













在实际工作中,我们经常会用到通知系统,比如,用户完成在线购买后,需要发送订单确认邮件、支付处理成功的短信以及包裹发货的推送通知。那么,什么是通知系统?如何设计一个通知系统?这篇文章,我们来聊一聊!

需求收集
在设计之前,我们先来详细了解下通知系统的需求,本文从功能需求和非功能需求两个方面来介绍。
1.功能需求
- 通知类型:例如消息通知、警告通知、活动通知等。
- 用户群体:需要通知的用户群体是谁,是否有分组。
- 通知渠道:例如邮件、短信、推送通知、应用内通知等。
- 通知频率:通知的发送频率和限流策略。
- 优先级:不同通知的优先级管理。
- 用户偏好:用户是否可以自定义接收通知的偏好。
- 重试机制:处理通知发送失败的情况,必要时重试(如短信或电子邮件发送失败)。
2.非功能需求
- 可扩展性:系统应能够每分钟处理数百万条通知,支持数百万并发用户。
- 高可用性:确保最小的停机时间,即使在故障情况下也能发送通知。
- 可靠性:保证至少一次的通知传递,对于某些使用场景可能需要保证只有一次传递。
- 低延迟:通知应尽快发送,以确保及时交付。
容量预估
在深入设计之前,让我们先估算下系统规模以更好地做出设计决策。假设系统服务于 1000万日活用户,每个用户平均每天接收 5条通知。
1.峰值负载
假设在峰值时间内(如秒杀期间)1分钟内发送 100万条通知,这意味着系统应能够处理:
- 每天的通知数量:10,000,000 x 5 = 50,000,000条通知
- 峰值每秒通知数量:1,000,000 / 60 = ~17,000条通知/秒
2.存储需求
假设每条通知的数据量大小是 1KB,则存储容量评估为:
- 用户数据存储需求:10,000,000 * 1 KB = 10GB
- 每日通知存储需求:10,000,000 * 5 * 1 KB = 50GB
High-level 设计
从 High-level 层面来看,通知系统将包括以下组件:
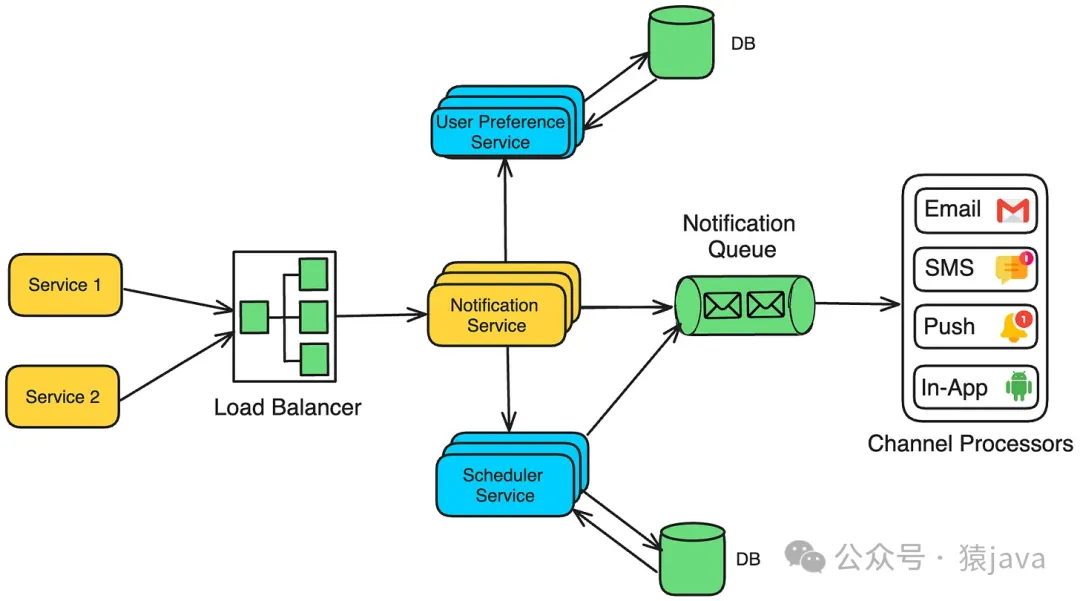
(1) 通知服务(Notification Service)
通知服务是所有通知请求的入口,无论是来自外部应用程序还是内部系统。它暴露的API可以供各种客户端调用以触发通知。
这些请求可以是发送事务性通知(如密码重置邮件)、促销通知(如折扣优惠)或系统警报(如停机警告)。
每个请求都被验证以确保其包含所有必要的信息,如接收者ID、通知类型、消息内容以及应通过哪些渠道发送通知(电子邮件、短信等)。
对于需要在未来日期或时间发送的通知,通知服务与调度服务(Scheduler Service)集成。
处理请求后,通知服务将通知推送到通知队列(如 Kafka或 RabbitMQ)。
(2) 用户偏好服务
用户偏好服务允许用户控制如何接收通知。
它存储和检索用户接收不同渠道通知的个人偏好。
服务跟踪用户明确选择加入或退出的通知类型。
例如:用户可以选择退出营销或促销内容。
为防止用户被通知淹没,用户偏好服务对某些类型的通知(尤其是促销消息)实施频率限制。
例如:用户每天只能接收2条促销通知。
(3) 调度服务
调度服务负责存储和跟踪定时通知——那些需要在特定未来时间发送的通知。
这些可以包括提醒、促销活动或其他不立即发送但必须基于预定时间触发的时间敏感通知。
例如:促销消息可能计划在下周发送。
一旦到达预定时间,调度服务将从其存储中提取通知并将其发送到通知队列。
(4) 通知队列
通知队列在通知服务和渠道处理器之间充当缓冲区。
通过将通知请求提交与通知发送解耦,队列使系统能够更有效地扩展,尤其是在高流量期间。
队列系统提供消息传递的保证。
根据使用场景,可以配置为:
