













今天给大家分享机器学习中常用的评估指标。

评估指标是用来衡量机器学习模型性能的量化标准,它们帮助我们理解模型在特定任务中的表现。
不同的机器学习任务(如分类、回归)需要不同的评估指标。通过这些指标,我们可以判断模型的优劣,优化模型的性能,并在不同模型之间进行比较。
分类任务中的评估指标
1.混淆矩阵
混淆矩阵(Confusion Matrix)是用于评估分类模型性能的工具,特别是在二分类和多分类任务中广泛使用。
它能够显示模型的分类结果与实际情况的详细对比,帮助我们更清晰地理解模型的错误类型和分类的准确性。
混淆矩阵是一个 n×n 的矩阵,n 是类别的数量。对于二分类问题,混淆矩阵是一个 的矩阵,表示模型在不同分类结果上的表现。

- 真阳类(True Positive, TP):模型正确预测为正类的数量。
- 真阴类(True Negative, TN):模型正确预测为负类的数量。
- 假阳性 (False Positive, FP):模型错误预测为正类的负类样本数量(也称为Type I错误)。
- 假阴性(False Negative, FN):模型错误预测为负类的正类样本数量(也称为Type II错误)。
2.准确率(Accuracy)
准确率是正确分类的样本数占总样本数的比例。
其公式为
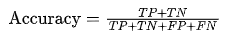
适用场景:适用于类别分布平衡的情况。但对于类别不平衡的问题,准确率可能不够准确。
3.精确率(Precision)
精确率表示模型预测为正例的样本中,实际为正例的比例。
其公式为:

适用场景:当关注假正例(FP)影响时,精确率是一个重要的评估指标,如在垃圾邮件过滤中。
4.召回率(Recall)
召回率表示所有实际为正例的样本中,模型正确识别出来的比例。
其公式为
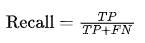
适用场景:当需要尽可能找到所有的正例时(如疾病检测),召回率是关键指标。
5.F1 值(F1-Score)
F1 值是精确率和召回率的调和平均数,用于权衡精确率和召回率之间的关系。
其公式为:
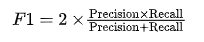
适用场景:当精确率和召回率同等重要时,F1 值是很好的评估标准。
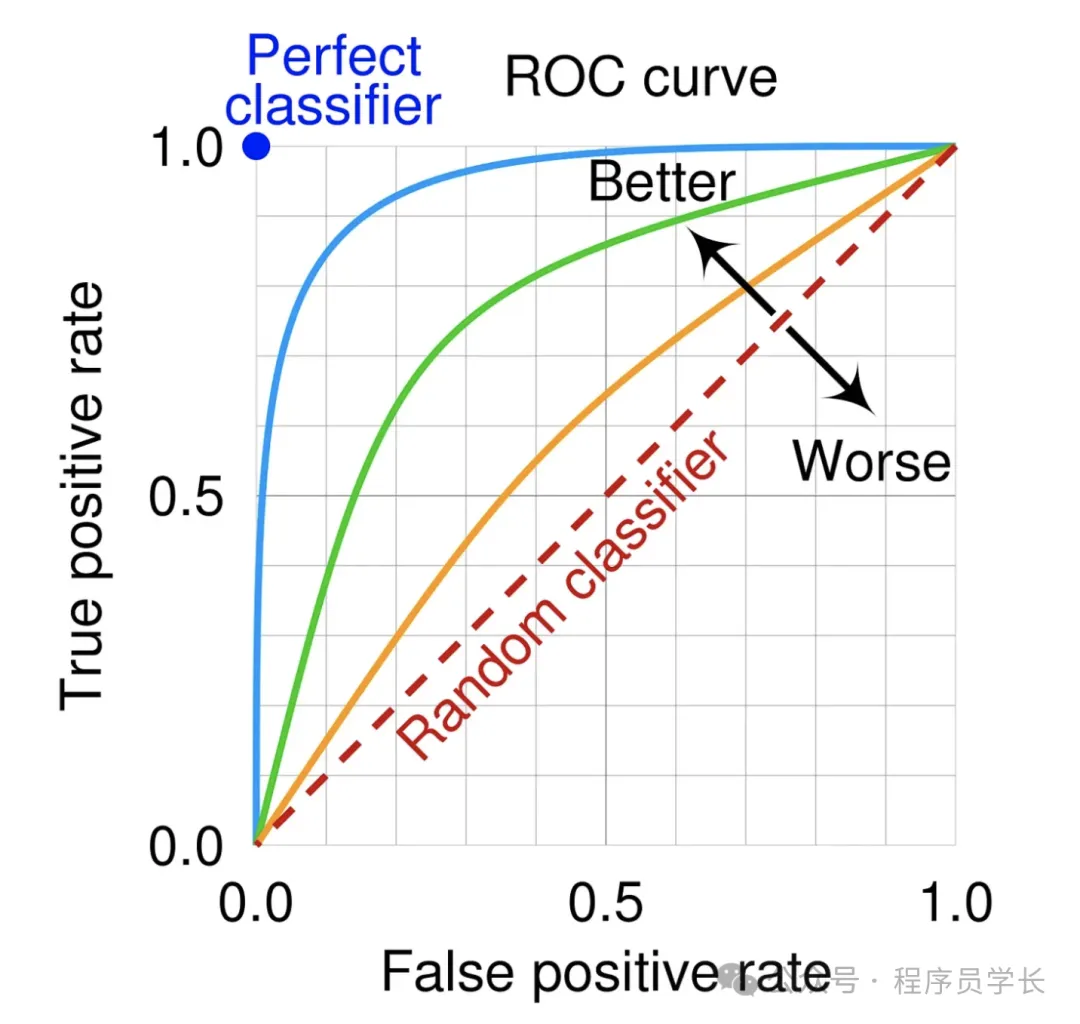
6.ROC 曲线和 AUC 值
ROC 曲线展示了分类器的假阳性率(FPR)与真阳性率(TPR)之间的关系。

