TL;DR
- Swift 中对于类型大小为空的变量使用
&取地址是未定义行为,编译为目标码之后的体现为一个根据之前代码执行结果产生的任意数值。这是一个 feature。 - Swift 中在多个线程中对同一个变量使用
&将获取「写访问」,会造成运行时崩溃。 - Swift 中对 computed property 取地址会取到临时变量的地址。如果 computed property 是一个锁,将造成锁被拷贝到多个线程的执行栈上,造成程序错误。
平平无奇但错误的代码
在过去一个季度抖音规模化落地 Swift 组件的过程中,我负责的代码在 CI 运行单测阶段暴露了几个问题,都与 Swift 中的 unsafe pointers 有关。
第一个是通过 Objective-C 中 associated object 技巧扩展出来的 property 在 release build 后再运行,set 之后只能 get 到 nil;debug build 下则正常:

范例代码一
第二个是下列代码在 release build 后,在多线程环境有可能崩溃在 swift_endAccess 函数中:
范例代码二

是不是觉得很奇怪?以上两段代码既符合直觉,也没有编译错误。那么,为什么会产生上述问题呢?
归因:ObjC 关联对象访存出错
针对范例代码一里面 ObjC associated object 访存得到错误结果的问题,我们可以进入汇编模式,看看到底 objc_get(set)AssociatedObject 得到的参数是什么。首先打开 Xcode 的 Always Show Disassembly(看完文章后记得关闭哦),在 objc_getAssociatedObject 和 objc_setAssociatedObject 打下断点。

运行后我们可以看到 objc_setAssociatedObject 的 key 这个参数(arm64 上的 x1 寄存器)的值是 0x04000001ed295c71,这个地址存储的值是 0x00000001ed295c71。我们预期通过 dis -s 指令对这个地址进行反汇编可以获得该地址对应的二进制镜像名称,然而这里却提示「反汇编失败」。这是为什么呢?

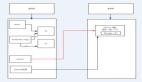
我们可以进一步检查 x1 寄存器内容的来源。下图红线为 x1 寄存器在 MyObject.myProperty.setter (下称 setter 函数)内的数据流。可以看到:
- setter 函数初始栈高为
0x20(sub sp, sp, #0x20) x1为 setter 函数执行栈基准地址 +0x40-0x48= setter 函数执行栈基准地址 -0x8。所以对应 setter 函数执行栈上0x18偏移的栈变量

而 setter 函数开头调用的 Optional<Any> 的拷贝初始化函数 outlined init with copy of Swift.Optional<Any> 的第二个参数 x1 为 setter 函数执行栈基准地址 + 0x40 - 0x60 = setter 函数执行栈基准地址 - 0x20。结合之前获得的 setter 函数执行栈高 0x20 的信息,所以对应 setter 函数执行栈上 0x0 偏移的栈变量。
于是我们可以知道,setter 函数执行栈基准地址后的所有空间都有可能被 Optional<Any> 的拷贝初始化函数利用到。而实际上这个拷贝初始化函数的第二个参数就是拷贝操作的目标地址。加上上图中蓝线的原点在判别完 x21 的内容(即 objc_setAssociatedObject 接受到的 x1)之后进行了条件跳转(cbz,即 conditional branching if zero 的缩写),跳过的内容正是把 Any 桥接到 Objective-C(因为中途有调用 Swift._bridgeAnythingToObjectiveC),所以我们可以大胆猜测:
x21 —— 即 objc_setAssociatedObject 接受到的 x1,实际上是可以判断 Optional<Any> 为空的信息——而这个并不是我们在源码中给定的 key——这就是导致我们使用 objc_get(set)AssociatedObject 不正常工作的原因。而我们一开 dis -s 之所以会失败,是因为我们在尝试对函数执行栈进行反汇编。
深入:Void 全局变量编译细节
为了了解更多代码生成细节,知道为什么生成了这样的代码,我们可以使用 Swift 编译器的 -emit-sil(gen) 和 -emit-ir(gen) 参数来考察 SIL(原始 SIL)和 IR(原始 IR)的生成结果,看到底是哪一步产生了意外。检查的顺序应该 -emit-silgen, -emit-sil, -emit-irgen, -emit-ir,确保先检查原始 SIL(SILGen)和原始 IR(IRGen),再检查优化后的 SIL 和 IR。检查 SILGen 的命令如下:
上文的 setter 函数在 SILGen 中生成了三个区块:bb0 是函数入口,在 363 行进行 switch-case 之后跳转至 bb1 或 bb2。但不论是 bb1 还是 bb2,最后都会跳转至 bb3(如下图蓝线所示)。所以我们直接看 bb3 好了。

