论文链接:https://www.vldb.org/pvldb/vol17/p3759-shi.pdf
引言
近年来 Spark 已经成为离线大数据处理引擎的事实标准,广泛用于数据仓库、数据湖、机器学习等领域。在字节跳动内部每天运行百万级别的 Spark 离线作业,Shuffle 量高达 500PB,CPU 资源需求达到千万级别。随着业务的快速发展,用户对计算资源的需求越来越大,除了增加物理资源之外,如何提高线上 Spark 作业的资源使用效率也是我们亟需解决的问题。

在对线上 Spark 作业做了统计分析发现作业的 CPU & Memory 利用率都低于 50%(利用率指作业实际使用的资源占实际申请资源的比例);作业的 Data Scan Time 加上 Shuffle Read Block Time 占据了整个运行时间的 45% 左右。从上述指标可以看出,线上 Spark 作业有非常大的资源优化空间,资源使用效率不高的原因主要有以下 3 个方面:
- Slow IO
Slow HDFS IO:离线数据存储在 HDFS 集群,经常会出现作业读取 HDFS 慢,导致 CPU/Memory 等待 IO 而处于空闲状态。
Slow Shuffle IO:线上部署了 External Shuffle Service(ESS),Shuffle 量非常大(每天超 500PB,一些作业达几百 TB), ESS 的稳定性是一个比较大的挑战,经常出现很高的 Shuffle Read Block Time 导致 CPU/Memroy 空闲,而且会有大量的 FetchFailure 导致 Stage 频繁 Retry 重算,也浪费了大量资源。
- 粗粒度的资源控制
资源申请:Spark 作业在运行过程中不同的 Stage 对资源的需求不一样,虽然 Spark 通过 Dynamic Resource Allocation (DRA) 提供了横向伸缩的能力,但是在纵向资源伸缩方面 Spark 提供的 ResourceProfile 方案并不成熟字节并未采取,导致大量作业运行不同的 Stage 的时候产生资源浪费的情况。
资源使用:Spark 引擎在一些算子的 Spill 策略上并不能很好的控制内存的使用,在一些场景下还会导致 OOM 问题,通过完善 Spill 策略合理利用磁盘可以降低运行中内存的使用,从而节省内存资源。
- 不合理的作业参数
字节内部 Spark 用户很多,每天运行的作业可以达到 180w+,通过手工调参的方式,一方面浪费测试资源以及人力成本,另一方面需要对 Spark 机制比较熟悉才能有比较好的效果,所以目前线上整体上存在很多不合理的作业参数,导致资源利用率低,或者 Shuffle 不稳定(AQE 相关参数不合理)。
针对以上问题字节跳动基础架构-基础技术-批式计算和应用研究中心团队与上海交通大学的数据通信与数据工程实验室合作,基于线上的实际情况从三个方面进行了系统性的优化,包括多机制的 Shuffle 优化(稳定资源 External Shuffle Service 增强、混部资源自研 Remote Shuffle Service)、细粒度的资源申请和运行时资源使用控制、规则+算法两个阶段的自动参数调优。经此优化后可以实现大规模上量 50万+ 作业,日均节省百万级 CPU 核、PB 级内存。
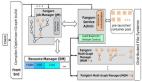
系统概览
我们提出了一套资源提效的治理框架,如下图所示在该框架中,贯穿整个 Spark 作业运行周期的优化包含如下三个方面,分别对应解决引言中的三个问题。

