













R-CNN 模型是为对象检测而开发的深度学习方法之一。这种架构被称为基于区域的卷积神经网络,通过结合卷积神经网络的力量和基于区域的方法,在对象检测领域取得了重大进展。R-CNN 用于检测图像中的对象类别以及这些对象的边界框。由于直接在包含多个对象的图像上运行 CNN 可能很困难,因此开发了 R-CNN 架构来克服这些问题。

R-CNN 通常使用支持向量机 (SVM) 进行分类过程。对于每个类别,训练一个单独的 SVM 来确定区域提议是否包含该类别的一个实例。在训练期间,正例被定义为包含类别实例的区域,而负例则由不包含这些示例的区域组成。这种架构遵循两阶段过程:第一阶段识别可能的对象区域;第二阶段通过分类这些区域并细化其边界来识别对象。
在 R-CNN 模型之后,开发了 Fast R-CNN,然后是 Faster R-CNN 架构。在本文中,我们将讨论 Faster R-CNN 架构。Ross Girshick 及其同事介绍了 Faster R-CNN 架构,并在文章 [1] 中讨论了技术细节。
Faster R-CNN 使用区域提议网络 (RPN)。Faster R-CNN 架构由两层组成。
- 区域提议网络 (RPN):RPN 是一个深度的卷积神经网络,用于推荐区域。它接受任何大小的输入,并根据对象得分揭示可能属于一系列对象的矩形。它通过在卷积层创建的特征图上移动一个小网络来提出这一建议。RPN 层由锚框组成。锚框用于检测图像中的不同大小的对象。因此,它们的大小可能不同。在将图像输入 RPN 层之前,可以使用 VGG 或任何 CNN 层 Alexnet、Resnet、Imagenet 作为准备层。
- Fast R-CNN:RPN 生成的计算被插入到 Fast R-CNN 架构中,并通过分类器估计对象的类别,并通过回归器估计边界框。
可以在视觉 [2] 中详细检查用于通用对象检测的领先框架的高级图。
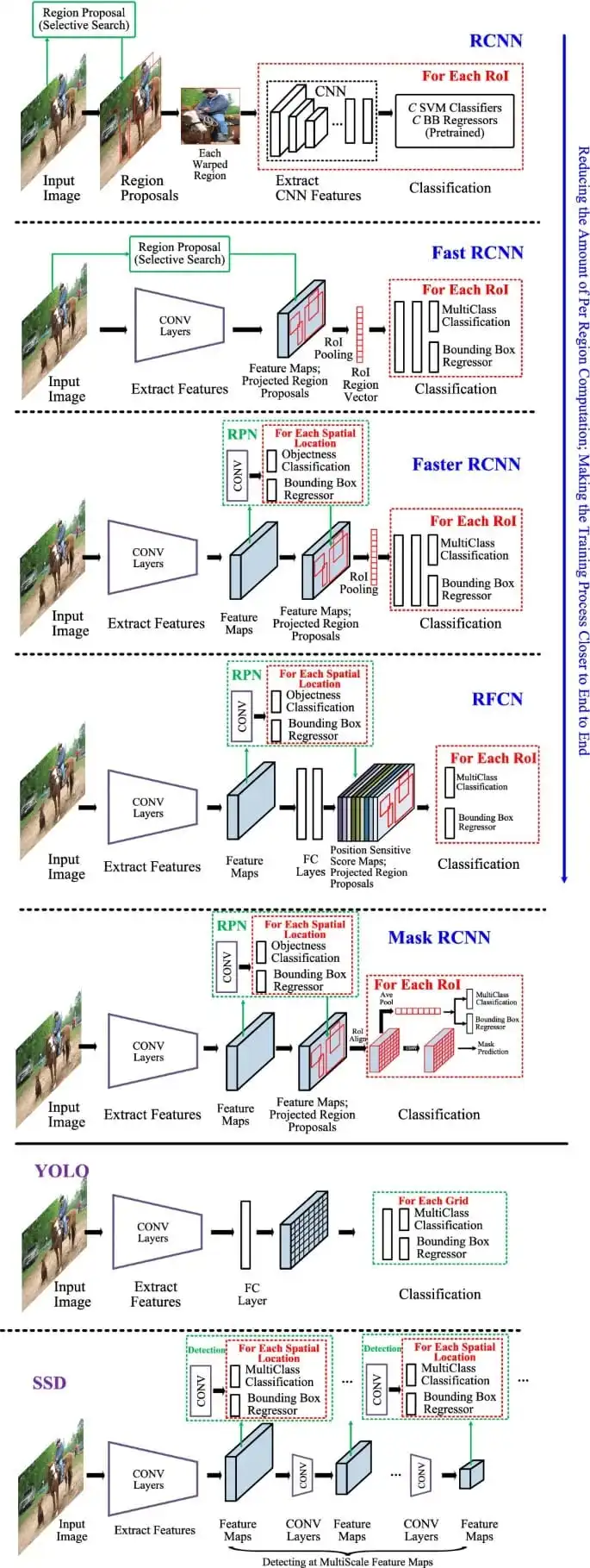
在我们的工作中,我们将使用 ResNet-50 架构。ResNet 是用于许多计算机视觉任务的经典神经网络。它防止了网络深化时的退化。为了在 ResNet 模型中实现更快的训练,使用了瓶颈块。
如果您没有必要的硬件,可以在 Google Colab 上更快地执行您的工作。为了演示如何使用 Google Colab,这个项目是使用 Colab 进行的。
让我们添加 PyTorch 库以及 torchvision 和任何其他所需库等必要的库。[3]
上传到我们将执行对象检测的 Google Drive。让我们编写将 Google Colab 连接到 Google Drive 的代码。
让我们调用我们将执行对象检测的图像。
让我们解释一下我们认为的代码的下一个阶段中两个重要阶段的概念:Compose 和 Tensor。