所以我们直接折叠 bb1 和 bb2,然后可以画出 objc_setAssociatedObject 第二个参数 %32 的数据流。可以看到其最终来自于 %2,而 %2 会对一个全局 Swift 符号取地址。

而这个符号正是我们定义的 myKey。

因为 global_addr 是 SIL 指令,已经是 SIL 这一层的「原语(最小不可分割语素)」了,所以我们应该进一步查看 IRGen 的结果。
在 IRGen 结果中,我们可以直接搜索 MyObject.myProperty.setter 的 Swift 改编符号(如果你也使用 UnsafePointers.swift 这个文件名那么就是 $s14UnsafePointers8MyObjectC10myPropertyypSgvs)。我们可以看到,517 行给 objc_setAssociatedObject 的第二个参数已经变成了 undef。

为了进一步探究 SIL 中的 global_addr 指令为何在 lower 到 IR 之后会得到 undef,我们可以动态调试一下 Swift 编译器。这里我们使用简化后的代码以加速编译器调试。因为 foo 是全局变量,所以第 4 行的 &foo 仍然会生成 global_addr 指令。
然后我们在 IRGenSILFunction::visitGlobalAddrInst 中打下断点,编译上面的源代码,从 DEBUG CONSOLE 中的 i-> dump() 结果可以看到,此次 GlobalAddrInst 实例 i 的内容为被 & 引用的变量。最后代码执行进入了 2950 行,这里可以看到针对该全局变量的 ti: TypeInfo&,如果其 isKnownEmpty 返回 true 就不会生成符号,因此地址是 undef。这是一个 feature。


而 Swift 编译器中的 TypeInfo 类型负责记载类型信息对应信息。对于 TypeInfo::isKnownEmpty 而言,简单来说如果可以在编译器在编译时可以确定大小的类型,并且大小为空,即可认为其会返回 true。
归因:多线程下取地址崩溃
要理解文章开头范例代码二中所出现的「多线程下对实例变量取地址」而导致的崩溃,更直接的方法是打开 Xcode 的 Thread Sanitizer 后运行程序。我们可以看到,Xcode 帮我们检测出了「访问竞争(access race)」。这是因为在 Swift 中对变量使用 & 即意味着需要获取一个「写访问(write access)」,而目前的代码有多个线程在访问 UnfairLock.withLock,那么也就有多个线程在尝试对 UnfairLock._lock 获取「写访问」。这个在 Swift 中不符合运行时 exclusivity enforcement,所以会崩溃。