- Multi-Mechanism Shuffle Service
字节内部使用开源 ESS 承载作业 Shuffle,ESS 的机制需部署在 Spark 作业运行的计算资源节点上,在大规模以及复杂的计算资源类型的背景下,Shuffle 稳定性一直是个挑战。针对不同的计算资源类型,我们提出了不同的 Shuffle 优化方案,大大提升了 Shuffle 稳定性,减少了 Shuffle IO 等待导致的资源空闲以及 Stage 重算导致的资源浪费。
- Fine-Grained Resource Control
在 Spark 引擎层面提供了细粒度的资源申请和使用控制的优化,增加了相关配置参数,结合后续的自动调参,大大提升了资源利用率。
- Two-Stage Configuration Auto Tuning
我们针对周期性调度作业设计了基于规则和基于算法的两阶段自动调参系统,大大降低了人工调参成本,覆盖了线上大规模的作业,可以让作业快速收敛到合理的参数运行。
多机制 Shuffle 服务
在 K8s 统一资源池的背景下,字节内部逐渐下线 YARN,将 Spark 作业迁移到 K8s,如系统概览中的图所示,Spark 在 K8s 上的计算资源大体可以分为两大类:
- Dedicated Cluster
- 独占计算资源会挂载 SSD 作为 Shuffle 数据盘,磁盘能力(吞吐/ IOPS)比较强,提供给高优作业使用。
- Mixed Cluster
低优 Spark 作业也使用了很多混部资源,包括在离线混部/ HDFS 混部等,这些计算资源的磁盘能力相对比较差。
开源的 ESS 部署在上述两种类型的集群中,稳定性都遇到了非常大的挑战,特别是混部集群,为此我们一种多机制的 Shuffle Service 优化,针对不同类型的集群提供对应的解决方案。
Enhanced External Shuffle Service (ESS)
虽然 SSD 独占集群磁盘能力强,但是在大规模作业以及 Shuffle 量的背景下,ESS 稳定性依然受到很多挑战,为此我们进行了一系列优化。
Request Throttling
ESS 服务是被集群上运行的所有 Spark 共享,它在集群的每个节点上都部署了 Shuffle Service 服务进程,该服务进程面向该节点上运行的所有 Spark 作业提供 Shuffle Read 服务,所以个别异常作业就会影响整个集群的 Shuffle 稳定性。线上一般有两种异常情况的作业对 ESS 服务节点产生比较大的压力,主要有以下原因影响稳定性:
- Shuffle 规模本身很大的作业,会产生大量的 Chunk Fetch 请求;
- Shuffle 规模不大,但是相关参数不合理造成 Shuffle Read 阶段有大量的小于 20KB 的 Chunk Fetch 请求。
异常作业限流基于这些场景,避免异常作业影响整个集群的 Shuffle 稳定性。主要为以下功能:
- 每个 ESS 节点上会定期监控请求延迟,当延迟超过一定阈值后,该节点会开启 ESS 限流;
- 开启限流的节点将会定期监控节点上所有注册的 Shuffle 应用的 Fetch 请求量,当任何应用的请求量超过所分配的流量时,该应用将会受到限流;
- ESS 节点上的应用受到限流后,所允许堆积的请求量会有限制,如果该应用堆积的请求量超过阈值,则暂时不能发送新的 Fetch 请求。
Executor Rolling
我们从历史统计数据中观察到,Shuffle 读取速度慢与节点上写入的 Shuffle 数据量之间存在高度相关性。其中, Shuffle 写入量排名前五位的节点,这贡献了半数的 Shuffle 慢读取数量,而排名前两位的节点则占据了 35% 的慢读取。为了防止 Shuffle 数据集中在某些节点上,避免慢 Shuffle 读取,研发 Executor 滚动(Executor Rolling)策略,将 Shuffle 写入的数据更均匀地分布在集群中的节点上。主要功能如下:
- 在 Shuffle 过程中,记录每个 Executor 的 Shuffle 写入大小;
- 当某个 Executor 写入大小超过预定的阈值时,释放该 Executor 并请求新的 Executor;
- 同时调度器的调度策略也有助于更均匀地分配分配的容器。

Executor rolling 流程
Cloud Shuffle Service (CSS)
对于混合集群,开发了一种基于推送的远程 Shuffle 服务——CSS,它允许计算和存储解耦,从而消除混部集群中对本地磁盘的依赖,并提高了混合集群中 Shuffle 的可靠性。CSS 整体架构如下:

