前些天,OpenAI 发布了 ο1 系列模型,它那「超越博士水平的」强大推理性能预示着其必将在人们的生产生活中大有作为。但它的使用成本也很高,以至于 OpenAI 不得不限制每位用户的使用量:每位用户每周仅能给 o1-preview 发送 30 条消息,给 o1-mini 发送 50 条消息。
实在是少!
为了降低 LLM 的使用成本,研究者们已经想出了各式各样的方法。有些方法的目标是提升模型的效率,比如对模型进行量化或蒸馏,但这种方法往往也伴随着模型性能的下降。另一种思路则是提升运行这些模型的硬件——英伟达正是这一路线的推动者和受益者,但该公司的主要策略还是提升 GPU 的性能;另一些研究者则正在探索针对 AI 构建高效高性能的新型硬件体系。忆阻器(memristor)便是其中一个重要的研究方向。
忆阻器是一种电子元件,其能够限制或调节电路中电流的流动,并且可以记忆之前通过的电荷量。忆阻器在许多实际应用中具有重要意义,原因之一是其具备非易失性特性,即在断电情况下仍能保持记忆,这使得其在无电源或电源中断时依然能够持续使用。忆阻器被认为是和电阻器、电容器、电感同层级的基础电子元件。忆阻器的概念最早在 1971 年由华人科学家蔡少棠提出。
近日,Nature 发布了一篇来自印度科学学院、得克萨斯农工大学和爱尔兰利莫瑞克大学的一篇论文,其中提出了一种「线性对称的自选择式 14 bit 的动力学分子忆阻器」。

论文标题:Linear symmetric self-selecting 14-bit kinetic molecular memristors
论文地址:https://www.nature.com/articles/s41586-024-07902-2
该论文的核心亮点是,其中提出的分子忆阻器在核心的矩阵运算上能实现远超电子器件效率的 14 bit 模拟计算;并且其实现了超过 73 dB 的信噪比,比之前的最佳水平直接高出了 4 个数量级,同时其能耗量比电子计算机低 460 倍!
这样的出色表现让 AI 工程师 Rohan Paul 忍不住惊叹:「如果这是真的,算是到了 LLM 的真空管变硅晶体管时刻吗?」

那么,这篇论文究竟提出了什么呢?真的有希望将 LLM 从高功耗高成本的困境中解脱出来吗?让我们来简单了解一下。
挑战
我们知道,向量-矩阵乘法(VMM)是神经网络等许多计算算法的基础。但是,VMM 很难实现,因为对于长度为 n 的向量,所需的计算步骤为 n²。尽管对称运算可以降低 VMM 的复杂性,但它们只适用于特定的矩阵结构,比如人工智能中的非结构化数据。
为了得到高效的通用型 VMM 引擎,人们一直在推动硬件的发展,尤其是点积引擎(DPE)——一种可在单个时间步长内实现 VMM 的模拟加速器。尽管 DPE 有应对计算规模扩展的潜力,但其应用也受限于其精度,因为模拟电路元件仅提供 2-6 个等效比特。这种精度不足的根源在于其物理性质不够理想,包括非线性的权重更新、不对称行为、噪声、电导漂移和设备间差异。这是神经形态计算的一个根本性挑战。
为了解决这个问题,需要发明一种能嵌入到电路中的元件,并且嵌入数量要比目前可用的模拟级别高出几个数量级。
解决方案
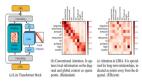
该团队宣称已经发明出了这样的元件。这是一种分子忆阻器交叉开关矩阵,可集成在电路板中。其展现出了 14 比特的模拟精度、近乎理想的线性和对称权重更新,以及每个电导层级的一步式可编程性(one-step programmability)。
如图 1a 所示,该团队构建了有史以来最大的分子忆阻器交叉开关矩阵(64×64)结构。使用的材料是夹在顶部和底部金电极之间的 60 nm 厚的  薄膜。更多详细的设计参数请参看原论文。
薄膜。更多详细的设计参数请参看原论文。

总之,该器件实现了想要的功能,并且具有相当好的非易失性和稳健性。如图 2a 所示,这个交叉开关矩阵耐久性很好,经过 10^9 个操作周期后,权重更新特性依旧保持不变。另外,图 2b 表明使用 500 mV 直流电压在 85°C 环境下,该结构能在 11 天内不出现明显的电导漂移。另外,他们还测试发现,其能维持长达 7 个月的电导保持率。

实验
使用这个 64×64 的分子交叉开关矩阵,该团队执行了 VMM 实验,这用到了一个他们定制的超过 16 比特准确度的混合信号外围电路,如下图 4 所示。a 图是对其编程,使之执行离散傅里叶变换(DFT)。b 图则比较了计算出的 DFT 输出与软件计算的结果,可以看到它们之间非常一致,这表明这个结构是有效的。

此外,他们还执行了矩阵-矩阵乘法运算,这是几乎所有 AI 和机器学习算法的基础运算。结果发现,如果让两个 64×64 的矩阵相乘,则该结构仅需要执行 64 步,但如果让电子计算机来干同样的事,则需要执行 262,144 次运算。
图 4c 表示其矩阵乘法的准确度不依赖于对称性,这是处理非结构化数据的一个关键属性。
该团队评估了不同矩阵组合,包括对称、随机和双随机矩阵。最终得到了 73-79 dB 的信噪比。该团队表示这是一个非常重大的进步。
他们还展示了一个非常有趣的用例。使用矩阵乘法,他们使用从韦伯望远镜数据库检索到的频域数据,通过逆傅里叶变换重建了标志性的「创生之柱」图像,见图 4d-f。
之所以选择外太空数据,是因为它缺乏对称性。这项任务每个平面都需要 26,256 个时间步骤,而数字计算机所需的步骤数超过了 10^8。
结果,他们得到的信噪比为 74 dB,峰值信噪比为 76.5 dB,直接高出了之前最佳的 DPE 4 个数量级。
这个转译过程的后续阶段将需要进一步扩展这个交叉开关矩阵,并开发具有高精度的片上外围电路。
该团队在论文中描述了一种经过功率优化的外围电路设计,可以提供超高的能效:每秒每瓦 4.1 万亿次运算 (TOPS/W) 。这个数据比 18 核 Haswell CPU 高 460 倍,比当前最高效的英伟达 K80 GPU 高 220 倍,并且这还有很大的改进空间。
这个示例展示了基于分子的技术的巨大潜力,通过将其集成到 CMOS 电路中,可以大幅超越最先进的加速器的性能。
如果 OpenAI 等未来开发的大模型也能运行在基于此类技术开发的硬件上,那 AI 的使用成本必定能下降很多。
更多研究细节、数据和代码请访问原论文。