Compose 是一个结构,当你想要在 Pytorch 转换模块中连续对图像执行多个工作时,你可以使用它。如果你要执行多个转换,你可以在 Compase 中定义它。在这个阶段,我们只为图像应用张量操作。
张量是 PyTorch 库中使用的基本数据结构。张量可以被认为是向量和矩阵的更一般形式。RGB 图像通常被表示为一个 3 通道张量,尺寸为 [3, 高度, 宽度]。例如,一个 128x128 像素的 RGB 图像将由一个尺寸为 (3, 128, 128) 的张量表示。让我们将我们的图像转换为张量。
在这些操作之后,我们将增加张量的大小。这个过程将单个图像转换为批量大小。unsqueeze(dim=0) 参数增加了另一个维度。
下一步,让我们执行批量操作。在 Pytorch 中,模型通常同时处理多个图像,因此它们被分组到一个名为批量的图像张量列表中。让我们创建一个名为 images 变量的批量。
在我们的工作中,我们将使用 Faster R-CNN 模型、Resnet-50 架构以及在此架构基础上的 FPN。作为参数,pretrained=True 启用了以前训练过的权重的加载。这样模型就可以用 ImageNet 或 COCO 数据集进行训练。我们将在研究中使用 COCO 数据集。
model.eval() 命令用于将模型置于评估模式。模型已准备好对数据进行预测。
COCO 数据集由微软开发,包含 330K 张图像。[4]。它是用于计算机视觉任务(如对象检测、图像分割、对象检测和对象识别)的数据集。(https://cocodataset.org/#home)每张图像包含多个对象,并为每个对象提供了详细的标签。例如,对于对象检测,每张图像中的所有对象都被标记,并为每个对象确定了边界框。
另一个可以使用的广泛数据集是 ImagNet 数据集。与 ImageNet 不同,COCO 数据集允许用多个特征(位置、大小、形状、环境框、标签)对对象进行标记。因此,它是更复杂的计算机视觉任务的理想数据集。
让我们将张量转换为 NumPy 数组。我们执行这一步的原因是,在数据处理和可视化操作中,流行的可视化库(如 matplotlib)接受 NumPy 数组格式的数据。虽然像 PyTorch 这样的深度学习库使用张量,但这些数据必须转换为 NumPy 格式以进行可视化。在转换过程中,squeeze 函数移除了张量的 1 维并将其压缩,而 CPU 函数将张量移动到 CPU(如果在 GPU 中)。Numpy 只允许基于 CPU 的操作。添加了必要的代码以在轴上显示 numpy 数据。
让我们通过添加边界框和围绕检测到的对象的相应标签来可视化它。在这个阶段,按顺序采取以下步骤:
- 使用 Zip 处理边界框、标签和分数
- 坐标分离
- 获取标签名称
- 绘制边界框
- 可视化标签和分数
- 关闭轴
- 显示图像
图像:

代码输出:


