CSS 架构概览
- Cluster Manager 负责集群的资源分配,并维护集群 Worker 和 Application 状态,它可以通过 Zookeeper 或者本地磁盘保存这些信息,达到具有 High Availability 的服务。
- CSS Workers 支持两种写入模式,分别是磁盘模式和 HDFS 模式。目前常用的是磁盘模式,每个分区的数据会写入两个不同的 Worker 节点,以实现数据冗余。
- CSS Manager Client 位于 Spark driver 端 ,主要负责与 Cluster Manager 的心跳联系以及 Application Lifecycle。作业启动时,也会向 Cluster Manager 申请 Worker。Shuffle Stage 的过程也会统计 Shuffle Stage 的元数据以及 Shuffle 的进展。
- CSS Worker Client 是一个接入了 Spark Shuffle API 的组件,允许任何 Spark 作业可以直接使用 CSS 而无需额外配置。每个 Executor 会使用 ShuffleClient 进行读写。Shuffle Client 负责写入时候的双写,在读的时候,它可以向任何一个存有数据的 Worker 去读取这些数据,如果其中一个 Worker 读取失败的话,也会自动切换到另一个 Worker 上,并对多读的数据进行去重。
CSS 具有以下关键特性来提升性能和稳定性:
- Push Based Shuffle 模式将相同分区的数据推送到同一组工作节点,这些数据在刷新到磁盘前会与所有缓存在内存中的数据合并写入,从而允许 Shuffle Read 阶段对每个分区数据进行顺序读取;
- Partition Groups 功能允许将多个分区的 Shuffle 数据批量推送,从而减少 I/O 请求;
- 快速内存备份功能,通过内存双写与异步刷盘,以较低成本提高容错力,避免 Stage 失败带来的重试成本;
- 负载均衡功能,Cluster Manager 通过周期性收集的集群指标对 Worker 节点资源进行分配。
CSS 开源地址:https://github.com/bytedance/CloudShuffleService
细粒度资源控制
Spark 对于资源的分配(CPU、MEM)不够细致,使得资源利用率不够高,且容易出现 OOM。为此我们采取了一些措施提供细粒度的资源控制:
- 增加 Millicores 和 MemoryBurst 参数在配置阶段更细粒度的申请资源;
- 优化支持 Spill 的算子和 Spill 模式,减少内存无序争抢,利用集群的 Disk 资源。
Resource Allocation Control
字节内部的 Spark 作业,使用自研的 Yarn On Kubernetes 框架,综合考虑了云原生的趋势和稳定性的要求。该框架的资源调度协议保留了 Yarn 的协议,而在资源调度底层使用的 Kubernetes。为了提升 Spark 作业的资源利用率修改了Spark on Yarn 的参数与交互协议,从而支持细粒度的 CPU 和 Mem 配置。同时, 通过算子 Spill 增强 Spark 已有的内存管理模式。
CPU 资源控制
我们主要是通过在 Executor 内部 Task 运行并发度不变但是降低实际的 CPU 申请值的方式来提升 CPU 利用率。在开源社区版本的 Spark 中,spark.executor.cores 有两个含义,既代表 Executor 向资源调度系统(YARN,Kubernetes)申请的 Cores 数,同时也代表在 Executor 内部任务运行的并发度,一个 Task 运行至少需要 1 Core。我们在 Spark 中引入了一个新的参数——spark.executor.millicores,该参数被设置时实际创建的 Executor 的 CPU Request 会使用该参数的值,spark.executor.cores 只代表 Executor 中 Task 的并发度。为了保证作业的运行速度,在降低 CPU Request 的同时需要设置一个较大的 CPU Limit,但为了避免过高的超发,我们在实践中没有暴露参数给用户直接设置 CPU Limit,而是在不同的集群设置了各自的超发系数,默认情况下 Limit 会设置成 Request 的两倍。
Memory 资源控制
Spark Executor 使用的内存可以大致分成两部分:堆内内存和 Overhead,在默认的 onHeap 模式下,大部分的运行时使用的内存都在堆内,且这部分内存被 JVM 所管理,缺少弹性。调整堆内内存的风险很高,容易引发 OOM 异常。而 Overhead 的使用更灵活,调整 Overhead 的风险更低。我们新增了 spark.executor.memoryBurst.ratio 参数,允许 Spark 申请 Executor 时,按照该参数设置的比例降低 Overhead 内存的 Request 申请,Limit 保持不变。

