Hello folks,我是 Luga,今天我们继续来聊一下人工智能生态相关技术 - 用于加速构建 AI 核心算力的 GPU 硬件技术。
随着人工智能、渲染、仿真技术以及支持高动态范围(HDR)的 4K 显示器逐渐进入主流市场,GPU(图形处理单元)的内存需求也在迅速增长。这一需求的增加源自多个方面,包括更复杂和庞大的模型与数据集、多任务工作流程、多个显示器上显示的高分辨率内容以及团队协作等因素。
在现代专业工作环境中,GPU 内存的重要性比以往任何时候都更为突出。尤其是工程、设计、影视制作和科学计算等领域的工作流程,对大容量 GPU内存的依赖不断增加……

什么是 CPU 内存 ?
GPU 内存是 GPU 上的专用内存,主要用于存储临时数据缓冲区。这些缓冲区在 GPU 执行复杂数学运算、图形渲染和视觉数据处理时起着关键作用。通常而言,执行特定指令前,GPU 通常需要在内存中存储大量数据,包括几何信息、纹理数据和计算参数。高效的数据存储与管理是 GPU 快速处理任务的核心。
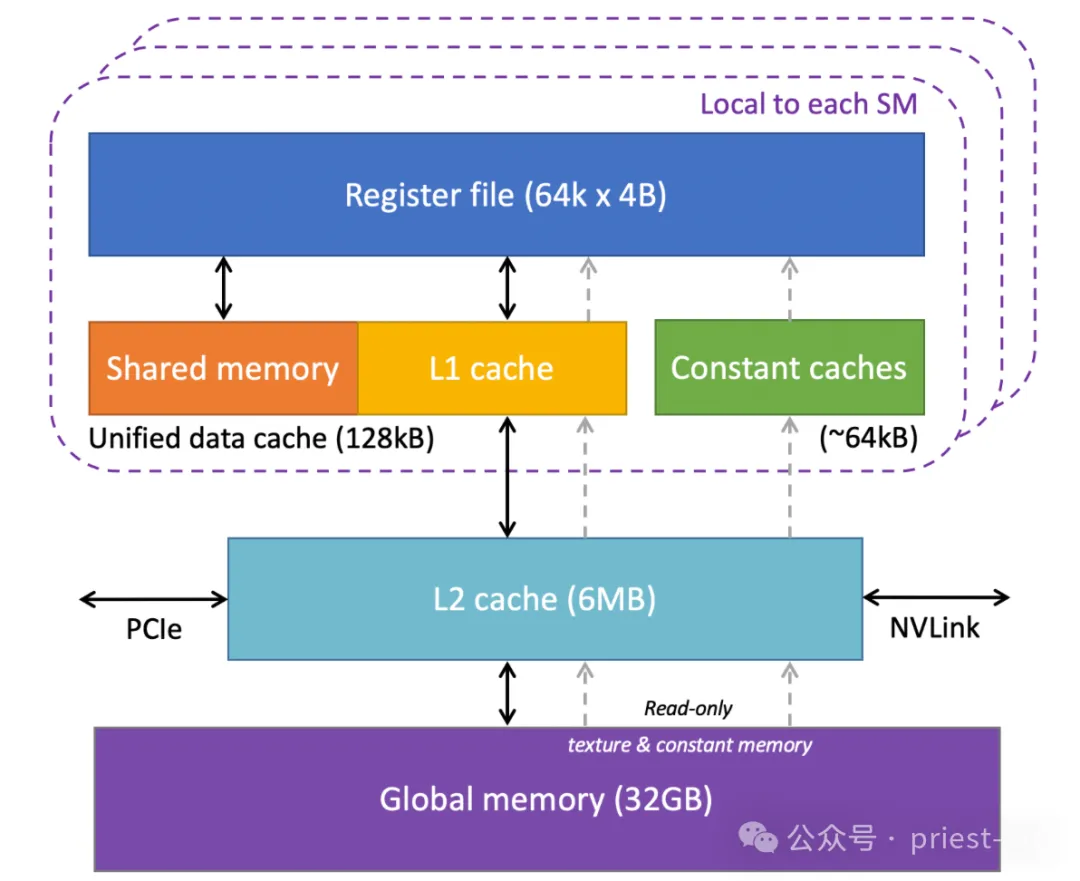
NVIDIA Tesla V100 GPU 内存结构
在实际应用场景中,系统通常需要将大量小型数据包从 CPU 或全局内存传输到 GPU 内存进行处理。如果 GPU 内存资源不足,数据传输频率和处理速度会受到影响,导致性能瓶颈和延迟。这种情况尤其常见于高分辨率图像处理、3D 建模和复杂的实时渲染任务。
值得注意的是,GPU 内存是独立于系统 RAM 的专用内存空间,专为图形和计算任务优化。它在快速存储和访问数据中扮演着重要角色,尤其是在高性能计算和实时应用中,对整体计算效率和响应速度有直接影响。
有时,在处理人工智能(AI)和机器学习(ML)模型等需要大量数据的复杂工作负载时, GPU 内存的使用要求常被低估。AI/ML 模型通常需要处理庞大数据集和复杂算法,此时内存资源的有效利用至关重要。GPU 内存的使用效率和带宽常是影响系统性能的关键瓶颈之一。
对于这些高强度计算任务,GPU 不仅需要大容量内存来存储数据,还需要足够的内存带宽以确保数据在处理器与内存间的高速传输。因此,内存容量和带宽在处理 AI、深度学习模型及其他繁重工作负载时至关重要。随着技术的发展,工作负载对 GPU 内存的需求持续增长,这强调了在设计和使用 GPU 时充分考虑内存资源分配和管理的重要性。
常见的 GPU 内存解析