AUC 值表示 ROC 曲线下面积,AUC 值越大,模型性能越好。AUC 值在0.5到1之间,接近1表示模型性能优异。
适用场景:适用于类别不平衡的分类任务。
回归问题中的评估指标
1.均方误差(MSE)
MSE 是模型预测值与真实值差的平方的平均值。它强调大的误差。
公式:
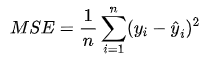
适用场景:适用于回归任务中,尤其是对大的预测误差更加敏感的场景。
2.均方根误差(RMSE)
RMSE 是 MSE 的平方根,用于将误差带回与原始目标变量相同的量纲。
公式:
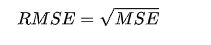
适用场景:与 MSE 类似,但 RMSE 更直观,误差与目标变量的尺度一致。
3.平均绝对误差(MAE)
MAE 是预测值与真实值的绝对差的平均值,较少受大误差的影响。
公式:
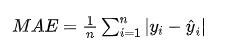
适用场景:当对所有误差的权重一致,且不希望夸大大误差影响时,MAE 是较好的指标。
4.R 方值(R²)
R² 衡量模型解释了多少比例的目标变量方差,其值介于0到1之间。
公式:
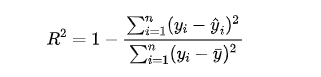
其中, 是目标变量的平均值。
适用场景:用于评估回归模型的解释能力。
5.调整 R 方值(Adjusted R²)
在考虑特征数量时,调整后的 R² 对多特征模型的评价更加准确。
公式:
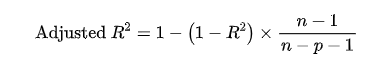
其中, 是模型中的特征数量。
适用场景:在特征数较多时,调整 R² 比普通 R² 更合理。































