希望的结果,但需要进一步的研究来获得有证据支持的客观指标)。
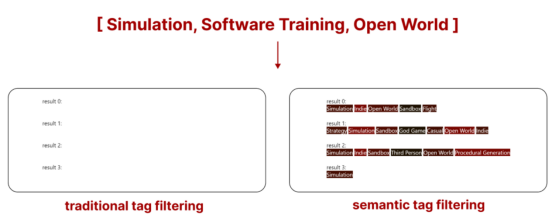
然而,当使用比较示例并可视化比较时,现有结果的优势是非常直观的。以下是两种搜索方法的最靠近顶部的搜索结果比较(你看到的是分配给此游戏的标签)。
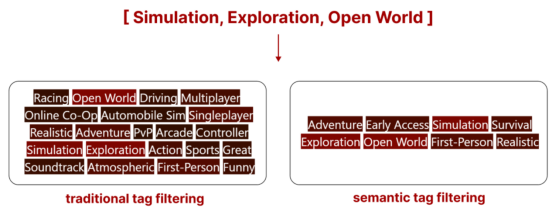
传统标签搜索与语义标签搜索的比较
- 传统标签搜索
我们可以看到传统搜索可能会(在没有额外规则的情况下,样本会根据所有标签的可用性进行过滤,而不是排序)返回具有更多标签的样本,但其中许多标签可能并不相关。
- 语义标签搜索
语义标签搜索根据所有标签的相关性对所有样本进行排序。简单来说,它取消了包含不相关标签的样本的资格。
这个新系统的真正优势在于,当传统搜索无法返回足够的样本时,我们可以使用语义标签搜索来选择任意数量的样本。
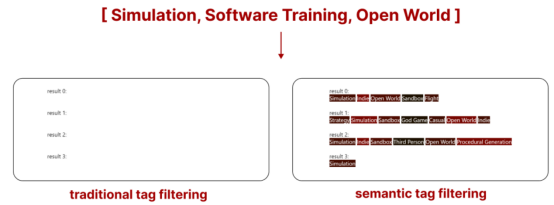
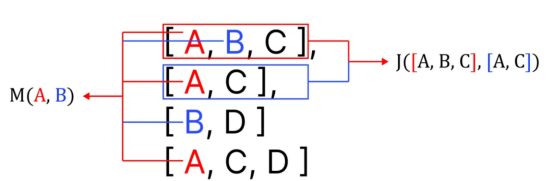
两次搜索结果稀缺前的差异(作者本人提供图片)
在上面的例子中,使用传统的标签过滤不会从Steam库中返回任何游戏。然而,通过使用语义标签过滤,尽管我们仍然会得到不完美的结果,但会得到与我们的查询最匹配的结果。你看到的是与我们的搜索匹配的前5个游戏的标签。
结论
在此之前,如果不采用复杂的方法,如聚类、深度学习或多个K近邻算法(KNN)搜索,就不可能在考虑标签语义关系的情况下对标签进行过滤。
本文中给出的算法提供的灵活性应允许与传统的手动标记方法分离,后者迫使用户在一组预定义的标签之间进行选择,并开辟了使用视觉语言模型的LLM自由地将标签分配给文本或图像的可能性,而不局限于预先存在的结构,从而为可扩展和改进的搜索方法开辟了新的选择方案。
最后,我怀着最美好的祝愿决定向全世界开放这个算法,我也十分希望它能得到充分的利用。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Introducing Semantic Tag Filtering: Enhancing Retrieval with Tag Similarity,作者:Michelangiolo Mazzeschi