在云计算体系中,“内存”作为硬件系统的基石,为各类应用提供了存储和处理数据的空间。从庞大的数据中心到微小的嵌入式系统,内存的性能直接影响着整个系统的响应速度和处理能力。无论是大数据分析中海量数据的快速处理,人工智能模型的实时训练和推理,还是物联网设备对实时性的严苛要求,高效的内存利用都是提升系统性能的关键。
通常而言,在 GPU 内存体系中,不同类型的内存具有各自的特性和适用场景。合理地选择和利用这些内存类型,对于提升应用程序的性能至关重要。
在深入研究 GPU 中的各种内存类型之前,首先需要明确内存的基本分类。通常,在讨论内存时,我们会将其分为两种主要类型:物理内存和逻辑内存。这一区分在理解 GPU 内存架构以及如何优化其使用时至关重要。
1. 物理内存
通常指的是实际存在于硬件中的内存,包括显卡上的 VRAM(视频随机存取存储器)以及其他存储组件。这种内存是真实存在的硬件资源,决定了 GPU 能够直接存储和访问数据的容量。物理内存的大小直接影响了 GPU 在处理大量数据时的能力,尤其是在运行复杂的图形任务、训练深度学习模型或者执行大规模计算时,物理内存的容量越大, GPU 能够处理的数据集就越大,从而减少内存溢出和性能瓶颈的发生。
2. 逻辑内存
逻辑内存则是从编程和软件层面上定义的内存。它并不与物理内存一一对应,而是通过抽象层次为开发者提供了一种管理内存资源的方式。在 GPU 编程中,逻辑内存的概念包括不同类型的存储区域,例如寄存器、共享内存、全局内存和本地内存等。每种逻辑内存有着不同的访问速度、容量和适用场景,开发者在编写代码时需要根据具体任务和需求,合理选择和管理这些逻辑内存,以最大化性能。
这种对内存的划分帮助我们在理解 GPU 工作机制时,明确硬件资源和软件管理之间的区别。物理内存提供了硬件层面的基础,而逻辑内存则通过编程模型来合理管理和调度这些资源。优化应用程序的性能往往需要充分理解这两者之间的关系,确保物理内存得到高效利用,同时最大限度地发挥逻辑内存的优势,避免资源浪费和性能瓶颈。
接下来,我们先来看一下 GPU 的逻辑内存架构图,具体可参考如下所示:
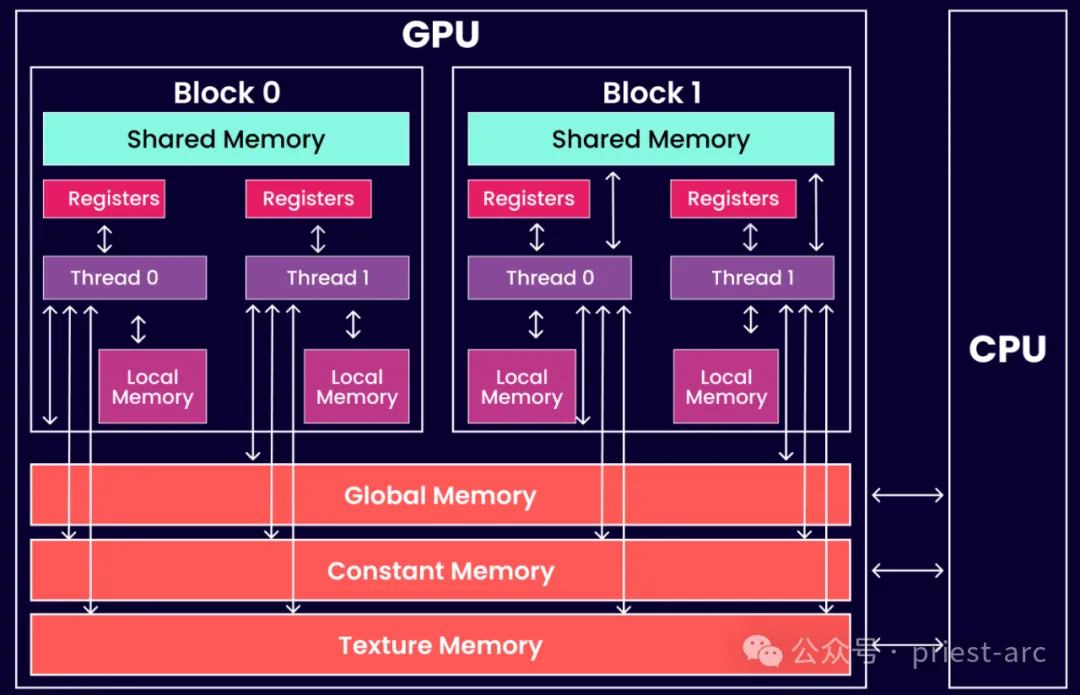
(1) 共享 GPU 内存
当 GPU 的 VRAM(视频内存)不足时,系统会调用另一种内存类型来补充。这种内存类型通常是指共享内存(Shared Memory),在 CUDA 编程模型中发挥着重要作用。多个线程可以在同一 GPU 块中共享这些 CUDA 内存空间,从而在处理资源密集型任务时提高效率。