- 至少一次传递:确保每条通知至少发送一次,即使这在罕见情况下会导致重复消息。
- 只有一次传递:确保每条通知只发送一次,防止重复,同时保持可靠性。
(5) 渠道处理器
渠道处理器负责从通知队列中提取通知并通过特定渠道(如电子邮件、短信、推送通知和应用内通知)发送给用户。
通过将通知服务与实际发送解耦,渠道处理器实现了独立扩展和异步处理通知。
这种设置允许每个处理器专注于其指定的渠道,确保可靠的发送,并内置重试机制和高效处理故障。
(6) 数据库/存储
数据库/存储层管理大量数据,包括通知内容、用户偏好、定时通知、发送日志和元数据。
系统需要混合存储解决方案来支持不同需求:
- 事务性数据:使用关系数据库(如 PostgreSQL或 MySQL)存储结构化数据,如通知日志和发送状态。
- 用户偏好:使用NoSQL数据库(如 MongoDB)存储大量用户特定数据,如偏好和限速。
- Blob存储:对于包含大附件的通知(如带图片或 PDF的电子邮件),使用 OSS,Amazon S3或类似服务存储这些附件。
Low-level设计
设计完 High-level,我们将进入更详细的 Low-level 设计层面,主要包含以下步骤:
步骤1:通知请求创建
首先,通知系统的调用方(如电商平台、或营销系统等)需要生成通知请求。
请求的消息结构如示例请求:
步骤2:通知服务接收
当调用方发出请求后,通知服务(通过API网关/负载均衡器)会接收到通知请求。请求经过身份验证和验证,确保其来自授权来源,并包含所有必要信息(接收者、消息、渠道等)。
步骤3:获取用户偏好
通知服务会查询用户的一些偏好服务,这部分带有一些定制化的功能,可以根据实际情况决定是否需要此部分:
- 偏好的通知渠道(如某些用户可能偏好通过电子邮件接收促销消息,但通过短信接收关键警报)。
- 选择加入/退出偏好:确保符合用户偏好,如用户选择退出营销邮件。
- 限速:确保用户没有超过其配置的通知限制(如每天最多3条促销短信)。
步骤4:定时发送
如果通知计划需要在未来的某个时刻(例如:每分钟或基于更细粒度的间隔))发送,通知服务将通知发送到调度服务,后者将通知及其预定发送时间存储在基于时间的数据库或允许基于时间高效查询的 NoSQL数据库中。
调度服务需要定时功能,当到达预定时间时,调度服务将通知发送到通知队列。
步骤5:将通知放入队列
一旦通知服务创建并格式化了所需渠道的消息,它将每个消息放入通知队列系统中的相应主题(如Kafka、RocketMQ等)。
每个渠道(电子邮件、短信、推送等)都有自己的专用主题,确保消息由相关的渠道处理器独立处理。
例如:如果通知需要通过电子邮件、短信和推送发送,通知服务将生成三条消息,每条消息都针对相应的渠道进行定制。
- 电子邮件消息放入电子邮件主题。
- 短信消息放入短信主题。
- 推送通知消息放入推送主题。
这些主题允许每个渠道处理器专注于消费其相关的消息,减少复杂性并提高处理效率。
每条消息包含通知负载、渠道特定信息和元数据(如优先级和重试计数)。
步骤6:渠道特定的消息处理
通知队列存储消息,直到相关的渠道处理器拉取它们进行处理。
每个渠道处理器作为队列的消费者,负责消费自己的消息:
- 电子邮件处理器从电子邮件主题拉取消息。
- 短信处理器从短信主题拉取消息。
- 推送处理器从推送主题拉取消息。
- 应用内处理器从应用内主题拉取消息。
步骤7:发送通知
每个渠道处理器负责通过指定的渠道发送通知:
电子邮件处理器:
- 连接到电子邮件提供商(如SendGrid、Mailgun、Amazon SES)。
- 发送电子邮件,确保其符合用户偏好(如HTML或纯文本)。
- 处理错误如退信或无效的电子邮件地址。
短信处理器:
- 连接到短信提供商(如Twilio、Nexmo)。