想要修复这个问题,将获得指针的时机移动至多线程代码外(即 x.testLock 外)即可。
但是 exclusivity 冲突并不是这个写法的全部问题,这个写法还有一个非常隐蔽的问题:& 可能取到的不是变量本身的地址,而是一个临时分配的变量。要理解这个问题,需要知道 Swift 是如何实现变量取地址的。
深入:Swift 变量取地址实现
在 Swift 中 var 关键字定义的变量满足以下抽象:
- 一定包含一个
getaccessor - 可选包含一个
setaccessor - 可选包含一个存储容器
然而,上面只是开发者在日常开发中能够感知到的部分。上述抽象没有解决的问题是:如果一个变量的存储容器是可选的,那么我们应该如何获得这个变量的地址呢?所以编译器还会为我们自动生成:
- 一定包含一个
_readaccessor - 可选包含一个
_modifyaccessor
其中 _read accessor 是一个对变量产生「读访问」,并且抛出一个只读地址的协程。
而 _modify accessor 是一个对变量产生「写访问」,并且抛出一个可写地址的协程。
而通过上述 _read 和 _modify accessor,我们就定义了获取 var 关键字变量地址的手段。
「协程」可以理解为不保证栈平衡的函数(或称「过程」)。协程本是过程的原始形态——过程引入栈平衡是为了实现本地变量,而这个特性在协程中无法实现。但是人们后来发现非平衡的栈可以让后续执行的代码沿用之前的栈内存内容,而不用重复在栈上传参,又或者开辟堆空间传参,所以人们又开始利用起了「协程」。Swift 引入协程的目的也是做性能优化。 需要注意的是 Swift Concurrency 并不是协程。
而在 Swift 中对变量使用 & 本质上就是获取 _modify accessor 抛出的「变量可写地址」。
我们可以从 SILGen 的结果中一窥究竟。
下面是 UnfairLock.withLock(perform:) 在未修改前的 SILGen 结果,红色的线和方框代表了 &_lock 这句 Swift 源码在 SIL 层面的数据流。
我们可以看到 &_lock 最初来自于 %6,而 %6 正是对 self (%2) 使用了 #UnfiarLock.lock!modify 这个协程产生的,同时产生的 %7 则是协程产生的非平衡栈的 resumption 函数,由 89 行的 endApply 调用,用以恢复栈平衡。

而当前实现的 UnfiarLock.lock._modify 则是通过 ref_element_addr 这条 SIL 指令直接抛出了 UnfairLock.lock 在当前 self 中的地址。

但是,当情况变得复杂一些的时候,这个 _modify accessor 抛出的将会变成一个临时变量的地址——对,就是这个协程在非平衡栈里面分配的临时变量。要造成这个结果很简单:比如,把 os_unfair_lock 打包放入一个叫做 Data 的类型中,然后 var _lock: os_unfair_lock 改成 computed property,从 Data 中访存 os_unfair_lock:
我们可以看到,此时 UnfairLock._lock.modify 的 SILGen 结果中出现了栈分配(683 行),然后分配后的栈地址内又被 store(复制)了 UnfairLock._lock (687 行),随后栈分配后的地址被 _modify 抛出,尔后在 _modify 的 resumption 函数(bb1 和 bb2)中,栈地址中的内容又被重新 set 回了 UnfairLock._lock(694 行及 703 行)。

上面这种行为在多线程场景就是灾难性质的——因为每一个线程都有自己独立的执行栈,而这种行为就是把一个锁复制到了每一个在竞争这把锁的线程的执行栈上再加解锁——最后的结果一定是程序出错。
深入:理解取地址中的临时变量
要理解对 var 取地址时可能取到临时变量的地址,还是需要回到 Swift 对 var 关键字定义的变量的抽象:
- 一定包含一个
getaccessor - 可选包含一个
setaccessor - 可选包含一个存储容器
而编译器帮助合成 _read 或者 _modify 时,如果变量沒有实际存储容器,那么也只能通过 get 和 set 实现:当出现 computed property 时,其 _modify 会先通过 get accessor 创建一个临时变量,抛出临时变量地址之后,在 resumption 时再使用 set accessor 写回这种实现了。
所以,如果开发者书写如下代码:
那么实际上编译器会帮助合成并生成如下代码:
知道这一点之后,我们也可以尝试手写 UnfairLock._lock._modify 的实现,直接抛出 data.lock 的地址,来消除临时变量:
此时我们可以通过 SILGen 的结果看到:UnfairLock._lock.modify 目前会委托到 UnfairLock.data.modify(84 行),然后利用 UnfairLock.data.modify 的结果,然后取出 Data.lock 的地址(85 行),最后抛出(86 行):