资源控制示例
Resource Usage Control
Spark 对作业的内存管理比较粗糙,容器运行的时候多个算子尽可能将内存用满,只有当内存不足的时候才会触发 spill 操作,数据溢写到磁盘。这种无序的内存争抢是作业 OOM 的主要原因。而线上集群磁盘利用率并不高,完全有足够的空间支持把更多的数据溢写到磁盘。
为此,我们对 Spark 已有的内存管理模式做了改进,覆盖更多算子的 Spill,包括 UnsafeExternalSorter、HashAggregateExec。同样的,我们在 Spark 原有的 Force Spill by Number of Records 模式上,增加了多种算子级别的 Spill 模式:Force Spill by Memory used, Allow Spill by Memory used, Allow Spill by Fraction of memory used。
通过 Spill 机制的改进,我们可以精确控制 Spark Operators 使用的内存,从而确保内存的分配和释放更加高效。
两阶段自动调参
Spark 作业的配置参数对资源利用率有着显著影响。然而在生产环境中,对每个作业进行参数调优实验是不切实际的。因此我们专门为周期性作业建立了一套 Online Tuning Pipeline,充分利用运行时的指标数据。与预先调优参数不同,我们从默认或用户定义的参数(通常是次优的)开始,并记录每个作业的运行指标。随后对这些指标进行分析,以改进下一次作业执行的参数。为了实现在线调优的快速稳定收敛,我们开发了一种如下图所示的两阶段配置自动调优方法。第一阶段是基于规则的调优,利用由 Spark 专家手动编写的规则,从而避免了低效的探索。第二阶段是基于算法的调优,改进了贝叶斯优化算法以提高稳定性,旨在找到更优的参数,同时将生产环境中发生 OOM(内存不足)故障的概率降至最低。
Online Tuning Pipeline

上图展示了 Spark Tuning Framework 的工作流程与该框架包含的四个组件:
- Tunning API 控制器负责与数据平台和最终用户进行交互,记录每个任务的优化配置,供用户查询任务监控数据。
- JobAnalyzer 是一个 FlinkJob 消费 Spark 运行过程中的 Event log 数据以及调度系统的其他数据来实时生成任务的运行指标。
- Rule-Based Tuning:由若干启发式算法构成,输入作业的运行指标,该规则树会按照启发式规则在树中的关系最终生成推荐参数。
- Algorithm-Based Tuning:针对在线调参的安全性要求进行特别优化的贝叶斯优化算法,该算法根据历史参数的运行情况生成性能更优的推荐参数。
Rule-Based Tuning
每个任务通过聚合生成上一节所展示的指标后,我们就得到了一个任务大致的画像,例如这个任务有多少个 Task,输入了多少数据,平均和最大的 CPU 利用率如何等。我们依赖这些指标尝试使用启发式算法对作业的参数进行调优,在实践中由于针对启发式算法越来越多,我们使用了一个规则树来描述规则与规则之间的关系。
这些规则调整的参数可以分为三类:对于 CPU 和 内存来说,启发式规则最基本的方式可以描述为当平均利用率和最大利用率较低时,就在任务并发度不变的前提下降低对应的资源申请量,当利用率过高时,就增大对应资源的申请量;Shuffle 优化如上文所讲,导致 Shuffle 问题的主要原因是 ESS 存在大量的随机 IO,使用更优的参数可以有效的减少随机 IO 次数。启发式规则会观察作业每个 Stage 的 Partition 数量,当 Partition 数量远大于任务能申请到的 Core 的数量时,会被认为该并发度是不必要的。
Algorithm-Based Tuning
为了应对那些无法通过启发式规则调优有效优化的作业,我们开发了一种基于算法的调优方法,采用了贝叶斯优化算法。目标是找到能最小化参数评估函数的配置。为了提升利用率,评估指标 f(x) 定义成为 CPU 和内存利用率乘积的倒数。我们选择高斯过程 (GP) 作为目标函数的替代模型。