- 发送短信,并进行任何格式调整以满足字符限制或区域要求。
- 处理问题如无效的电话号码或网络错误。
推送通知处理器:
- 使用服务如Firebase Cloud Messaging(FCM)用于Android或Apple Push Notification Service(APNs)用于iOS。
- 发送推送通知,包括任何元数据(如应用程序特定的操作或图标)。
- 处理失败如过期的设备令牌或离线设备。
应用内通知处理器:
- 通过WebSockets或长轮询将应用内通知发送到用户的活动会话。
- 格式化消息以在应用程序的UI中显示,遵循任何应用程序特定的显示规则。
步骤8:监控和发送确认
每个渠道处理器等待来自外部提供商的确认:
- 成功:消息已发送。
- 失败:消息发送失败(如网络问题、无效地址)。
渠道处理器将每条通知的状态记录在通知日志表中,以供将来参考、审核和报告。
关键问题和瓶颈
1.故障和重试
如果通知发送由于临时问题(如第三方提供商停机)而失败,渠道处理器将尝试重发通知。
- 通常使用指数退避策略,每次重试的延迟时间逐渐增加。
- 如果通知在设定次数的重试后仍未发送成功,则将其移动到死信队列(DLQ)以进一步处理。
- 管理员可以手动审核和重新处理死信队列中的消息。
2.可扩展性
(1) 水平扩展
系统应设计为水平扩展,意味着组件可以通过增加实例来应对负载增加。
- 通知服务:随着请求量的增加,可以部署更多实例来管理增加的通知请求量。
- 通知队列:分布式队列系统(如Kafka或RabbitMQ)天然具有可扩展性,可以通过将队列分布在多个节点上来处理更大的工作量。
- 渠道处理器:每个处理器(电子邮件、短信等)应水平扩展以处理大量通知。
(2) 分片和分区
为了高效处理大量数据,特别是用户数据和通知日志,分片和分区将负载分布在多个数据库或地理区域:
- 基于用户的分片:根据地理位置或用户ID将用户分布在不同的数据库或区域,以平衡负载。
- 基于时间的分区:将通知日志组织成基于时间的分区(如每日或每月),以提高查询性能并管理大量历史数据。
(3) 缓存
使用Redis或Memcached等解决方案实现缓存,以存储频繁访问的数据,如用户偏好。
缓存减少数据库负载,并通过避免重复的数据库查询来提高实时通知的响应时间。
3.可靠性
为了高可用性,数据(如用户偏好、日志)应在多个数据中心或区域之间复制。这确保即使一个区域故障,数据在其他地方仍然可用。
多AZ复制:在多个可用区存储数据,以提供冗余。
使用负载均衡器将传入流量均匀分布在通知服务的各个实例之间,确保没有单个实例成为瓶颈。
4.监控和日志记录
为了确保系统在大规模下的平稳运行,系统应具备:
- 集中式日志记录:使用ELK Stack或Prometheus/Grafana等工具收集各种组件的日志并监控系统健康。
- 警报:设置警报以监控故障(如通知发送失败率超过阈值)。
- 指标:跟踪每个渠道的成功率、失败率、发送延迟和吞吐量等指标。
5.安全性
对所有传入通知服务的请求实施强认证(如OAuth 2.0)。使用基于角色的访问控制(RBAC)限制对关键服务的访问。
通过在API网关上实施速率限制保护服务免受滥用,防止DoS攻击。
6.归档旧数据
由于通知系统随着时间的推移会处理大量数据,实施归档旧数据的策略非常重要。
归档涉及将过时或不常访问的数据(如旧的发送日志、通知内容和用户历史记录)从主存储移动到成本较低、长期存储解决方案。
这样可以减少主存储的负载并提高系统的整体性能。
总结
这篇文章,我们从需求分析出发,再到宏观层面的设计,最后到详细的设计,通过本文详细地分析了,我们不仅能够学到如何设计一个可扩展的通知服务,同时我们还能通过通知服务的设计更好去理解系统设计的思路。