共享内存的特点是其生命周期与创建它的块(Block)相同,也就是说,一旦该块结束执行,分配给共享内存的数据也会被释放。
共享内存的主要优势在于:提供了一种比全局内存更快的访问方式,允许同一线程块中的多个线程同时访问和共享数据,而不必每次都通过较慢的全局内存传输。这种机制在处理大量数据时,能够极大地减少内存访问延迟,从而提升整体计算效率。因此,在并行计算和资源密集型任务(如科学计算、图像处理和机器学习)中,共享内存的合理利用可以显著加快计算速度。
然而,GPU 的共享内存是有限的资源,且通常分配给每个线程块的共享内存量是固定的。这意味着,开发者在编写 CUDA 程序时,必须仔细规划内存的分配和使用,以避免超出共享内存的容量限制。如果任务需要的内存超过了共享内存的容量,GPU 就不得不依赖速度较慢的全局内存,可能导致性能下降。
(2) 注册 GPU 内存
在大多数情况下,访问寄存器的指令不消耗时钟周期。然而,读后写依赖关系和银行冲突可能导致延迟。具体而言,写后依赖项的读后延迟大约为 24 个时钟周期。对于配备 32 个内核的较新 CUDA 设备来说,可能需要多达 768 个线程才能完全隐藏这种延迟。
除了读写延迟之外,寄存器压力也会严重影响应用程序性能。当任务所需的寄存器不足时,就会发生寄存器压力。这种情况下,数据将“溢出”到本地内存中进行存储,从而导致性能下降。
有效管理寄存器使用对于优化 CUDA 应用程序的性能至关重要。通过仔细分配线程和优化内存访问模式,可以减轻这些潜在的性能瓶颈。
(3) 本地 GPU 内存
本地 GPU 内存是由操作系统内核分配的静态内存,在 CUDA 编程中,此类内存被视为线程的本地内存。每个线程只能访问其自身分配的本地内存。这种内存访问速度较慢,因为它通过寄存器或共享内存进行操作,效率不如直接使用寄存器。
在实际应用中,本地内存的使用会导致性能下降,尤其是在需要频繁数据访问的情况下。因此,在 CUDA 编程中,优化内存使用、尽量减少对本地内存的依赖,对于提升程序执行效率至关重要。
当然,我们也可以将上述内存划分为其他形式,比如,纹理内存(Texture Memory)、常量内存(Constant Memory)以及其他内存等。
而对于 GPU 的物理内存架构图,可参考如下:
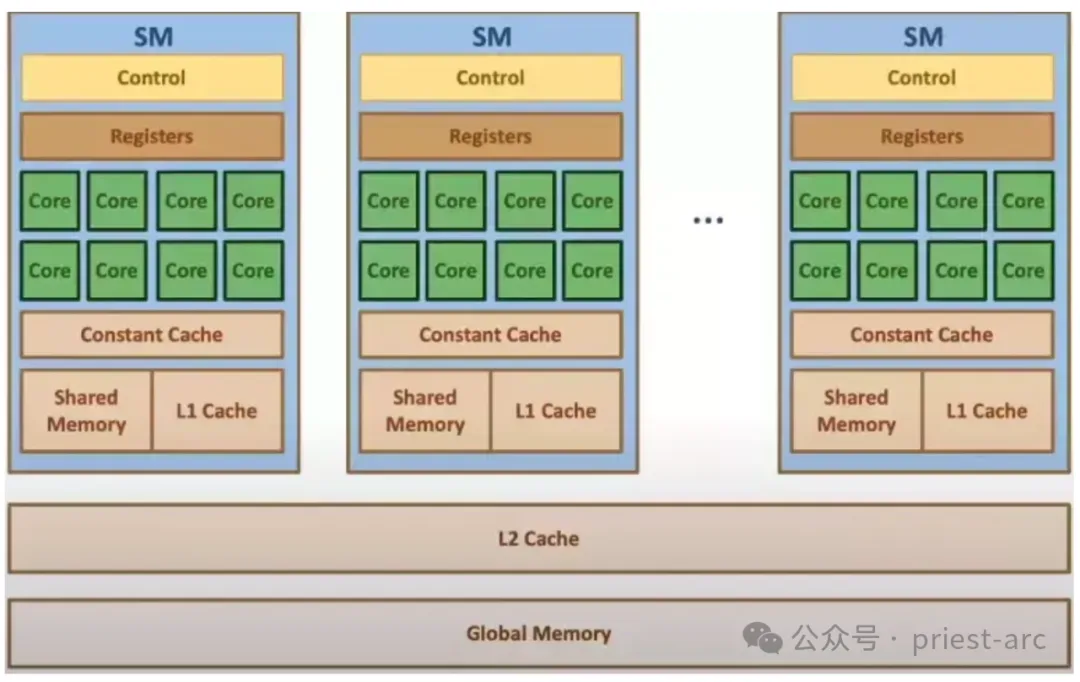