在这个模型中,Expected Improvement(EI) 通常被用作为采集函数。它衡量了未见参数 x, 可能带来的期望改进。作业下一次运行的推荐参数,x* 可以通过最小化采集函数获得。为了求解这个优化问题,我们使用遗传算法,以便对参数空间进行高效且有针对性的探索。


算法调优能够更高效且有针对性地探索参数空间,在提升 Spark 作业资源利用率的同时确保稳定性。符号说明如下:

实验及成果
这部分内容将从稳定性、性能和资源利用率的角度分析并回答以下问题:
- Shuffle 服务提升了多少性能?
- 资源控制如何帮助提高稳定性和利用率?
- 通过配置调优可以节省多少资源?
- 这些技术在生产环境中的优势是什么?
Enhanced ESS and CSS Evaluations
我们评估了多机制 Shuffle 服务带来的效果,包括通过生产工作负载评估增强型 ESS 的稳定性,以及使用 TPC-DS Benchmark 评估 CSS 的性能。
Enhanced ESS
Request Throttling 功能通过其在生产集群中的表现进行评估。下图展示了请求节流对在一段时间内向 ESS 节点发送大量 Shuffle 请求的作业的影响。当由于 Shuffle 请求数量增加导致 ESS 服务器的 Shuffle 延迟开始恶化时,请求节流对贡献最多 Shuffle 请求的作业生效,减少该作业发送的后续 Shuffle 请求数量。在几分钟内,ESS 能够完成其排队的请求处理,Shuffle 延迟很快恢复正常。

Executor Rolling 功能也在生产集群上进行了评估,比较了启动执行器滚动前后的磁盘使用情况。选择执行器滚动启动前的 2023 年 1 月的一天和启动后的 2024 年 1 月的一天的磁盘使用数据,如下图所示随着业务的增长,每台物理机上 Shuffle 的中位数磁盘使用量从 0.7TB 增加到 1.2TB,平均值从 1.8TB 增加到 2.6TB,而最大值从 48TB 降低到 23TB。第 99 百分位数略有下降。因此可以得出结论,启动执行器滚动后,磁盘使用更加均匀,避免了大量 Shuffle 数据写入少数执行器的情况。

CSS
本实验在一个 40 节点的集群上进行,该集群配备了 Intel Xeon Gold 6130 CPUs @ 2.10GHz、64GB * 16 的 DRAM、16 个 13TB 的 HDD 以及 2 个 25GB 的网络接口卡。
CSS 远程 Shuffle 集群部署在一个 9 节点的集群上,配备了 Intel Xeon Gold 6230 CPUs @ 2.10GHz、64GB * 16 的 DRAM、12 个 13TB 的 HDD 以及 2 个 25GB 的网络接口卡
以确保所有 Shuffle 服务从集群中获得类似的资源分配,实验也开启了 Spark Dynamic Executor Allocation,且作业 Executor 源配置相同。