而 UnfairLock.data.modify 则是直接抛出了 UnfairLock.data 在当前 self 下的地址(第 61 行)。

上述技巧绕过了「使用 var 关键字变量的 get 和 set」来实现 _modify,同时也产生了一个「副作用」。大家能想到是什么吗?
最佳实践及准入建设
在实际的日常开发活动中,我们并不想耗费如此多的心智在如何处理好给 unsafe pointers 传参上,所以我们需要一套最佳实践以及自动化准入机制来保证我们的日常开发的执行结果。
上述问题可以归结为:
- 对
Void取地址出现无意义数值 - 多线程使用
&对变量取地址后崩溃 - 对 computed property 取地址得到的是临时变量地址
下面我们分情况讨论
ObjC 关联对象访存出错
前文「ObjC 关联对象访存结果出错」的本质是:Swift 中对于空大小类型的全局变量取地址编译到 LLVM IR 后是 undef 的,编译为目标码之后的体现为一个根据之前代码执行结果产生的任意数值。所以「对大小为空的类型的全局变量取地址」本身就是一个未定义行为。这里的最佳实践就是不允许这样做。在准入建设方面,我们可以设立静态分析规则进行检出。依据公司现有静态分析设施,我们可以分析:1)标准库以及2)文件内定义的空大小类型,并且3)有选择地加入系统库的类型定义。
多线程下取地址崩溃
前文「多线程下对实例变量取地址发生崩溃」的本质是:Swift 中,在多个线程中对同一个变量获取「写访问」会引发「访问竞争」,这是 Swift 运行时在开启 runtime exclusivity enforcement 之后所不允许的。相关最佳实践应该是将「写访问」提出多线程代码:
比如下列代码通过 DispatchQueue.concurrentPerform 这个并发执行的接口,在多个线程中通过 & 取地址对同一个变量 counter 获取了「写访问」:
我们可以将相关代码提取出 DispatchQueue.concurrentPerform 的尾闭包:
但是上面是发生在极其局部的问题。泛化而言,面对运行时访问竞争,苹果使用 SIL 这种检测能力很强的静态检测手段亦无法检出,我们即可判断:对于运行时的行为,我们需要运行时的设施进行检测,所以我们需要研发流程和准入同时进行调整:
- 研发流程中加入研判是否需要设计多线程测试用例的步骤;如果需要设计,则需要单独在评审时提供多线程测试用例
- 准入调整为要求单元测试覆盖率 100%
- 准入调整为在 CI 单测流水线在 Xcode test plan 中开启 thread sanitizer,CI 消费 thread sanitizer 检出结果

取地址得到临时变量地址
前文「对变量取地址有可能取到临时地址」的本质是:Swift 中对 computed property 的默认实现取地址过程依赖 get 和 set 来分配临时变量,然后再通过 set 设置回去。其在多线程中产生的后果是:锁在各个线程的执行过程中被 get 多份至各线程的执行栈上;在普遍的代码中产生的后果是:取地址的结果不稳定。
所以这里最佳实践也应该分情况讨论:
- 对于使用锁的需求而言,苹果的思路是提供封装好的锁,而不是鼓励使用原始锁(如
os_unfair_lock或者pthread_mutex)。但是苹果在 iOS 16 才想起这件事,所以这里我们需要自行封装好没问题的锁,并且鼓励开发者只使用封装好的锁。
- 对于其他需求,这里最佳实践应该是:
- 禁用对
get/set实现的 computed property 取地址。 - 如果是对 stored property 取地址,也应该使用左值存储指针,而不是直接使用右值送参。且 stored property 及存储指针的左值的生命周期可以涵盖使用指针代码的生命周期——比如 stored property 及存储指针的左值是一个全局变量。
在准入方面,我们可以:
- 通过静态检测对「在 Swift 中使用原始锁」这种行为进行拦截,并不再鼓励直接使用原始锁(如
os_unfair_lock或者pthread_mutex);对自己开发水平自信的开发者依然可以使用原始锁,但是相关代码需要单独豁免。 - 通过静态检测对「Swift 中 & 取地址之后作为右值使用」这种行为进行拦截,拦截后建议修复为使用左值存储指针值后再使用
- 通过静态检测对「向 computed property 取地址」这种行为进行拦截。
总结
上述问题的本质、后果总结如下

上述最佳实践及处置手段总结如下:

作者介绍:
- 李禹龙,2020 年加入字节跳动,来自抖音 iOS 基础技术团队,专注 Swift 语言及 UI DSL 框架。