上述架构图所述与块和线程的关系非常相似,但在这里我们讨论的是流式多处理器(SM)和流式处理器(SP)。每个 SM 都拥有自己独立的共享内存、缓存、常量内存和寄存器资源,这些资源仅供该 SM 内部的线程使用。然而,所有 SM 之间共享相同的全局内存资源,所有线程都可以访问该内存。
GPU 内存常用场景解析
在 GPU 中,内存带宽是决定其在处理内核和内存之间数据传输速度的关键因素。内存带宽可以通过两种主要方式来衡量:一是内存与计算内核之间的数据传输速度,二是连接这两者之间的总线数量和带宽。
内存带宽对 GPU 的性能有着深远的影响,直接影响到各种任务的处理效率。例如,在进行计算密集型任务时,如大规模的机器学习(ML)项目、医疗影像分析或高端游戏,内存带宽的宽度会显著影响计算的生产力和任务的执行速度。内存带宽越大,GPU 能够更高效地传输和处理数据,从而提高整体计算性能和响应速度。
对于复杂的任务,如神经网络的训练和推断,一个拥有更宽内存带宽的 GPU 可以避免数据传输成为性能瓶颈。大规模的 ML 项目通常需要处理大量的权重和激活值,这些数据需要在计算内核和内存之间迅速传输。更高的内存带宽意味着 GPU 能够在并行处理时更有效地访问和利用数据,提升计算的吞吐量和效率。
此外,不同类型的应用对内存带宽的需求也有所不同。例如,图像和视频处理相关的机器学习项目(如图像识别、对象检测等)通常需要较高的内存带宽,因为这些任务涉及大量的视觉数据处理和高频率的数据传输。足够的内存带宽可以确保 GPU 能够高效地处理和存储大量的视觉数据,避免由于带宽不足而造成的数据传输延迟。
相比之下,涉及声音处理或自然语言处理(NLP)的任务通常对内存带宽的需求较低。这些工作负载通常涉及的数据量较小,因此可以在较低带宽的 GPU 上有效处理,而不会造成明显的性能瓶颈。尽管如此,足够的内存带宽仍然能够优化这些应用的处理效率和响应速度。
因此,毫无疑问地讲,内存带宽在 GPU 的性能表现中起着至关重要的作用。其宽度直接影响到数据传输的速度和计算的效率,尤其在处理高数据量和高计算需求的任务时尤为重要。选择适合的 GPU时,了解内存带宽的要求可以帮助确保计算资源的有效利用,并优化应用程序的整体性能。
Reference :
- [1] https://www.engineering.com/why-gpu-memory-matters-more-than-you-think/
- [2] https://www.microway.com/hpc-tech-tips/gpu-memory-types-performance-comparison/