我们用 1TB TPC-DS Benchmark 评估了三种 Shuffle 服务:ESS、Magnet(Spark 3.2 的 Push-based Shuffle 服务)和 CSS 的执行时间和资源利用率。如上图显示,CSS 在某些 SQL 查询中相比 ESS 和 Magnet 提高了超过 10% 的速度,在近 30% 的查询中观察到了显著的性能提升。下表显示 CSS 相对于 ESS 将总执行时间减少了 0.4 小时,相对于 Magnet 减少了 1.3 小时。此外,与 Magnet 和 CSS 相比,CPU 和内存的分配和使用显著减少。

CSS 通过在内存中缓存分区数据,并在超过块大小阈值时刷新数据块,从而优于 Magnet。此外,Magnet 相比 ESS 表现出性能下降,因为在合并结果接收和映射任务完成时的块合并过程中,Magnet 会增加额外的等待时间,这在处理较小的 Shuffle 数据量时尤其不利。
Resource Control Evaluations
我们也评估了细粒度资源控制的效果。然而,需要注意的是,这些功能的有效性依赖于配置参数的正确设置和调优。因此,优化结果是两阶段配置调优方法和这些功能的结合。这些功能提供了配置细粒度资源的能力,而两阶段配置调优方法则最大化了这些功能的优势。
Resource Allocation Control
在 milliCores 实施之前,通过 Shuffle 优化和规则配置调优,我们将约 240,000 个作业的平均 CPU 利用率提高到 56%。2023 年 8 月,我们引入 milliCores 并与参数调优一起发布。从 2023 年 7 月到 2024 年 2 月的一批生产作业,总数量从 21 万 增加到 36 万。与此同时,启用作业的数量从 0 增加到 35 万,平均 CPU 利用率上升至 94.8%。这表明 milliCores 在提高资源效率方面发挥了关键作用。

如下图所示,我们量化了 memoryBurst 实施带来的内存分配减少。该特性于 2023 年 10 月推出,此后启用作业的数量逐渐从 3000+ 增加到 47 万。到 2024 年 1 月底,实现了每天 55 PB·h 的内存分配节省。这些发现突显了 memoryBurst 特性在降低内存需求和节省资源方面的有效性。

Resource Usage Control
Spill 优化在生产作业中被广泛使用,我们分析了几个典型作业,以评估带来的改进:
- 数据仓库作业:在进行大量 Shuffle 写入操作的情况下,Spill 优化使分配的内存减少了 55%(从 3.2TB 降至 1.45TB),实际内存使用减少了 56%(从 1.21TB 降至 0.53TB)。
- 以 Shuffle Read 为主的作业:Spill 优化显著减少了阶段中的 OOM 任务数量,从 7000+ 减少到 27,同时执行时间从 29 分钟减少到 11 分钟。内存使用量显著下降 65%(从 23.1TB 降至 8.16TB)。
- Sort 作业:内存分配从 330TB 降至 214TB,实际内存使用从 300TB 降至 129TB,减少了 57%。作业持续时间保持相对稳定,从 2.1 小时变为 2.2 小时。磁盘溢出的触发机制从仅在内存达到满容量时触发,转变为一旦内存达到 1GB 阈值就定期触发。
Configuration Tuning Evaluations
基于规则和算法的参数调优方法都已在生产环境中部署。以下展示了各种调优方法相关的种资源利用分析结果,其中利用率是通过将总资源使用量除以总资源分配量来计算的。
Rule-Based Tuning
规则基础调优方法在整个在线过程中经过了多次迭代和优化
- 第一阶段 (2022 年 7 月)主要通过调整原有的 CPU 与内存参数来管理作业资源分配。CPU 利用率从 2023 年 3 月前的 51% 上升到 2023 年 3 月后的 59%,内存利用率从 43% 提升至 46%。
- 第二阶段和第三阶段(2023 年 8 月和 2023 年 10 月)中,随着 milliCores 和 memoryBurst 的实施与调整,CPU 和内存利用率显著提升,且调优作业数量增加。随着规则的优化,所有调优作业的 CPU 利用率达到了 90%,内存利用率达到了 52%,涵盖了近三分之一的生产作业,并带来了显著的改进。

Algorithm-Based Tuning
算法调优方法在生产环境中是作为 Rule-based 调优的补充。对于一些在线 Spark 作业,出于稳定性考虑,可能不会进行规则基础调优,或者规则可能未涵盖当前作业的状态,因此作业可能未得到调优或调优效果不显著。在这种情况下,这些作业会转交给算法基础调优,以进一步提高资源利用率。
下图展示了由算法基础调优调整的作业的在线性能。从 2023 年 12 月末起,算法基础调优接管了约 3000 个作业。在算法介入之前,这批作业的利用率较低,平均 CPU 和内存利用率分别徘徊在 31% 和 21% 左右。经过算法调优后,这些作业的 CPU 和内存利用率逐渐提高,最终稳定在 58% 和 45% 左右。

Two-Stage Tuning
下图展示了一个项目中所有作业的利用率变化,约 5% 的作业在 2023 年 12 月之后由算法调优接管。因此,曲线前半部分表示项目仅使用规则调优的结果,而后半部分则表示规则两种调优结合的结果。可以观察到,在仅使用规则调优和采用两阶段组合的情况下,CPU 利用率变化不大,因为这批作业在使用规则调优时已经具有较高的 CPU 利用率。然而在内存利用率方面,前者约为 21%,而后者约为 26%,有显著的改进。这是因为这 5% 的作业内存使用比例相对较高,经过算法进一步优化后,内存利用率显著提升。
算法调优可以进一步提升规则调优获得的结果。然而,由于其时间消耗大且调优速度较慢,算法基础调优需要与规则基础调优结合使用,以在生产环境中实现更好的效果。

Overall Tuning Performance
本文提出的技术经过了广泛的迭代、优化和部署。我们将通过两年的数据对这些技术在提升字节跳动大规模 Spark 工作负载资源效率方面的效果进行了统计分析。

上图展示了 2022 年至 2023 年所有 Spark 作业资源效率的提升情况。总体提升情况如下:
- 在 CPU 利用率方面,通过规则配置调优的迭代优化,利用率从 2022 年的 48% 提升到 2023 年的 60%,随后随着 milliCores 特性的引入,利用率进一步上升到超过 70%;
- 内存利用率通过规则配置调优从 2022 年的 43.3% 提高到 46%,并通过 memoryBurst 特性进一步提升至接近 50%;
- Shuffle 方面,Shuffle Block Ratio,表示等待 Shuffle 的时间比例,最初在 2022 年 1 月约为 14%,通过 Enhanced ESS 和 CSS 在 Shuffle 速度和稳定性方面的增强减少到约 4%-6%,随后通过参数调优进一步降低至 2%。
整体上,我们服务的用户数量从 9000+ 增加到 1.4 万,优化的作业数量从 25 万激增至 53 万。相应地,CPU 利用率超过 60% 的作业的日均数量从 2023 年 3 月的 15 万 增加到 2024 年 2 月的 30 万 以上,而内存利用率超过 50% 的作业也达到了约 15 万。CPU 和内存资源分配的日均节省峰值分别达到 100 万 核/日和 4.6 PB/日。此外,作业执行时间也显著减少,在 2024 年 2 月减少了约 11 分钟,占此前平均作业执行时间的 31%。
作者介绍:
- 程航,毕业于新加坡国立大学,21年加入字节,现任字节跳动大数据开发工程师,专注大数据分布式计算领域,主要负责 Spark 内核开发及字节自研 Shuffle Service 开发,现主要负责分布式机器学习框架相关的开发。
- 魏中佳,毕业于电子科技大学,18年加入字节,现任字节跳动大数据开发工程师,专注大数据分布式计算领域,主要负责 Spark 内核开发及字节自研 Shuffle Service 开发,现主要负责数据湖相关的开发。